|-转 使用node.js爬取网页数据(简单粗暴)
前言
本文使用node以爬取百度新闻为例展示node爬虫技术。 需求:能看懂html网页结构,知道自己想要哪里。 需求:能看懂html网页结构,知道自己想要哪里。 需求:能看懂html网页结构,知道自己想要哪里。
正文
1.再vscode中新建文件夹,右键文件夹选择集成终端中打开
2.输入初始化命令:npm init -y
3.安装express 模块:npm i express
4.安装got模块:npm i got
5.安装cheerio模块:npm i cheerio 安装完成应显示: 
6.代码部分:
app.get(/p, (req, res) => { //定义路由
(async () => {
try {
const response = await got(https://news.baidu.com/); //想抓取的网址
let $ = cheerio.load(response.body) //获取网址的DOM结构
let result = $(#pane-news li a) //想抓取的部位
let news = [] //定义新闻数组
result.each((index, item) => { //循环抓取的内容
news.push($(item).text()) //循环添加到数组中
fs.writeFileSync(./news.txt, $(item).text()+\n, {flag: a}) //写入文件中
})
res.send(news) //显示在页面上
} catch (error) {
console.log(error);
}
})();
})
//打开服务器端口
app.listen(3001, () => {
console.log(http://localhost:3001)
})
提示:不会看不懂没事因为我没学node一开始也看不懂哈哈哈,直接复制粘贴。 在终端运行 http://localhost:3001/p 进行查看 图示: 要抓取的部分 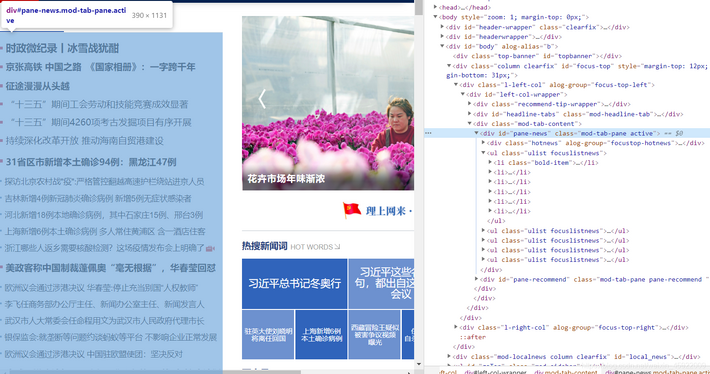 成果图:
成果图:  用fs模块写入txt文本:
用fs模块写入txt文本: 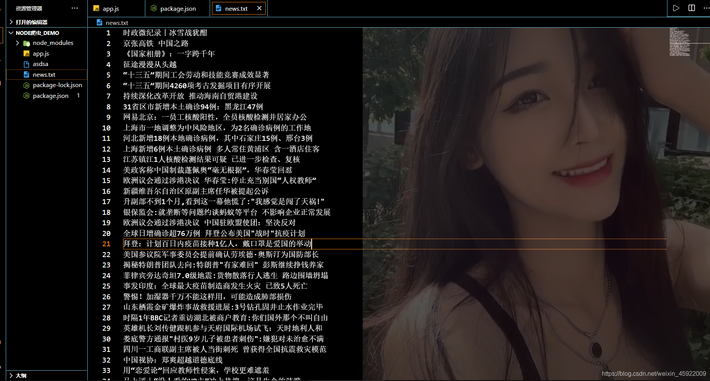 ...
...
浏览更多内容请先登录。
立即注册
分享的网址网站均收集自搜索引擎以及互联网,非查问网运营,查问网并没有提供其服务,请勿利用其做侵权以及违规行为。
更新于:2024-10-04 17:23:26
相关内容
PHP向js传数组
软件使用总结
2018年必须要吐槽下迅雷,开了迅雷网页打开很慢
msyql备份数据的语句mysqldump使用
uni-app 简单介绍(基于Vue.js,开发一次,多端覆盖)
nodejs puppeteer 自动化测试和采集的内容整理
[Bug]: TypeError: page.$x is not a function
推荐内容
