|-转 python3.10.0+pyinstaller4.7打包,IndexError: tuple index out of range报错的解决方法
- 打算用打包一个自己写的小工具,但是打包过程中报错,进行不下去。报错如下: IndexError: tuple index out of range

- 在CSDN上搜索解决方法,都说是需要更新pyinstaller版本。我的打包环境如下:win10+python3.10.0+pyinstaller4.7 。
- 尝试了CSDN说的各种方法都解决不了。然后上看了下,pyinstaller4.7实际上已经支持了python3.10.0.
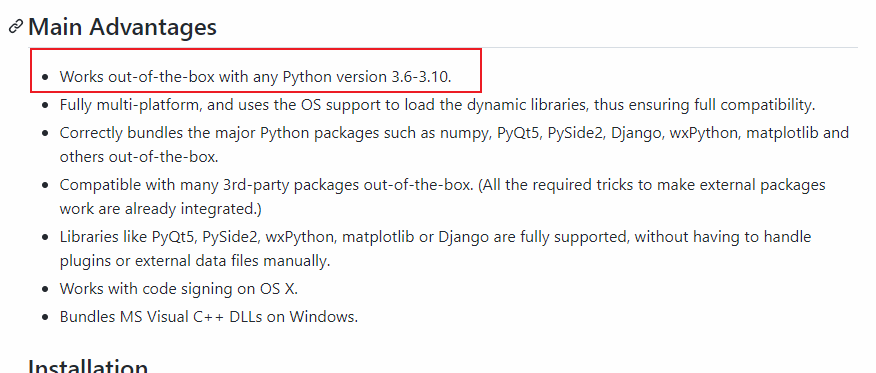
- 实在没办法,我都准备给python降级了。还好,翻了下讨论区,发现了一个方法,成功解决问题。
 找到 C:\Users\Admin\AppData\Local\Programs\Python\Python310\Lib\dis.py 文件,修改这个函数
找到 C:\Users\Admin\AppData\Local\Programs\Python\Python310\Lib\dis.py 文件,修改这个函数
def _unpack_opargs(code):
extended_arg = 0
for i in range(0, len(code), 2):
op = code[i]
if op >= HAVE_ARGUMENT:
arg = code[i+1] | extended_arg
extended_arg = (arg << 8) if op == EXTENDED_ARG else 0
else:
arg = None
extended_arg = 0
yield (i, op, arg)
5 . 然后就能正常打包了。 6. 很高兴问题顺利解决,在此记录一下,避免大家踩坑。如果帮你解决了问题,记得帮忙点个赞哦。...
6. 很高兴问题顺利解决,在此记录一下,避免大家踩坑。如果帮你解决了问题,记得帮忙点个赞哦。...
|-转 安装conda搭建python环境(保姆级教程)
目录
一、Anaconda简介
二、Anaconda安装
2.1 Anaconda下载
2.2 Anaconda安装
2.3 配置环境变量
三、通过conda配置python环境
3.1 创建并激活虚拟环境
3.2 管理虚拟环境
一、Anaconda简介
Anaconda 是专门为了方便使用 Python 进行数据科学研究而建立的一组软件包,涵盖了数据科学领域常见的 Python 库,并且自带了专门用来解决软件环境依赖问题的 conda 包管理系统。主要是提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
conda可以理解为一个工具,也是一个可执行命令,其核心功能是包管理与环境管理。包管理与pip的使用类似,环境管理则允许用户方便地安装不同版本的python并可以快速切换。
Anaconda则是一个打包的集合,里面预装好了conda、某个版本的python、众多packages、科学计算工具等等,所以也称为Python的一种发行版。其实还有Miniconda,它只包含最基本的内容——python与conda,以及相关的必须依赖项,对于空间要求严格的用户,Miniconda是一种选择。
conda将几乎所有的工具、第三方包都当做package对待,甚至包括python和conda自身!因此,conda打破了包管理与环境管理的约束,能非常方便地安装各种版本python、各种package并方便地切换。
二、Anaconda安装
2.1 Anaconda下载
这里推荐两种下载方式一是官网下载,二是镜像下载;官网下载太慢可选用镜像下载
1、下载地址:官网(https://www.anaconda.com/products/distribution)
选择对应版本,点击Download进行下载
2、镜像下载:开源镜像站(https://mirrors.bfsu.edu.cn/anaconda/archive/)
选择对应版本,点击Download进行下载
2.2 Anaconda安装
1、点击下载的文件进行安装,这是欢迎页面,点击下一步,即Next
2、点击I Agree,即同意Anaconda的协议,才能使用Anaconda
3、选择为所有用户授权
4、选择安装路径,在这里我选择安装在E:\ANACONDA地址下,选择Next,注意这里的安装路径需要记一下,后面配置环境变量时会用到
5、不选择添加环境变量
6、等待程序安装,安装完成后,点击Next
7、图片上有两个选项建议不选,点击“Finish”,完成软件安装
到这里程序安装部分结束
2.3 配置环境变量
将如如下路径添加到系统path,这里的路径为前面anaconda的安装路径,我的安装路径为E:\Anaconda,如果不同替换为自己的安装路径即可
E:\ANACONDA
E:\ANACONDA\Scripts
E:\ANACONDA\Library\mingw-w64\bin
E:\ANACONDA\Library\bin
具体环境变量的的配置步骤如下:...
|-转 error: Microsoft Visual C++ 14.0 or greater is required.
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
参考文章Microsoft Visual C++ 14.0下载方法_microsoft visual c++ 14.0 下载-CSDN博客
Visual C++ Build Tools for Visual Studio 2015 (with Update 3) 下载 ...
|-原 学习飞浆过程中遇到“缺少paddle.fluid”
建议学习飞浆python用3.6版本的,用这个不会报错 https://github.com/PaddlePaddle/PaddleNLP
https://github.com/PaddlePaddle/PaddleNLP
PaddleNLP是一款简单易用且功能强大的自然语言处理和大语言模型(LLM)开发库。聚合业界优质预训练模型并提供开箱即用的开发体验,覆盖NLP多场景的模型库搭配产业实践范例可满足开发者灵活定制的需求。...
|-转 没有使用asynccontextmanager ,但是报cannot import name 'asynccontextmanager'
没有使用asynccontextmanager ,但是报cannot import name 'asynccontextmanager' 可能的原因是python版本较低,python 3.6及以下版本不支持这个asynccontextmanager模块没有使用asynccontextmanager ,但是报cannot import name 'asynccontextmanager'没有使用a
|-转 [NLP实践01]simpletransformers安装和文本分类简单实现
卡在了conda install pytorch>=1.6 cudatoolkit=11.0 -c pytorch,运行代码一直不动
快速安装 simpletransformers
simpletransformers 项目地址:hub.fastgit.org/ThilinaRaja…
simpletransformers 文档地址:
simpletransformers.ai/
快速安装方式:
使用Conda安装
1)新建虚拟环境
conda create -n st python pandas tqdm
conda activate st
2)安装cuda环境
conda install pytorch>=1.6 cudatoolkit=11.0 -c pytorch
3)安装 simpletransformers
pip install simpletransformers
安装 wandb
wandb 用于在web浏览器中追踪和可视化Weights和Biases(wandb)
复制代码pip install wandb
目前支持的任务:
任务模型二元和多类文本分类ClassificationModel对话式人工智能(聊天机器人训练)ConvAIModel语言生成LanguageGenerationModel语言模型训练/微调LanguageModelingModel多标签文本分类MultiLabelClassificationModel多模态分类(文本和图像数据结合)MultiModalClassificationModel命名实体识别NERModel问答QuestionAnsweringModel回归ClassificationModel句子对分类ClassificationModel文本表示生成RepresentationModel
预训练模型去哪里下载?
有关预训练模型,请参阅Hugging Face 文档。
根据文档中给出的model_type,只要在args中正确设置model_name的字典值就是可以加载预训练模型
【实践01】文本分类
数据集
笔者选用CLUE的作为benchmark数据集
选取数据集:IFLYTEK' 长文本分类
中文语言理解测评基准(CLUE)
www.cluebenchmarks.com/dataSet_sea…
为更好的服务中文语言理解、任务和产业界,做为通用语言模型测评的补充,通过搜集整理发布中文任务及标准化测评等方式完善基础设施,最终促进中文NLP的发展。
Update: CLUE论文被计算语言学国际会议 COLING2020高分录用
IFLYTEK' 长文本分类
下载地址:github.com/CLUEbenchma…
该数据集共有1.7万多条关于app应用描述的长文本标注数据,包含和日常生活相关的各类应用主题,共119个类别:"打车":0,"地图导航":1,"免费WIFI":2,"租车":3,….,"女性":115,"经营":116,"收款":117,"其他":118(分别用0-118表示)。每一条数据有三个属性,从前往后分别是 类别ID,类别名称,文本内容。
数据量:训练集(12,133),验证集(2,599),测试集(2,600)
css复制代码{"label": "110",
"label_des": "社区超市",
"sentence": "朴朴快送超市创立于2016年,专注于打造移动端30分钟即时配送一站式购物平台,商品品类包含水果、蔬菜、肉禽蛋奶、海鲜水产、粮油调味、酒水饮料、休闲食品、日用品、外卖等。朴朴公司希望能以全新的商业模式,更高效快捷的仓储配送模式,致力于成为更快、更好、更多、更省的在线零售平台,带给消费者更好的消费体验,同时推动中国食品安全进程,成为一家让社会尊敬的互联网公司。,朴朴一下,又好又快,1.配送时间提示更加清晰友好2.保障用户隐私的一些优化3.其他提高使用体验的调整4.修复了一些已知bug"}
数据处理
Simple Transformers要求数据必须包含在至少两列的Pandas DataFrames中。 只需为列的文本和标签命名,SimpleTransformers就会处理数据。
第一列包含文本,类型为str。
第二列包含标签,类型为int。
对于多类分类,标签应该是从0开始的整数。
ini复制代码import json
import pandas as pd
def load_clue_iflytek(path,mode=None):
"""适应simpletransformer的加载方式"""
data = []
with open(path, "r", encoding="utf-8") as fp:
if mode == 'train' or mode =='dev':
for idx, line in enumerate(fp):
line = json.loads(line.strip())
label = int(line["label"])
text = line['sentence']
data.append([text, label])
data_df = pd.DataFrame(data, columns=["text", "labels"])
return data_df
elif mode == 'test':
for idx, line in enumerate(fp):
line = json.loads(line.strip())
text = line['sentence']
data.append([text])
data_df = pd.DataFrame(data, columns=["text"])
return data_df
模型搭建和训练
先进行参数配置,Simple Transformers具有dict args, 有关每个args的详细说明,可有参考:simpletransformers.ai/docs/tips-a…
1)参数配置
ini复制代码# 配置config
import argparse
def data_config(parser):
parser.add_argument("--trainset_path", type=str, default="data/Chinese_Spam_Message/train.json",
help="训练集路径")
parser.add_argument("--testset_path", type=str, default="data/Chinese_Spam_Message/test.txt",
help="测试集路径")...
|-转 primeqa 安装requirements时报错
Could not find a version that satisfies the requirement faiss-gpu~=1.7.2;
Collecting pytest-mock~=3.7.0 Downloading pytest_mock-3.7.0-py3-none-any.whl (12 kB) ERROR: Could not find a version that satisfies the requirement faiss-gpu~=1.7.2; extra == "all" (from primeqa[all]) (from versions: none) ERROR: No matching distribution found for faiss-gpu~=1.7.2; extra == "all" WARNING: You are using pip version 22.0.4; however, version 24.0 is available. You should consider upgrading via the 'D:\python\python3.10.4\python.exe -m pip install --upgrade pip' command.
20240405
|-转 sublime text下 Python 问题:TabError: inconsistent use of tabs and spaces in indentation,让sublime显示横线和点出来
"draw_white_space": "all" sublime text 会显示横线和点出来
File "G:\ST\Python\code.py", line 52
while left < right and (nums[left] == nums[left+1]):
^
TabError: inconsistent use of tabs and spaces in indentation
怎么都搞不定,原因是自己偷懒了,从LeetCode上面复制了头部,尾部是自己手写的,方案就是全部推倒,重来,全部手写。
class Solution:
def threeSum(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
网友方案,检查subline的空格制表显示就可以清楚的显示出自己是否真的空格了。
操作:...
