|-原 python安装以及python采集(2022年4月更新)
Win7能用的最新版本是python3.8.9
安装python
1. 在python的官网下载python对应版本:https://www.python.org/downloads/windows/
64位下载Windows x86-64 executable installer 版本
32位下载Windows x86 executable installer 版本
打开链接如下图,版本会一直更新,选择任意一个适合自己电脑的版本就好
详细的安装教程点这里:Python安装教程(非常详细) python如何安装使用
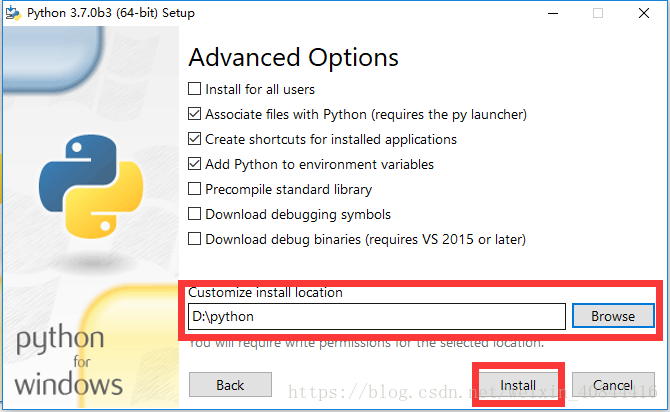
下载后安装,安装时注意到这步时,选择自己的安装目录,另外Add python to environment variables(添加环境变量)
 ...
...
|--摘 2022年可用的Python简单又好用的采集代码(2022年4月)
运行版本是Python3.8.9,操作系统Win7
网上找的代码,很多已经过了时效了,自己整理了,找了网上别人写的代码,实测后修改完善了下
# author : sunzd
# date : 2019/3/22
# position: chengdu
from fake_useragent import UserAgent
from urllib import request
from urllib import error
import pymysql
import re
import sys
import time
class HtmlDownloader(object):
def downloader(self, url):
if url is None:
print("downloader: Url is None")
return None
# 设置用户代理
# headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'}
# 使用伪代理fake UserAgent进行访问
#禁用服务器缓存
ua = UserAgent(use_cache_server=False)
#不缓存数据,这里如果选择不缓存,程序可能报错,所以注释掉
# ua = UserAgent(cache=False)
#忽略ssl验证
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': str(ua.random)}
# print(url)
req = request.Request(url, headers=headers)
try:
html = request.urlopen(req).read()
except error.URLError as e:
print("download error:", e.reason)
html = None
return html
url="https://movie.douban.com/subject/1889243/"
get = HtmlDownloader()
html=get.downloader(url)
if html!=None:
content = html.decode()
else :
content = ''
print(content)
正在学Python(PHP熟的话,上手快),后面还会分享些Python代码,O(∩_∩)O ...
|--转 如何用Python爬数据?(一)网页抓取
这篇文章赞有900多,后面的回复也挺多,先整来,O(∩_∩)O哈哈~
你期待已久的Python网络数据爬虫教程来了。本文为你演示如何从网页里找到感兴趣的链接和说明文字,抓取并存储到Excel。

需求
我在公众号后台,经常可以收到读者的留言。
很多留言,是读者的疑问。只要有时间,我都会抽空尝试解答。
但是有的留言,乍看起来就不明所以了。
例如下面这个:

一分钟后,他可能觉得不妥(大概因为想起来,我用简体字写文章),于是又用简体发了一遍。

我恍然大悟。
这位读者以为我的公众号设置了关键词推送对应文章功能。所以看了我的其他数据科学教程后,想看“爬虫”专题。
不好意思,当时我还没有写爬虫文章。
而且,我的公众号暂时也没有设置这种关键词推送。
主要是因为我懒。
这样的消息接收得多了,我也能体察到读者的需求。不止一个读者表达出对爬虫教程的兴趣。
之前提过,目前主流而合法的网络数据收集方法,主要分为3类:
- 开放数据集下载;
- API读取;
- 爬虫。
前两种方法,我都已经做过一些介绍,这次说说爬虫。

概念
许多读者对爬虫的定义,有些混淆。咱们有必要辨析一下。
维基百科是这么说的:
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
这问题就来了,你又不打算做搜索引擎,为什么对网络爬虫那么热心呢?
其实,许多人口中所说的爬虫(web crawler),跟另外一种功能“网页抓取”(web scraping)搞混了。
维基百科上,对于后者这样解释:
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
看到没有,即便你用浏览器手动拷贝数据下来,也叫做网页抓取(web scraping)。是不是立刻觉得自己强大了很多?
但是,这定义还没完:
While web scraping can be done manually by a software user, the term typically refers to automate processes implemented using a bot or web crawler.
也就是说,用爬虫(或者机器人)自动替你完成网页抓取工作,才是你真正想要的。
数据抓下来干什么呢?
一般是先存储起来,放到数据库或者电子表格中,以备检索或者进一步分析使用。
所以,你真正想要的功能是这样的:
找到链接,获得Web页面,抓取指定信息,存储。
这个过程有可能会往复循环,甚至是滚雪球。
你希望用自动化的方式来完成它。
了解了这一点,你就不要老盯着爬虫不放了。爬虫研制出来,其实是为了给搜索引擎编制索引数据库使用的。你为了抓取点儿数据拿来使用,已经是大炮轰蚊子了。
要真正掌握爬虫,你需要具备不少基础知识。例如HTML, CSS, Javascript, 数据结构……
这也是为什么我一直犹豫着没有写爬虫教程的原因。
不过这两天,看到王烁主编的一段话,很有启发:
我喜欢讲一个另类二八定律,就是付出两成努力,了解一件事的八成。
既然我们的目标很明确,就是要从网页抓取数据。那么你需要掌握的最重要能力,是拿到一个网页链接后,如何从中快捷有效地抓取自己想要的信息。...
|--转 完美解决Mac平台下Python3环境import bencode模块的报错(2022年5月实测有效)
2022年5月实测有效
在Mac平台下(其它平台没测),即使你使用pip3 install bencode来安装bencode模块,安装后的bencode模块仍然不兼容python3(mac平台)。
因此,本文将对bencode模块稍作改动,使其可以在Mac平台下的python3环境中完美运行。
报错1: ModuleNotFoundError: No module named 'BTL'
通过pip3 install bencode之后,在py文件内通过import bencode时,会发生以下错误:
>>> import bencode
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.7/site-packages/bencode/__init__.py", line 13, in <module>
from BTL import BTFailure
ModuleNotFoundError: No module named 'BTL'
报错1:错误分析
通过上述错误信息,我们可以找到bencode模块的路径:/usr/local/lib/python3.7/site-packages/bencode/__init__.py,打开/usr/local/lib/python3.7/site-packages/bencode/目录,发现结构如下:

这么大的BTL.py,我都看到了,你找不到?你怕是个zz。
吐槽完毕,开始寻找背后原因,百度无果,谷歌无果,stackoverflow无果......(此处浪费半个小时)
还是靠自己吧。
为了解决这个奇怪的问题,我又找了其它库中使用了from xxx import xxx的py文件。
在bs4库中,找到结果如下:
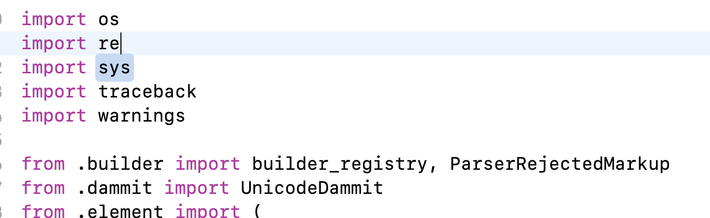
咦?为什么有些库前面加了个.?难道是这个原因?
没错!确实是这个原因!!!
报错1:解决方案:
1、打开bencode模块文件(/usr/local/lib/python3.7/site-packages/bencode/__init__.py)。...
|--摘 sublime运行python提示错误解决方法以及注意事项
不知道Build System,选择Automatic如何
默认的编译器可以直接按Ctrl+B编译运行Python,并在控制台输出结果.美中不足的是无法输出中文,需要自己手动配置一番。
在Sublime Text 3 中依次点击菜单Tools->build system->New build system,粘贴下方的代码并保存为python.sublime-build。重启Sublime即可。
{
"cmd": ["python","-u","$file"],
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
"selector": "source.python",
"encoding": "cp936" #windows下 设置65001 报错00000
}
...
|--转 Python爬虫练手,一个简单的Python资讯采集案例
在网上找的,感觉还行,收藏一下
一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采集和保存!
应用到的库
requests,time,re,UserAgent,etree
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
列表页面
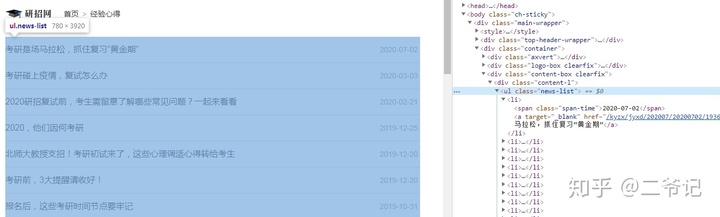
列表页,链接xpath解析
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
详情页
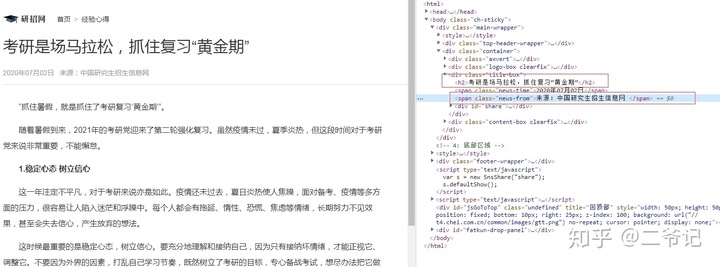
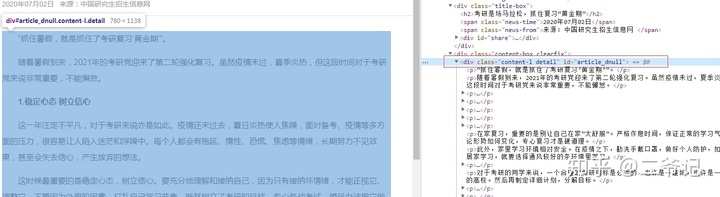
内容xpath解析
h2=req.xpath('//div[@class="title-box"]/h2/text()')[0]
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
内容格式化处理
detail='\n'.join(details)
标题格式化处理,替换非法字符
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替换为下划线
保存数据,保存为txt文本
def save(self,h2, author, detail):
with open(f'{h2}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author))
print(f"保存{h2}.txt文本成功!")
遍历数据采集,yield处理
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
程序运行效果

程序采集效果
附源码参考:
#研招网考研资讯采集
#20200710 by微信:huguo00289
# -*- coding: UTF-8 -*-
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
class RandomHeaders(object):
ua=UserAgent()
@property
def random_headers(self):
return {
'User-Agent': self.ua.random,
}
class Spider(RandomHeaders):
def __init__(self,url):
self.url=url
def parse_home_list(self,url):
response=requests.get(url,headers=self.random_headers).content.decode('utf-8')
req=etree.HTML(response)
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
print(href_list)
for href in href_list:
item = self.parse_detail(f'https://yz.chsi.com.cn{href}')
yield item
def parse_detail(self,url):
print(f">>正在爬取{url}")
try:
response = requests.get(url, headers=self.random_headers).content.decode('utf-8')
time.sleep(2)
except Exception as e:
print(e.args)
self.parse_detail(url)
else:
req = etree.HTML(response)
try:
h2=req.xpath('//div[@class="title-box"]/h2/text()')[0]
h2=self.validate_title(h2)
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
detail='\n'.join(details)
print(h2, author, detail)
self.save(h2, author, detail)
return h2, author, detail
except IndexError:
print(">>>采集出错需延时,5s后重试..")
time.sleep(5)
self.parse_detail(url)
@staticmethod
def validate_title(title):
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
def save(self,h2, author, detail):
with open(f'{h2}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author))
print(f"保存{h2}.txt文本成功!")
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
if __name__=="__main__":
url="https://yz.chsi.com.cn/kyzx/jyxd/"
spider=Spider(url)
for data in spider.get_tasks():
prin
免责声明:代码仅学习使用,勿用于非法用途...
|--摘 Python安装教程(非常详细) python如何安装使用
Python安装教程(非常详细)?pyrthon是一款比较流行的编程语言,有着比价简单的语法和丰富第三方库 是很多编程人员必备的软件帮用户处理个各种编程。
1、首先需要下载python安装包,官网下载地址:点击进入,点开链接后,可以看到很多版本,需要下载跟自己的电脑系统一致版本;
Win7电脑的话,最新的版本
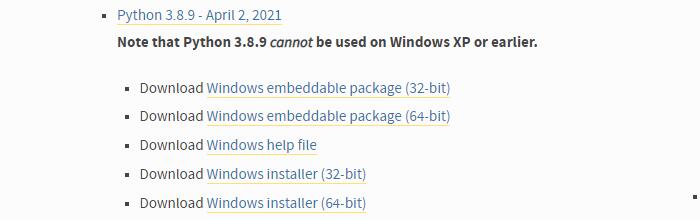
- Python 3.8.9 - April 2, 2021Note that Python 3.8.9cannotbe used on Windows XP or earlier.
- DownloadWindows embeddable package (32-bit)
- DownloadWindows embeddable package (64-bit)
- DownloadWindows help file
- DownloadWindows installer (32-bit)
- DownloadWindows installer (64-bit)
Win8,Win10电脑的话,截止到2022年4月17号,最新的版本是
- Python 3.10.4 - March 24, 2022Note that Python 3.10.4cannotbe used on Windows 7 or earlier.
- DownloadWindows embeddable package (32-bit)
- DownloadWindows embeddable package (64-bit)
- DownloadWindows help file
- DownloadWindows installer (32-bit)
- DownloadWindows installer (64-bit)
embeddable zip file 是压缩包版本,即便携版,解压可用
executable installer 是可执行的安装版本,即离线版,下载到本地后可以直接安装
web-based installer 是联网安装版,体积很小,但需要保持网络畅通
建议使用离线按安装版(executable installer),此版本会帮你设置系统变量,无需自己动手;
3、下载之后将其打开,出现下面的界面则说明电脑已经安装过python,直接关闭窗口,跳到教程的下一步;
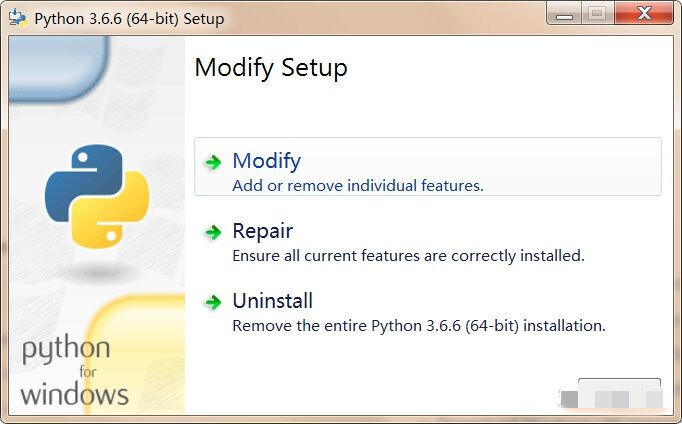
4、如果是第一次安装,就会出现下面的界面,首先选择自定义安装“customize installation”,勾选下方的加入系统变量“add python 3.8 to PATH“;...
|--转 Python 使用selenium报错:'chromedriver' executable needs to be in PATH
在我们使用 Python selenium 库时,第一件事是:pip install selenium;第二步是: 下载对应的谷歌浏览器驱动(我用的谷歌,如果火狐可能略微不同),
放在 Python 目录下(前提是你的python已经设置环境变量哈)。这里主要说一下上面的错误。
错误原因:
chromedriver和谷歌浏览器版本不对应。
解决办法:
以下均在浏览器中输。
查看谷歌浏览器版本: chrome://version/...
|--转 python爬虫数据采集(文中代码不完整,转载来是提供一个采集思路)
采用google浏览器,使用selenium库,将浏览器设置为无头模式
文中的代码部分需要修改,另外,他提到的用模拟浏览器访问的代码没有看到。
近几年来,python的热度一直特别火!大学期间,也进行了一番深入学习,毕业后也曾试图把python作为自己的职业方向,虽然没有如愿成为一名python工程师,但掌握了python,也让我现如今的工作开展和职业发展更加得心应手。这篇文章主要与大家分享一下自己在python爬虫方面的收获与见解。
python爬虫是大家最为熟悉的一种python应用途径,由于python具有丰富的第三方开发库,所以它可以开展很多工作:比如 web开发(django)、应用程序开发(tkinter、wxpython、qt)、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。平时自己使用最多的是python爬虫(结合tkinter,开发爬虫应用程序)和使用django开发一些小型个人网站,django框架可以自动根据实体类生成管理端,极大的提升了系统的开发效率,有兴趣的朋友可以尝试一下。
一个成功的爬虫需要对应一个标准化的网站,爬虫主要是为了方便我们获取数据,如果目标系统开发不规范,无规则,很难用爬虫定制一套规则去爬取,并且爬虫基本是定制化的,对于不同的系统需要去调整。
首先想做好爬虫 一款好的代理ip必不可少
这里推荐一款适合爬虫的代理ip---代理云
爬虫的小伙伴可以去领取免费的代理IP试一下
国内高质动态IP。时效2-10分钟,现在注册还能免费领取一万代理IP
爬虫爬取数据的第一步必须分析目标网站的技术以及网站数据结构(通过前端源码),可借助chrome浏览器,目前python爬虫主要会面对一下三种网站:
1. 前后端分离网站
前端通过传递参数访问接口,后端返回json数据,对于此类网站,python可模拟浏览器前端,发送参数然后接收数据,便完成了爬虫数据的目标
2. 静态网站
通过python的第三方库(requests、urllib),下载源码,通过xpath、正则匹配数据
3.动态网站
如果采用第2种方法,下载的源码只是简单的html,源码中没有任何数据,因为此类动态网站需要js加载后,源码中才会有数据,对于此类网站,可以借助自动化测试工具selenium
爬虫步骤:
1.分析网站技术与目标数据的结构
2.根据第一步分析结构,选择对应的技术策略
3.爬取数据
4.提升性能,提高操作舒适度(结合客户端技术,为爬虫定制界面)
5.根据需求进行数据清洗
6.数据储存,存储到数据库、文档等
反扒机制:
1. 当系统判断同属一个ip的客户端不间断多次访问,会拒绝此ip的访问
解决方案:动态代理,不停的更换ip去访问目标系统,或者从免费的ip代理网站爬取ip,创建ip池,如果目标数据量不大,可通过降低访问速度,以规避反扒...
