
如何用Python爬数据?(一)网页抓取
Python爬虫练手,一个简单的Python资讯采集案例
python爬虫数据采集(文中代码不完整,转载来是提供一个采集思路)

Python 使用selenium报错:'chromedriver' executable needs to be in PATH
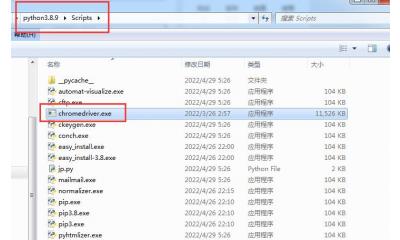
2022年可用的Python简单又好用的采集代码(2022年4月)
运行版本是Python3.8.9,操作系统Win7 查看更多
推荐内容
- 分享几个好用的bt搜索bt资源下载网址网站
- 全网最新bt磁力搜索引擎bt资源bt网站网址分享
- 怎样使用V2Ray代理和SSTap玩如魔兽世界/绝地求生/LOL台服/战地3/黑色沙漠/彩虹六号等外服游戏?
- 影视电影剧集动漫综艺bt资源在线播放网址网站推荐分享
- 使用V2Ray的mKCP协议加速游戏
- v2rayN已停止工作
- 【车险课堂】什么是无赔款优待系数ncd,你“造”吗?
- vultr服务器丢包很严重
- 我喜欢的游戏
- 真枪实弹,假戏真做,12部具有“实干精神”的电影!
- 在安装imagick时到安装yum install -y php-pear 报错 - Linux yum安装
- Wireguard+udpspeeder+udp2raw游戏加速方案改进版-实测有效
- 解决'nmake' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
- 韩国电影《新世界》里的背景音乐
- Yii2生成sitemap,yii2-sitemap-module Yii2 module for automatically generating XML Sitemap
- 2021年安装Android Studio心得
- 如何顺便在自己的VPS上搭个游戏加速器(拯救高ping战士:自建游戏加速器教程)
- Vultr IP被封怎么办?教你Vultr被墙的解决方案
- sstap游戏代理教程 从此玩如魔兽世界/绝地求生/LOL台服/战地3/黑色沙漠/彩虹六号等外服游戏加速不求人...
- wireguard+udpspeeder+udp2raw多用户配置
- 切换使用锐速和BBR加速时遇到的问题failed to dial to (wss:// *** ) 502 Bad Gateway
- 内网用UcStar聊天记录文件存放路径
- Android相关
- 电销三期打印要安装PageOn的问题
- 智商-百度百科
- 魔兽世界[可恶只能当伸手党了] 求个密语组人宏。。。。
- 中国血型人群的分布解说,有图有真相
- 有23对染色体的动物除了人还有其他吗?
- 刚买的justmysocks可以申请退款吗?
- 魔兽世界俄罗斯服uwow.biz的x100-7.3.5 服务器网络状况
- 网站(WebApp程序)打包成手机App的APK文件方法,网站生成app的方法
- 《EVE》国服正式宣布停运,2018年9月30日关闭服务器!网友好评
- 基于CentOS7 Centos8平台搭建邮件服务器
- 柏拉图-百度百科
- 使用WireGuard快速轻松地VPN
- 介绍几个国外支持Alipay(支付宝)付款的VPS或云主机
- Mysql用特殊字符设置密码遇到的问题
- 这群东南亚猛男,用最骚的尬舞征服了全世界
- 易语言-百度百科
- 重装系统出现error16:inconsistent filesy解决方法
- CentOS7下安装ImageMagick和PHP Imagick扩展
- 朝鲜是中国的国土吗?
- 安·兰德-百度百科
- mysql查找字符串出现位置
- 后来发现这个站的主站是https://uwow.biz/
- win7下Appserv或Xampp安装imagemagick以及php的imagick扩展教程并生成GIF缩略图(2018年版)
- Yii2 数据操作DAO
- IE如何取消阻止跨站脚本
- 为使用Gifsicle而安装VS2010,并用gifsicle处理压缩GIF图片
- 验证谷歌站长平台 – GOOGLE SEARCH CONSOLE 验证流程
- 魔兽世界私服uwow游戏指引
- 打不开Godaddy.com网站和域名无法解析的解决方法
- WEB技术之后端技术
- 《芳华》这样露大腿合适吗?
- UDPSpeeder+Udp2raw使用教程,并配合SSTap加速优化网络游戏
- 运行php composer.phar require --prefer-dist yiisoft/yii2-sphinx
- 如何在 CentOS 8 上安装和配置 Postfix 邮件服务器
- android studio 模拟器的安装及运行app程序(invalid resource directory name)
- Windows下查看mysql是否启动
- background-image在手机端表现的不太好,加载慢,一片一片的渲染 - CSS知识记录
- socks-百度百科
- net::ERR_CLEARTEXT_NOT_PERMITTED Android9.0无法加载url
- Yii2用composer安装kartik-v/yii2-mpdf时报错,成功解决后,再让其支持中文。
- centos7安装openssl
- Mysql server has gone away 报错原因分析及解决办法
- Yii2数据库报错-SQLSTATE[HY093]: Invalid parameter number: no parameters were bound
- mysql 警告 could not be resolved: Name or service not known
- Android studio出现Error:failed to find target android-19或android-26等等。
- 4K对齐选8,2048和4098扇区数有多大区别?实测告诉你
- 百度百科-浪漫主义 (文艺基本创作方法之一)
- 2010年后的国产电影,看来除了《让子弹飞》其他都可以带过了?
- Linux服务器搭建
- 乌克兰人真的那么懒散且美女那么多吗?
- Yii2的action不支持大小写吗?其实是支持的
- js 判断字符串中是否包含某个字符串
- 如何在RHEL8 / CentOS8上安装Webmin
- Socat一键安装脚本,可转发TCP和UDP流量
- 二叉查找树、平衡二叉树、红黑树、B-/B+树性能对比
- Yii2的ActiveForm的autofocus和火狐浏览器的兼容问题-WEB技术之前端技术
- WEB应用转手机APP,手机APP制作平台推荐
- 富文本编辑器Redactor在Yii2中的应用
- 确保文本在webfont加载期间保持可见
- Yii2用composer更新时遇到的错误
- 看英雄联盟比赛和选手数据的一个网站-玩家电竞
- 魔兽世界-帮助:如何修改游戏里的语言设置,游戏文本与语音语言
- Centos7用默认的防火墙firewall安装PPTP搭建vpn服务器
- jquery $.post() 在个别浏览器比如小米自带的浏览器遇到的问题
- 采集时报错cURL error 60: SSL certificate problem
- php反射获取自定义类的源码
- 大陆电影《霸王别姬》到底如何?
- 关于Linux下用户权限问题-WEB技术之后端技术
- php yii2 出现mysql-gone-away-2006解决
- 魔兽世界酒仙武僧的一键宏
- Yii2模型简介-块赋值
- 使用Laravel 5.4问题总结 Lost connection to MySQL server at 'reading initial communication...
- Yii2模型简介-属性
- colorAccent,colorPrimary,colorPrimaryDark等含义
- WEB技术之前端技术
- Yii2模块学习
- getimagesize 函数的使用-中文文件名问题-getimagesize 函数不是完全可靠的