|-转 python3.10.0+pyinstaller4.7打包,IndexError: tuple index out of range报错的解决方法
- 打算用打包一个自己写的小工具,但是打包过程中报错,进行不下去。报错如下: IndexError: tuple index out of range

- 在CSDN上搜索解决方法,都说是需要更新pyinstaller版本。我的打包环境如下:win10+python3.10.0+pyinstaller4.7 。
- 尝试了CSDN说的各种方法都解决不了。然后上看了下,pyinstaller4.7实际上已经支持了python3.10.0.
- 实在没办法,我都准备给python降级了。还好,翻了下讨论区,发现了一个方法,成功解决问题。
 找到 C:\Users\Admin\AppData\Local\Programs\Python\Python310\Lib\dis.py 文件,修改这个函数
找到 C:\Users\Admin\AppData\Local\Programs\Python\Python310\Lib\dis.py 文件,修改这个函数
def _unpack_opargs(code):
extended_arg = 0
for i in range(0, len(code), 2):
op = code[i]
if op >= HAVE_ARGUMENT:
arg = code[i+1] | extended_arg
extended_arg = (arg << 8) if op == EXTENDED_ARG else 0
else:
arg = None
extended_arg = 0
yield (i, op, arg)
5 . 然后就能正常打包了。 6. 很高兴问题顺利解决,在此记录一下,避免大家踩坑。如果帮你解决了问题,记得帮忙点个赞哦。...
6. 很高兴问题顺利解决,在此记录一下,避免大家踩坑。如果帮你解决了问题,记得帮忙点个赞哦。...
|-转 解决无法加载UIAutomationCore.dll的报错
上述错误是在打包后的软件中出现,在PyCharm的运行过程中并没有出现。
解决办法,再项目源码里引入
from comtypes.gen.UIAutomationClient import IUIAutomation
前言: 此问题是在Python开发环境下关于UIAutomation的报错问题,问题来源于生产环境中的几台WIN10系统报错。
module 'comtypes.gen.UIAutomationClient' has no attribute 'IUIAutomation'Can not load UIAutomationCore.dll.1, You may need to install Windows Update KB971513 if your OS is Windows XP, see https://github.com/yinkaisheng/WindowsUpdateKB9715...2, you need to use an UIAutomationInitializerInThread object if use uiautomation in a thread, see demos/uiautomation_in_thread.py
因为在生产环境中出现,当时是怀疑是UIAutomationCore.dll在系统中没有生效,所以尝试过如下的方法(以管理员身份执行如下cmd命令),但始终没有效果,该报错还是报错;也怀疑过WIN10上缺少KB971513的补丁,为此还特地找过对应的补丁安装,但是该补丁只适用于Windows XP系统,在安装的时候存在类似“当前系统无法安装”的提示。
>cd C:\Windows\System32 >regsvr32 UIAutomationCore.dll
由于生产环境不联外网,不好远程调试。本地开发环境又复现不出该问题,
所以当时,虽然无奈地将原因归结于未知的系统原因,但只能先弃用有报错的几台WIN10系统,换别的系统进行业务操作。
直到现在,这个问题过去了有将近半年的时间,终于在开发环境上复现了!
初步定位,是在执行control = uiautomation.ControlFromPoint()的语句时出错,于是在此处捕获异常后打印堆栈信息如下:
Traceback (most recent call last):
File "test_hook.py", line 112, in get_mouse
File "uiautomation\uiautomation.py", line 8164, in ControlFromPoint
File "uiautomation\uiautomation.py", line 52, in instance
File "uiautomation\uiautomation.py", line 71, in __init__
File "uiautomation\uiautomation.py", line 60, in __init__
AttributeError: module 'comtypes.gen.UIAutomationClient' has no attribute 'IUIAutomation'
然后根据堆栈信息找到出错位置对应的uiautomation.py源码
class _AutomationClient:
_instance = None
@classmethod
def instance(cls) -> '_AutomationClient':
"""Singleton instance (this prevents com creation on import)."""
if cls._instance is None:
cls._instance = cls()
return cls._instance
def __init__(self):
tryCount = 3
for retry in range(tryCount):
try:
self.UIAutomationCore = comtypes.client.GetModule("UIAutomationCore.dll")
self.IUIAutomation = comtypes.client.CreateObject("{ff48dba4-60ef-4201-aa87-54103eef594e}", interface=self.UIAutomationCore.IUIAutomation)
self.ViewWalker = self.IUIAutomation.RawViewWalker
#self.ViewWalker = self.IUIAutomation.ControlViewWalker
break
except Exception as ex:
if retry + 1 == tryCount:
Logger.WriteLine('''
{}
Can not load UIAutomationCore.dll.
1, You may need to install Windows Update KB971513 if your OS is Windows XP, see https://github.com/yinkaisheng/WindowsUpdateKB9715......
|-转 AttributeError: module 'cv2.cv2' has no attribute 'cv'
AttributeError: module 'cv2.cv2' has no attribute 'cv'_module 'cv2' has no attribute 'cv-CSDN博客
最近看#《OpenCV 3 计算机视觉Python语言实现(原书第2版)》在运行网上下载的随书源代码的时候经常会有故障,查阅资料和相关网页发现,主要是因为OpenCV的版本问题导致的。此处以 4-TenSecondCameraCapture.py为例抛砖引玉给有需要的人一个示例,也给自己留一个笔记。 4-TenSecondCameraCapture书籍提供源代码如下:
import cv2
cameraCapture = cv2.VideoCapture(0)
fps = 30 # an assumption
size = (int(cameraCapture.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH)),
int(cameraCapture.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)))
videoWriter = cv2.VideoWriter(
MyOutputVid.avi, cv2.cv.CV_FOURCC(I,4,2,0), fps, size)
success, frame = cameraCapture.read()
numFramesRemaining = 10 * fps - 1
while success and numFramesRemaining > 0:
videoWriter.write(frame)
success, frame = cameraCapture.read()
numFramesRemaining -= 1 运行后的结果是: 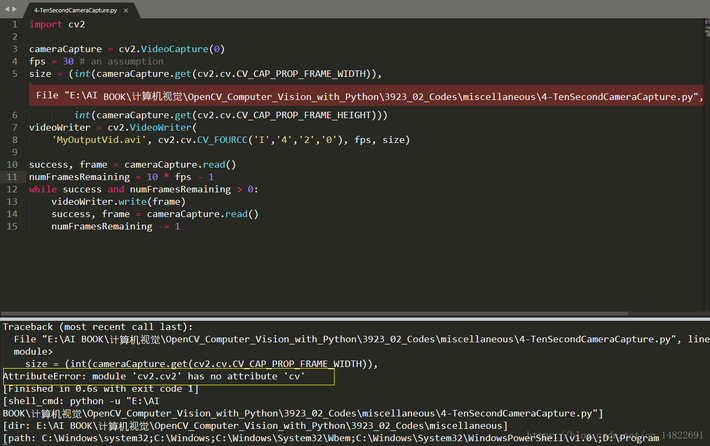 导致这个错误主要是因为下载的代码版本是CV2的版本,但是书上用的是CV3(对,书上的代码没问题)。同时如果你使用本书会发现还有很多类似的问题,在此不一一列举...
导致这个错误主要是因为下载的代码版本是CV2的版本,但是书上用的是CV3(对,书上的代码没问题)。同时如果你使用本书会发现还有很多类似的问题,在此不一一列举...
|-转 sublime text常用快捷键及多行列模式批量操作教程
sublime text多行光标批量快捷操作
Ctrl+ALT+↓按end定位到行尾
列模式
- 2Windows:-鼠标右键+Shift-或者鼠标中键-增加选择:Ctrl,减少选择:Alt
- 3Linux:-鼠标右键+Shift-增加选择:Ctrl,减少选择:Alt
sublime text多行光标批量快捷操作
Ctrl+ALT+↓按end定位到行尾
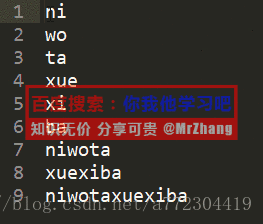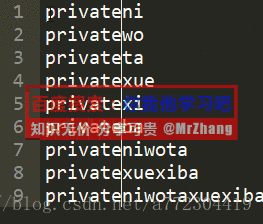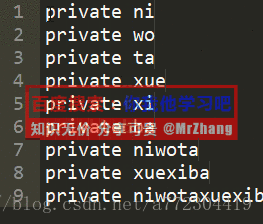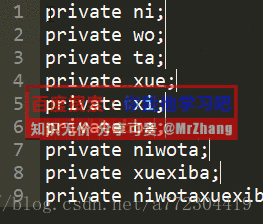
sublimetext常用快捷键
Ctrl+Shift+P:打开命令面板Ctrl+P:搜索项目中的文件Ctrl+G:跳转到第几行Ctrl+W:关闭当前打开文件Ctrl+Shift+W:关闭所有打开文件Ctrl+Shift+V:粘贴并格式化Ctrl+D:选择单词,重复可增加选择下一个相同的单词Ctrl+L:选择行,重复可依次增加选择下一行Ctrl+Shift+L:选择多行Ctrl+Shift+Enter:在当前行前插入新行Ctrl+X:删除当前行Ctrl+M:跳转到对应括号Ctrl+U:软撤销,撤销光标位置Ctrl+J:选择标签内容Ctrl+F:查找内容Ctrl+Shift+F:查找并替换Ctrl+H:替换Ctrl+R:前往 methodCtrl+N:新建窗口Ctrl+K+B:开关侧栏Ctrl+Shift+M:选中当前括号内容,重复可选着括号本身Ctrl+F2:设置/删除标记Ctrl+/:注释当前行Ctrl+Shift+/:当前位置插入注释Ctrl+Alt+/:块注释,并Focus到首行,写注释说明用的Ctrl+Shift+A:选择当前标签前后,修改标签用的F11:全屏Shift+F11:全屏免打扰模式,只编辑当前文件Alt+F3:选择所有相同的词Alt+.:闭合标签Alt+Shift+数字:分屏显示Alt+数字:切换打开第N个文件Shift+右键拖动:光标多不,用来更改或插入列内容鼠标的前进后退键可切换Tab文件按Ctrl,依次点击或选取,可需要编辑的多个位置按Ctrl+Shift+上下键,可替换行
选择类
Ctrl+D 选中光标所占的文本,继续操作则会选中下一个相同的文本。
Alt+F3 选中文本按下快捷键,即可一次性选择全部的相同文本进行同时编辑。举个栗子:快速选中并更改所有相同的变量名、函数名等。
Ctrl+L 选中整行,继续操作则继续选择下一行,效果和 Shift+↓ 效果一样。
Ctrl+Shift+L 先选中多行,再按下快捷键,会在每行行尾插入光标,即可同时编辑这些行。
Ctrl+Shift+M 选择括号内的内容(继续选择父括号)。举个栗子:快速选中删除函数中的代码,重写函数体代码或重写括号内里的内容。
Ctrl+M 光标移动至括号内结束或开始的位置。
Ctrl+Enter 在下一行插入新行。举个栗子:即使光标不在行尾,也能快速向下插入一行。
Ctrl+Shift+Enter 在上一行插入新行。举个栗子:即使光标不在行首,也能快速向上插入一行。
Ctrl+Shift+[ 选中代码,按下快捷键,折叠代码。
Ctrl+Shift+] 选中代码,按下快捷键,展开代码。
Ctrl+K+0 展开所有折叠代码。
Ctrl+← 向左单位性地移动光标,快速移动光标。
Ctrl+→ 向右单位性地移动光标,快速移动光标。
shift+↑ 向上选中多行。
shift+↓ 向下选中多行。
Shift+← 向左选中文本。
Shift+→ 向右选中文本。
Ctrl+Shift+← 向左单位性地选中文本。
Ctrl+Shift+→ 向右单位性地选中文本。
Ctrl+Shift+↑ 将光标所在行和上一行代码互换(将光标所在行插入到上一行之前)。
Ctrl+Shift+↓ 将光标所在行和下一行代码互换(将光标所在行插入到下一行之后)。
Ctrl+Alt+↑ 向上添加多行光标,可同时编辑多行。
Ctrl+Alt+↓ 向下添加多行光标,可同时编辑多行。
编辑类
Ctrl+J 合并选中的多行代码为一行。举个栗子:将多行格式的CSS属性合并为一行。
Ctrl+Shift+D 复制光标所在整行,插入到下一行。
Tab 向右缩进。
Shift+Tab 向左缩进。
Ctrl+K+K 从光标处开始删除代码至行尾。
Ctrl+Shift+K 删除整行。
Ctrl+/ 注释单行。
Ctrl+Shift+/ 注释多行。
Ctrl+K+U 转换大写。
Ctrl+K+L 转换小写。
Ctrl+Z 撤销。
Ctrl+Y 恢复撤销。
Ctrl+U 软撤销,感觉和 Gtrl+Z 一样。
Ctrl+F2 设置书签
Ctrl+T 左右字母互换。
F6 单词检测拼写
搜索类
Ctrl+F 打开底部搜索框,查找关键字。
Ctrl+shift+F 在文件夹内查找,与普通编辑器不同的地方是sublime允许添加多个文件夹进行查找,略高端,未研究。
Ctrl+P打开搜索框。举个栗子:1、输入当前项目中的文件名,快速搜索文件,2、输入@和关键字,查找文件中函数名,3、输入:和数字,跳转到文件中该行代码,4、输入#和关键字,查找变量名。
Ctrl+G 打开搜索框,自动带:,输入数字跳转到该行代码。举个栗子:在页面代码比较长的文件中快速定位。
Ctrl+R 打开搜索框,自动带@,输入关键字,查找文件中的函数名。举个栗子:在函数较多的页面快速查找某个函数。
Ctrl+: 打开搜索框,自动带#,输入关键字,查找文件中的变量名、属性名等。
Ctrl+Shift+P 打开命令框。场景栗子:打开命名框,输入关键字,调用sublimetext或插件的功能,例如使用package安装插件。
Esc 退出光标多行选择,退出搜索框,命令框等。
显示类...
|-转 python配置opencv环境后,读取图片,报错:can‘t open/read file: check file path/integrity
python配置opencv环境后,读取图片,报错:can‘t open/read file: check file path/integrity_cant open read file-CSDN博客
运行出错代码:
import cv2
import numpy as np
image = cv2.imread(C:/Pictures/桌面背景图片切换/wallhaven-6oq1k7.jpg, cv2.IMREAD_COLOR)
cv2.imshow("test", image)
cv2.waitKey(0)
报错内容:
[ WARN:0@0.007] global D:\a\opencv-python\opencv-python\opencv\modules\imgcodecs\src\loadsave.cpp (239) cv::findDecoder imread_(C:/Pictures/桌面背景图片切换/wallhaven-6oq1k7.jpg): **cant open/read file: check file path/integrity**
Traceback (most recent call last):
File "D:/Code/DeepLearning/test/main.py", line 13, in <module>
cv2.imshow("test", image)
cv2.error: OpenCV(4.6.0) D:\a\opencv-python\opencv-python\opencv\modules\highgui\src\window.cpp:967: error: (-215:Assertion failed) size.width>0 && size.height>0 in function cv::imshow
Process finished with exit code 1
报错原因:路径中出现中文字符 解决办法: 1.修改路径 2.修改代码,修改后代码如下:...
|-转 安装conda搭建python环境(保姆级教程)
目录
一、Anaconda简介
二、Anaconda安装
2.1 Anaconda下载
2.2 Anaconda安装
2.3 配置环境变量
三、通过conda配置python环境
3.1 创建并激活虚拟环境
3.2 管理虚拟环境
一、Anaconda简介
Anaconda 是专门为了方便使用 Python 进行数据科学研究而建立的一组软件包,涵盖了数据科学领域常见的 Python 库,并且自带了专门用来解决软件环境依赖问题的 conda 包管理系统。主要是提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
conda可以理解为一个工具,也是一个可执行命令,其核心功能是包管理与环境管理。包管理与pip的使用类似,环境管理则允许用户方便地安装不同版本的python并可以快速切换。
Anaconda则是一个打包的集合,里面预装好了conda、某个版本的python、众多packages、科学计算工具等等,所以也称为Python的一种发行版。其实还有Miniconda,它只包含最基本的内容——python与conda,以及相关的必须依赖项,对于空间要求严格的用户,Miniconda是一种选择。
conda将几乎所有的工具、第三方包都当做package对待,甚至包括python和conda自身!因此,conda打破了包管理与环境管理的约束,能非常方便地安装各种版本python、各种package并方便地切换。
二、Anaconda安装
2.1 Anaconda下载
这里推荐两种下载方式一是官网下载,二是镜像下载;官网下载太慢可选用镜像下载
1、下载地址:官网(https://www.anaconda.com/products/distribution)
选择对应版本,点击Download进行下载
2、镜像下载:开源镜像站(https://mirrors.bfsu.edu.cn/anaconda/archive/)
选择对应版本,点击Download进行下载
2.2 Anaconda安装
1、点击下载的文件进行安装,这是欢迎页面,点击下一步,即Next
2、点击I Agree,即同意Anaconda的协议,才能使用Anaconda
3、选择为所有用户授权
4、选择安装路径,在这里我选择安装在E:\ANACONDA地址下,选择Next,注意这里的安装路径需要记一下,后面配置环境变量时会用到
5、不选择添加环境变量
6、等待程序安装,安装完成后,点击Next
7、图片上有两个选项建议不选,点击“Finish”,完成软件安装
到这里程序安装部分结束
2.3 配置环境变量
将如如下路径添加到系统path,这里的路径为前面anaconda的安装路径,我的安装路径为E:\Anaconda,如果不同替换为自己的安装路径即可
E:\ANACONDA
E:\ANACONDA\Scripts
E:\ANACONDA\Library\mingw-w64\bin
E:\ANACONDA\Library\bin
具体环境变量的的配置步骤如下:...
|-转 汉字目标点选识别-ddddocr(返回识别的内容和位置)
实测有效 ,中文有时会识别认为是英文,除非加载训练好的模型数据否则识别的准确率一般
汉字目标点选识别-ddddocr_ddddocr官方文档-CSDN博客
目录
一、ddddocr介绍
- ddddocr 新的目标检测识别 1.3功能
- 安装 pip install ddddocr
- star哲哥免费开源的识别项目https://github.com/sml2h3/ddddocr
二、识别效果


三、代码
- 图片demo

- 代码 ,更多详细介绍看ddddocr 新的目标检测识别 1.3功能
"""
@author:十一姐
@desc: ddddocr目标识别
@time: 2022/01/09
"""
from io import BytesIO
import ddddocr
from PIL import Image, ImageDraw, ImageFont
import sys
import json
class Ddddocr:
def __init__(self):
self.ocr = ddddocr.DdddOcr(show_ad=False)
self.xy_ocr = ddddocr.DdddOcr(det=True, show_ad=False)
def ddddocr_identify(self, captcha_bytes):
return self.ocr.classification(captcha_bytes)
def draw_img(self, content, xy_list):
"""画出图片"""
# 填字字体
font_type = "./msyhl.ttc"
font_size = 20
font = ImageFont.truetype(font_type, font_size)
# 识别
img = Image.open(BytesIO(content))
draw = ImageDraw.Draw(img)
words = []
for row in xy_list:
# 框字
x1, y1, x2, y2 = row
draw.line(([(x1, y1), (x1, y2), (x2, y2), (x2, y1), (x1, y1)]), width=1, fill="red")
# 裁剪出单个字
corp = img.crop(row)
img_byte = BytesIO()
corp.save(img_byte, png)
# 识别出单个字
word = self.ocr.classification(img_byte.getvalue())
words.append(word)
# 填字
y = y1 - 30 if y2 > 300 else y2
draw.text((int((x1 + x2)/2), y), word, font=font, fill="red")
img.show()
return words
def ddddocr_clcik_identify(self, content, crop_size=None):
"""目标检测识别"""
img = Image.open(BytesIO(content))
# print(img.size)
if crop_size:
img = img.crop(crop_size)
img_byte = BytesIO()
img.save(img_byte, png)
content = img_byte.getvalue()
xy_list = self.xy_ocr.detection(content)
words = self.draw_img(content, xy_list)
return dict(zip(words, xy_list))
def case_demo(self, con):
"""点选识别结果"""
click_identify_result = self.ddddocr_clcik_identify(con, (0, 0, 344, 344))
img = Image.open(BytesIO(con))
img = img.crop((0, 344, 344, 384))
img_byte = BytesIO()
img.save(img_byte, png)
# identify_words = self.ocr.classification(img_byte.getvalue())
# print(click_identify_result)
# words_dict = {}
# for word in identify_words:
# words_dict[word] = click_identify_result.get(word)
# print(words_dict)
img_xy = {}
for key, xy in click_identify_result.items():
img_xy[key] = (int((xy[0] + xy[2]) / 2), int((xy[1] + xy[3]) / 2))
# print(img_xy)
j = json.dumps(img_xy)# dict字典格式 转 json 20241005
print(j)
with open(r./8320423853e84b499be0b81d40c7f259.jpg, rb) as f:
con1 = f.read()
Ddddocr().case_demo(con1)
...
|-转 error: Microsoft Visual C++ 14.0 or greater is required.
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
参考文章Microsoft Visual C++ 14.0下载方法_microsoft visual c++ 14.0 下载-CSDN博客
Visual C++ Build Tools for Visual Studio 2015 (with Update 3) 下载 ...
|-原 学习飞浆过程中遇到“缺少paddle.fluid”
建议学习飞浆python用3.6版本的,用这个不会报错
https://github.com/PaddlePaddle/PaddleNLP
https://github.com/PaddlePaddle/PaddleNLP
PaddleNLP是一款简单易用且功能强大的自然语言处理和大语言模型(LLM)开发库。聚合业界优质预训练模型并提供开箱即用的开发体验,覆盖NLP多场景的模型库搭配产业实践范例可满足开发者灵活定制的需求。...
|-转 没有使用asynccontextmanager ,但是报cannot import name 'asynccontextmanager'
没有使用asynccontextmanager ,但是报cannot import name 'asynccontextmanager'没有使用a没有使用asynccontextmanager ,但是报cannot import name 'asynccontextmanager'
可能的原因是python版本较低,python 3.6及以下版本不支持这个asynccontextmanager模块
|-转 [NLP实践01]simpletransformers安装和文本分类简单实现
卡在了conda install pytorch>=1.6 cudatoolkit=11.0 -c pytorch,运行代码一直不动
快速安装 simpletransformers
simpletransformers 项目地址:hub.fastgit.org/ThilinaRaja…
simpletransformers 文档地址:
simpletransformers.ai/
快速安装方式:
使用Conda安装
1)新建虚拟环境
conda create -n st python pandas tqdm
conda activate st
2)安装cuda环境
conda install pytorch>=1.6 cudatoolkit=11.0 -c pytorch
3)安装 simpletransformers
pip install simpletransformers
安装 wandb
wandb 用于在web浏览器中追踪和可视化Weights和Biases(wandb)
复制代码pip install wandb
目前支持的任务:
任务模型二元和多类文本分类ClassificationModel对话式人工智能(聊天机器人训练)ConvAIModel语言生成LanguageGenerationModel语言模型训练/微调LanguageModelingModel多标签文本分类MultiLabelClassificationModel多模态分类(文本和图像数据结合)MultiModalClassificationModel命名实体识别NERModel问答QuestionAnsweringModel回归ClassificationModel句子对分类ClassificationModel文本表示生成RepresentationModel
预训练模型去哪里下载?
有关预训练模型,请参阅Hugging Face 文档。
根据文档中给出的model_type,只要在args中正确设置model_name的字典值就是可以加载预训练模型
【实践01】文本分类
数据集
笔者选用CLUE的作为benchmark数据集
选取数据集:IF***TEK' 长文本分类
中文语言理解测评基准(CLUE)
www.cluebenchmarks.com/dataSet_sea…
为更好的服务中文语言理解、任务和产业界,做为通用语言模型测评的补充,通过搜集整理发布中文任务及标准化测评等方式完善基础设施,最终促进中文NLP的发展。
Update: CLUE论文被计算语言学国际会议 COLING2020高分录用
IF***TEK' 长文本分类
下载地址:github.com/CLUEbenchma…
该数据集共有1.7万多条关于app应用描述的长文本标注数据,包含和日常生活相关的各类应用主题,共119个类别:"打车":0,"地图导航":1,"免费WIFI":2,"租车":3,….,"女性":115,"经营":116,"收款":117,"其他":118(分别用0-118表示)。每一条数据有三个属性,从前往后分别是 类别ID,类别名称,文本内容。
数据量:训练集(12,133),验证集(2,599),测试集(2,600)
css复制代码{"label": "110",
"label_des": "社区超市",
"sentence": "朴朴快送超市创立于2016年,专注于打造移动端30分钟即时配送一站式购物平台,商品品类包含水果、蔬菜、肉禽蛋奶、海鲜水产、粮油调味、酒水饮料、休闲食品、日用品、外卖等。朴朴公司希望能以全新的商业模式,更高效快捷的仓储配送模式,致力于成为更快、更好、更多、更省的在线零售平台,带给消费者更好的消费体验,同时推动中国食品安全进程,成为一家让社会尊敬的互联网公司。,朴朴一下,又好又快,1.配送时间提示更加清晰友好2.保障用户隐私的一些优化3.其他提高使用体验的调整4.修复了一些已知bug"}
数据处理
Simple Transformers要求数据必须包含在至少两列的Pandas DataFrames中。 只需为列的文本和标签命名,SimpleTransformers就会处理数据。
第一列包含文本,类型为str。
第二列包含标签,类型为int。
对于多类分类,标签应该是从0开始的整数。
ini复制代码import json
import pandas as pd
def load_clue_iflytek(path,mode=None):
"""适应simpletransformer的加载方式"""
data = []
with open(path, "r", encoding="utf-8") as fp:
if mode == 'train' or mode =='dev':
for idx, line in enumerate(fp):
line = json.loads(line.strip())
label = int(line["label"])
text = line['sentence']
data.append([text, label])
data_df = pd.DataFrame(data, columns=["text", "labels"])
return data_df
elif mode == 'test':
for idx, line in enumerate(fp):
line = json.loads(line.strip())
text = line['sentence']
data.append([text])
data_df = pd.DataFrame(data, columns=["text"])
return data_df
模型搭建和训练
先进行参数配置,Simple Transformers具有dict args, 有关每个args的详细说明,可有参考:simpletransformers.ai/docs/tips-a…
1)参数配置
ini复制代码# 配置config
import argparse
def data_config(parser):
parser.add_argument("--trainset_path", type=str, default="data/Chinese_Spam_Message/train.json",
help="训练集路径")
parser.add_argument("--testset_path", type=str, default="data/Chinese_Spam_Message/test.txt",
help="测试集路径")...
|-转 primeqa 安装requirements时报错
Could not find a version that satisfies the requirement faiss-gpu~=1.7.2;
Collecting pytest-mock~=3.7.0 Downloading pytest_mock-3.7.0-py3-none-any.whl (12 kB) ERROR: Could not find a version that satisfies the requirement faiss-gpu~=1.7.2; extra == "all" (from primeqa[all]) (from versions: none) ERROR: No matching distribution found for faiss-gpu~=1.7.2; extra == "all" WARNING: You are using pip version 22.0.4; however, version 24.0 is available. You should consider upgrading via the 'D:\python\python3.10.4\python.exe -m pip install --upgrade pip' command.
20240405
|-转 sublime text下 Python 问题:TabError: inconsistent use of tabs and spaces in indentation,让sublime显示横线和点出来
"draw_white_space": "all"
sublime text 会显示横线和点出来
File "G:\ST\Python\code.py", line 52
while left < right and (nums[left] == nums[left+1]):
^
TabError: inconsistent use of tabs and spaces in indentation
怎么都搞不定,原因是自己偷懒了,从LeetCode上面复制了头部,尾部是自己手写的,方案就是全部推倒,重来,全部手写。
class Solution:
def threeSum(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
网友方案,检查subline的空格制表显示就可以清楚的显示出自己是否真的空格了。
操作:...
|-原 uiautomation报错 No module named 'comtypes.stream' Can not load UIAutomationCore.dll.
No module named 'comtypes.stream' Can not load UIAutomationCore.dll.
1, You may need to install Windows Update KB971513 if your OS is Windows XP, see ...
|-转 opencv报错及解决:AttributeError: module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
更新opencv版本后运行代码报错,报错内容如下
File "E:/code/***.py", line 9, in <module> import cv2 File "D:\Program Files (x86)\Anaconda3\envs\y\lib\site-packages\cv2\__init__.py", line 181, in <module> bootstrap() File "D:\Program Files (x86)\Anaconda3\envs\y\lib\site-packages\cv2\__init__.py", line 175, in bootstrap if __load_extra_py_code_for_module("cv2", submodule, DEBUG): File "D:\Program Files (x86)\Anaconda3\envs\y\lib\site-packages\cv2\__init__.py", line 28, in __load_extra_py_code_for_module py_module = importlib.import_module(module_name) File "D:\Program Files (x86)\Anaconda3\envs\y\lib\importlib\__init__.py", line 127, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "D:\Program Files (x86)\Anaconda3\envs\y\lib\site-packages\cv2\gapi\__init__.py", line 301, in <module> cv.gapi.wip.GStreamerPipeline = cv.gapi_wip_gst_GStreamerPipeline AttributeError: module cv2 has no attribute gapi_wip_gst_GStreamerPipeline
解决方案
第一步:查看所有安装的opencv
conda list | findstr opencv
查看显示结果
opencv-python 4.8.1.78 pypi_0 pypi opencv-python-headless 4.5.2.52 pypi_0 pypi
可以看到有两个版本的opencv-python,一个opencv-python和一个无头的opencv-python(opencv-python-headless)这两个opencv之间会有冲突,可能会造成上述报错。
第二步:先卸载opencv-python
pip uninstall opencv-python
第三步:查看环境中是否可以调用cv2
python
import cv2
若无报错,则可以间接表明opencv-python和opencv-python-headless之间存在冲突。...
|-转 各种服务器通用搭建python训练模型用的环境,以训练SoloSpeech为列子
sed -i 's/\r$//' /mnt/workspace/setup_train_env.sh
chmod +x /mnt/workspace/setup_train_env.sh...
