|-原 php-webdriver 配合chromedriver 采集 (Windows系统)(2023年12月)
系统环境Win10,PHP8.0。此方法最大好处是能获取JS生成的内容。
首先查看chrome版本,谷歌浏览器输入下面命令查看
chrome://version/
https://googlechromelabs.github.io/chrome-for-testing/下载好对应版本的chromedriver
我的windows下载的是 win64的
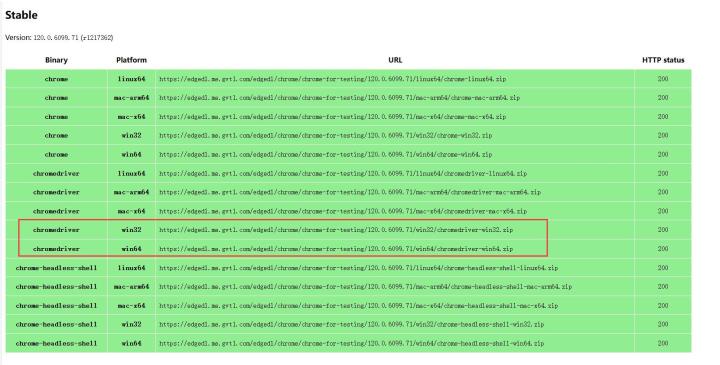
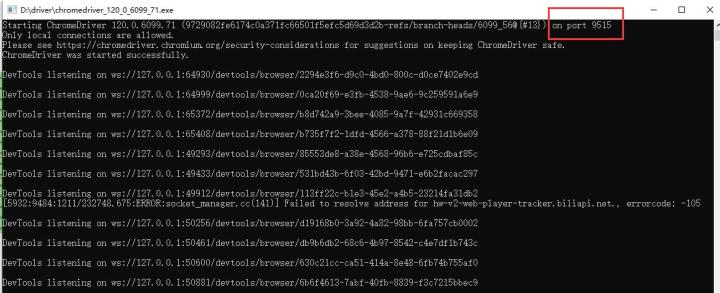
下载后运行,看到运行在了端口9515上,后面配置的时候要用到。
 ...
...
|-摘 PHP Querylist采集插件Puppeteer的安装
此方法已经不好用了 2023年12月备注
使用PuppeteerDOM解析JavaScript动态渲染的页面。使用此插件需要有一定的Node.js基础知识,并且会配置Node运行环境。
此插件是基于PuPHPeteer包的简单封装,支持使用Puppeteer所有的API,非常强大!
环境要求
PHP >= 7.1
Node >= 8
安装
1, 安装插件
composer require jaeger/querylist-puppeteer --ignore-platform-reqs
2,安装Node依赖(与composer一样在项目根目录下执行)
如果不是在项目根目录执行,之后运行QueryList代码会报错,提示 Cannot find module 'lodash' Require stack,但是你安装了lodash,还是一样会报这个错,所以npm或者yarn安装时要在项目根目录
Error:The command "'node' '/.../vendor/nesk/rialto/src/node-process/serve.js' '/.../vendor/nesk/puphpeteer/src/PuppeteerConnectionDelegate.js' '{"idle_timeout":60,"log_node_console":false,"log_browser_console":false}'" failed. Exit Code: 1(General error) Working directory: /.../frontend/web Output: ================ Error Output: ================ node:internal/modules/cjs/loader:936 throw err; ^ Error: Cannot find module 'lodash' Require stack: - /.../vendor/nesk/rialto/src/node-process/NodeInterceptors/StandardStreamsInterceptor.js - /.../vendor/nesk/rialto/src/node-process/NodeInterceptors/ConsoleInterceptor.js - /.../vendor/nesk/rialto/src/node-process/serve.js at Function.Module._resolveFilename (node:internal/modules/cjs/loader:933:15) at Function.Module._load (node:internal/modules/cjs/loader:778:27) at Module.require (node:internal/modules/cjs/loader:1005:19) at require (node:internal/modules/cjs/helpers:102:18) at Object. (/.../vendor/nesk/rialto/src/node-process/NodeInterceptors/StandardStreamsInterceptor.js:3:11) at Module._compile (node:internal/modules/cjs/loader:1105:14) at Object.Module._extensions..js (node:internal/modules/cjs/loader:1159:10) at Module.load (node:internal/modules/cjs/loader:981:32) at Function.Module._load (node:internal/modules/cjs/loader:822:12) at Module.require (node:internal/modules/cjs/loader:1005:19) { code: 'MODULE_NOT_FOUND', requireStack: [ '/.../vendor/nesk/rialto/src/node-process/NodeInterceptors/StandardStreamsInterceptor.js', '/.../vendor/nesk/rialto/src/node-process/NodeInterceptors/ConsoleInterceptor.js', '/.../vendor/nesk/rialto/src/node-process/serve.js' ] }
下面安装Node依赖
npm install @nesk/puphpeteer
或者使用yarn安装Node依赖:
yarn add @nesk/puphpeteer
如果npm安装速度太慢,可以尝试更换国内npm镜像源:
npm config set registry https://registry.npm.taobao.org
插件注册选项
QueryList::use(Chrome::class,$opt1)
$opt1: 设置chrome函数别名
API
chrome($url, $options = []) 使用Chrome打开链接,返回值为设置好HTML的QueryList对象
参数$url: 要访问的网页链接地址
参数$options: 设置Puppeteer的launch()方法的选项,全部选项:puppeteer.launch([options])
用法
在QueryList中注册插件
use QL\QueryList; use QL\Ext\Chrome; $ql = QueryList::getInstance(); // 注册插件,默认注册的方法名为: chrome $ql->use(Chrome::class); // 或者自定义注册的方法名 $ql->use(Chrome::class,'chrome');
基本用法 ...
|-转 php使用QueryList轻松采集JavaScript动态渲染页面
QueryList使用jQuery的方式来做采集,拥有丰富的插件。
下面来演示QueryList使用PhantomJS插件抓取JS动态创建的页面内容。
安装
使用Composer安装:
- 安装QueryList
composer require jaeger/querylist
GitHub:https://github.com/jae-jae/QueryList
- 安装PhantomJS插件
composer require jaeger/querylist-phantomjs
GitHub:https://github.com/jae-jae/QueryList-PhantomJS
下载PhantomJS二进制文件
PhantomJS官网:http://phantomjs.org,下载对应平台的PhantomJS二进制文件。
插件API
- QueryListbrowser($url,$debug = false,$commandOpt = []):使用浏览器打开连接
使用
以采集「今日头条」手机版为例,「今日头条」手机版基于React框架,内容是纯动态渲染出来的。
下面演示QueryList的PhantomJs插件用法:
- 安装插件
use QL\QueryList; use QL\Ext\PhantomJs; $ql = QueryList::getInstance(); // 安装时需要设置PhantomJS二进制文件路径 $ql->use(PhantomJs::class,'/usr/local/bin/phantomjs'); //or Custom function name $ql->use(PhantomJs::class,'/usr/local/bin/phantomjs','browser');
- Example-1
获取动态渲染的HTML:
$html = $ql->browser('https://m.toutiao.com')->getHtml();
print_r($html);
获取所有p标签文本内容: ...
|-转 python关键词爬取bing【必应images】高清大图
import sys import os import requests import urllib from bs4 import BeautifulSoup import re import time header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36' } url = "https://cn.bing.com/images/async?q={0}&first={1}&count={2}&scenario=ImageBasicHover&datsrc=N_I&layout=ColumnBased&mmasync=1&dgState=c*9_y*2226s2180s2072s2043s2292s2295s2079s2203s2094_i*71_w*198&IG=0D6AD6CBAF43430EA716510A4754C951&SFX={3}&iid=images.5599" #需要爬取的图片关键词 name="风景" #本地存储路径 path = "D:\\bingimg\\"+name '''获取缩略图列表页''' def getStartHtml(url,key,first,loadNum,sfx): page = urllib.request.Request(url.format(key,first,loadNum,sfx),headers = header) html = urllib.request.urlopen(page) return html '''从缩略图列表页中找到原图的url,并返回这一页的图片数量''' def findImgUrlFromHtml(html,rule,url,key,first,loadNum,sfx,count): soup = BeautifulSoup(html,"lxml") link_list = soup.find_all("a", class_="iusc") url = [] for link in link_list: result = re.search(rule, str(link)https://blog.csdn.net/qq_18647249/article/details/104277803
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple beautifulsoup4
|-转 推荐项目:Node.js与PHP的完美融合——node-php
推荐项目:Node.js与PHP的完美融合——node-php
项目简介
node-php 是一个开源项目,它将 Node.js 和 PHP 进行了完美的融合,为开发者提供了更加强大的开发环境。通过 node-php ,你可以轻松地在 Node.js 应用中调用 PHP 函数,并利用 PHP 的强大功能来处理数据。
功能特性
调用 PHP 函数
node-php 提供了一个简单的 API,可以让 Node.js 应用直接调用 PHP 函数。这样一来,你可以利用 PHP 的丰富函数库来进行数据处理,而无需离开 Node.js 环境。
高性能
由于 node-php 是基于进程间通信(IPC)实现的,因此它可以充分利用多核 CPU 来提高性能。这意味着你的应用可以在不影响响应速度的情况下进行大量的计算任务。
易于集成
node-php 可以轻松地与现有的 Node.js 应用进行集成。只需要添加一些简单的代码,就可以让你的应用具备强大的 PHP 功能。
使用场景
数据处理
如果你的应用需要对大量数据进行处理,那么可以考虑使用 node-php 。通过调用 PHP 函数,你可以轻松地完成各种复杂的数据操作。...
|-转 PHP__采集类__Snoopy
Snoopy
目录
了解Snoopy
Snoopy是一个php类,用来模仿web浏览器的功能,它能完成获取网页内容和发送表单的任务。
Snoopy的一些特点:
* 方便抓取网页的内容
* 方便抓取网页的文本内容 (去除HTML标签)
* 方便抓取网页的链接
* 支持代理主机
* 支持基本的用户名/密码验证
* 支持设置user_agent,referer(来路), cookies 和 header content(头文件)
* 支持浏览器转向,并能控制转向深度
* 能把网页中的链接扩展成高质量的url(默认)
* 方便提交数据并且获取返回值
* 支持跟踪HTML框架(v0.92增加)
* 支持再转向的时候传递cookies(v0.92增加)
下载Snoopy:
http://sourceforge.net/projects/snoopy/
常用功能
1.获取指定url内容
$url = "http://www.pigshu.com";
include("snoopy.php");
$snoopy = new Snoopy;
$snoopy->fetch($url); //获取所有内容
echo $snoopy->results; //显示结果
$snoopy->fetchtext //获取文本内容(去掉html代码)
$snoopy->fetchlinks //获取链接
$snoopy->fetchform //获取表单
2.表单提交
<span style="font-size:14px;">$formvars["username"] = "admin"; $formvars["pwd"] = "admin"; $action = "http://www.pigshu.com";//表单提交地址 $snoopy->submit($action,$formvars);//$formvars为提交的数组 echo $snoopy->results; //获取表单提交后的返回的结果 $snoopy->submittext; //提交后只返回去除html的文本 $snoopy->submitlinks;//提交后只返回链接</span><span style="font-size:24px;"> </span>既然已经提交的表单那就可以做很多事情接下来我们来伪装ip,伪装浏览器
3.伪装
$formvars["username"] = "admin"; $formvars["pwd"] = "admin"; $action = "http://www.pigshu.com"; include "snoopy.php"; $snoopy = new Snoopy; $snoopy->cookies["PHPSESSID"] = fc106b1918bd522cc863f36890e6fff7; //伪装sessionid $snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)"; //伪装浏览器 $snoopy->referer = "http://s.jb51.net"; //伪装来源页地址http_referer $snoopy->rawheaders["Pragma"] = "no-cache"; //cache 的http头信息 $snoopy->rawheaders["X_FORWARDED_FOR"] = "127.0.0.101"; //伪装ip $snoopy->submit($action,$formvars); echo $snoopy->results;原来我们可以伪装 session 伪装浏览器,伪装 ip , haha 可以做很多事情了。 例如带验证码,验证 ip 投票,可以不停的投。 ps: 这里伪装 ip ,其实是伪装 http 头 , 所以一般的通过 REMOTE_ADDR 获取的 ip 是伪装不了, 反而那些通过 http 头来获取 ip 的 ( 可以防止代理的那种 ) 就可以自己来制造 ip 。 关于如何验证码,简单说下: 首先用普通的浏览器,查看页面,找到验证码所对应的 sessionid , 同时记下 sessionid 和验证码值, 接下来就用 snoopy 去伪造。 原理 : 由于是同一个 sessionid 所以取得的验证码和第一次输入的是一样的。
4伪造更多信息
有时我们可能需要伪造更多的东西,snoopy完全为我们想到了 $snoopy->proxy_host = "www.pigshu.com"; $snoopy->proxy_port = "8080"; //使用代理 $snoopy->maxredirs = 2; //重定向次数 $snoopy->expandlinks = true; //是否补全链接在采集的时候经常用到 // 例如链接为 /images/taoav.gif 可改为它的全链接 http://www.pigshu.com/images/taoav.gif,这个地方其实可以在最后输出的时候用ereg_replace函数自己替换 $snoopy->maxframes = 5 //允许的最大框架数 //注意抓取框架的时候 $snoopy->results 返回的是一个数组 $snoopy->error //返回报错信息 ...
|-转 使用node.js爬取网页数据(简单粗暴)
前言
本文使用node以爬取百度新闻为例展示node爬虫技术。 需求:能看懂html网页结构,知道自己想要哪里。 需求:能看懂html网页结构,知道自己想要哪里。 需求:能看懂html网页结构,知道自己想要哪里。
正文
1.再vscode中新建文件夹,右键文件夹选择集成终端中打开
2.输入初始化命令:npm init -y
3.安装express 模块:npm i express
4.安装got模块:npm i got
5.安装cheerio模块:npm i cheerio 安装完成应显示: 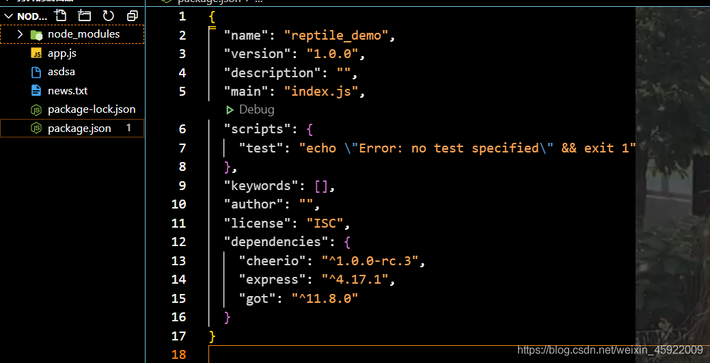
6.代码部分:
app.get(/p, (req, res) => { //定义路由
(async () => {
try {
const response = await got(https://news.baidu.com/); //想抓取的网址
let $ = cheerio.load(response.body) //获取网址的DOM结构
let result = $(#pane-news li a) //想抓取的部位
let news = [] //定义新闻数组
result.each((index, item) => { //循环抓取的内容
news.push($(item).text()) //循环添加到数组中
fs.writeFileSync(./news.txt, $(item).text()+\n, {flag: a}) //写入文件中
})
res.send(news) //显示在页面上
} catch (error) {
console.log(error);
}
})();
})
//打开服务器端口
app.listen(3001, () => {
console.log(http://localhost:3001)
})
提示:不会看不懂没事因为我没学node一开始也看不懂哈哈哈,直接复制粘贴。 在终端运行 http://localhost:3001/p 进行查看 图示: 要抓取的部分 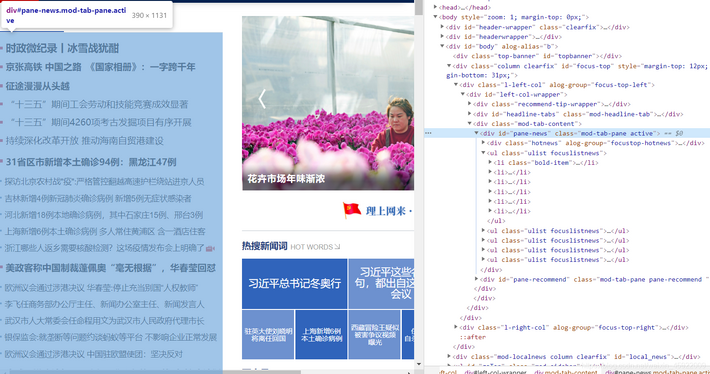 成果图:
成果图:  用fs模块写入txt文本:
用fs模块写入txt文本: 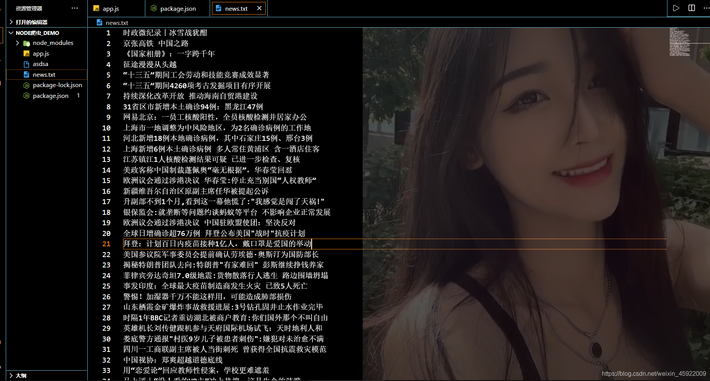 ...
...
|-转 PHP采集页面的四种方法
本文给出的方法是最基本的PHP采集方法,很多网站都做防采集的处理,对于这些网站可以尝试使用QueryList(php项目)采集,另外对于JS生成的页面可以用Nodejs采集。
什么叫采集?
就是使用PHP程序,把其他网站中的信息抓取到我们自己的数据库中、网站中。
可以通过三种方法来使用PHP访问到网页
1. 使用file_get_contents()
前提:在php.ini中设置允许打开一个网络的url地址。

使用这个函数时可以直接将路径写入函数中,将所选路径的内容加载出来,但是在访问网上的网址时必须连接网络
<?php echo file_get_contents(https://www.baidu.com/);?>
2. 使用socket技术采集:
socket采集是最底层的,它只是建立了一个长连接,然后我们要自己构造http协议字符串去发送请求。例如要想获取这个页面的内容,http://tv.youku.com/?spm=a2hww.20023042.topNav.5~1~3!2~A,用socket写如下:
<?php
//连接,$error错误编号,$errstr错误的字符串,30s是连接超时时间
$fp=fsockopen("www.youku.com",80,$errno,$errstr,30);
if(!$fp) die("连接失败".$errstr);
//构造http协议字符串,因为socket编程是最底层的,它还没有使用http协议
$http="GET /?spm=a2hww.20023042.topNav.5~1~3!2~A HTTP/1.1\r\n"; // \r\n表示前面的是一个命令
$http.="Host:www.youku.com\r\n"; //请求的主机
$http.="Connection:close\r\n\r\n"; // 连接关闭,最后一行要两个\r\n
//发送这个字符串到服务器
fwrite($fp,$http,strlen($http));
//接收服务器返回的数据
$data=;
while (!feof($fp)) {
$data.=fread($fp,4096); //fread读取返回的数据,一次读取4096字节
}
//关闭连接
fclose($fp);
var_dump($data);
?>
打印出的结果如下,包含了返回的头信息及页面的源码:

3、使用fopen获取网页源代码
<?php
$url = 'https://www.baidu.com/';
$opts = array(
'http'=>array(
'method'=>"GET",
'header'=>"Accept-language: en\r\n" .
"Cookie: foo=bar\r\n"
)
);
$context = stream_context_create($opts);
$fp = fopen($url, 'r', false, $context);
while(!feof($fp)) {
$result.= fgets($fp, 1024);
}
fpassthru($fp);
fclose($fp);
?>4. 使用curl...
|-转 python获取完整网页内容(含js动态加载的):selenium+phantomjs
https://blog.csdn.net/huwei2003/article/details/107490468
建议安装pip install Selenium4R
Selenium4R是 Selenium4的魔改版,国内可以直接安装
1 不管用requests_html,还是获取网页的源码时,发现通过ajax动态加载的内容都获取不到,得通过分析动态加载的接口去重新请求数据,有时很不方便。
2 下面我们利用 +phantomjs 来实现一次性获取网页上所有的内容;
1. 下载Phantomjs,下载地址:https://phantomjs.org/download.html 选择下载windows的还是linux的 2. 下完之后直接解压就OK了,然后selenium的安装用pip就行了
代码:
import requests
from lxml import etree
from lxml import html
from html.parser import HTMLParser #导入html解析库
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='E:\\pythontest\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def getHtmlByXpath(html_str,xpath):
strhtml = etree.HTML(html_str)
strResult = strhtml.xpath(xpath)
return strResult
def w_file(filepath,contents):
with open(filepath,'w',encoding='gb18030') as wf:
wf.write(contents)
def main():
url = 'https://m.fygdrs.com/h5/news.html?t=2&id=67062' #要访问的网址
strhtml = getHTMLText(url) #获取HTML
#print(html)
w_file('E:\\pythontest\\wfile.txt',strhtml)
strDiv=getHtmlByXpath(strhtml,"//div[@id='Article-content']")
if(strDiv):
str1= html.tostring(strDiv[0])
print(str1)
str2 = HTMLParser().unescape(str1.decode())
print(str2)
w_file('E:\\pythontest\\wfile3.txt',str2)
print('ok')
if __name__ == '__main__':
main()
--- end --- ...
|-转 【环境配置】centos安装chrome浏览器
centos上安装chrome分为2种方式,一种是通过repo仓库在线安装,一种是下载rpm安装包,离线安装
方式1:repo仓库在线安装
1.添加Chrome仓库
创建一个名为google-chrome.repo的文件,并将以下内容添加到文件中:
sudo vi /etc/yum.repos.d/google-chrome.repo
在编辑器中,添加以下内容:
[google-chrome] name=google-chrome baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch enabled=1 gpgcheck=1 gpgkey=https://dl.google.com/linux/linux_signing_key.pub
保存并关闭文件。
查看Chrome是否可用
sudo yum list available | grep google-chrome
2.安装Chrome:
安装最新版本的Chrome:
sudo yum install google-chrome-stable
如果想安装特定版本,可以使用以下命令:
sudo yum install google-chrome-stable-{version}
将 {version} 替换为想要安装的Chrome版本号。
如果安装失败,请看问题记录与解决方案
方式2:离线下载rpm包,本地安装
访问: https://www.google.com/intl/zh-CN/chrome/ 点击其他平台,选择对应的版本,下载本地安装 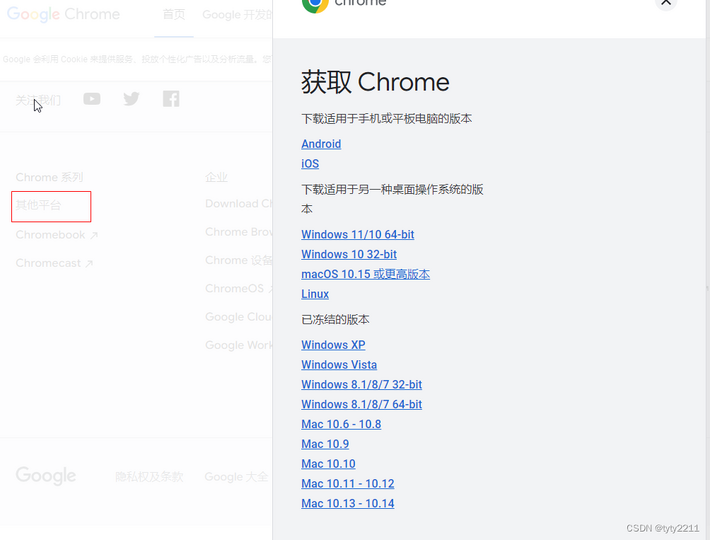
【问题记录】
1.安装报错:
google-chrome-stable-119.0.6045.159-1.x86_64.rpm 的公钥尚未安装 失败的软件包是:google-chrome-stable-119.0.6045.159-1.x86_64 GPG 密钥配置为:https://dl.google.com/linux/linux_signing_key.pub ...
|-转 爬虫进阶路程2——centos安装各个版本chrome
接《爬虫进阶路程1——开篇》,里面讲到使用selenium进行实现高级别的爬虫,能够绕过那些绞尽脑汁是js复杂化的反爬方式,而selenium是需要配合浏览器来搭配使用的,这里就来讲一下如何在linux安装无头浏览器,window上怎么装就不讲了,直接百度很容易就装上了,但是如果正儿八经做爬虫的肯定不会止步于在自己PC上来爬数据,最终一定是走linux服务器的。
安装
这里主要通过yum本地安装rpm包来完成的chrome浏览器安装的,chrome安装包各版本下载地址如下:https://www.chromedownloads.net/chrome64linux/。从上面下载我们需要版本的安装包,解压安装包压缩文件,里面有一个以rpm为后缀的文件,将该文件上传至linux。上传之后通过rpm命令安装,比如安装包名为:google-chrome-stable_current_x86_64-64_84.0.4147.105.rpm,安装命令如下:
$ yum install google-chrome-stable_current_x86_64-64_84.0.4147.105.rpm
等安装完之后,我们可以做一个软链,因为chrome安装之后命令默认为google-chrome-stable,我们可以将google-chrome-stable软链到chrome,通过chrome直接执行命令,软链就类似window的快捷方式一样。 ...
|-转 php开源采集类Snoopy.class.php功能使用介绍与下载地址
还没下载到Snoopy.class.php,还没实测 20241004
php开源采集类Snoopy.class.php功能使用介绍与下载地址_snoopy.class.php下载-CSDN博客
Snoopy是什么?
Snoopy是一个php类,用来模仿web浏览器的功能,它能完成获取网页内容和发送表单的任务。
Snoopy的一些特点:
* 方便抓取网页的内容* 方便抓取网页的文本内容 (去除HTML标签)* 方便抓取网页的链接* 支持代理主机* 支持基本的用户名/密码验证* 支持设置 user_agent, referer(来路), cookies 和 header content(头文件)* 支持浏览器转向,并能控制转向深度* 能把网页中的链接扩展成高质量的url(默认)* 方便提交数据并且获取返回值* 支持跟踪HTML框架(v0.92增加)* 支持再转向的时候传递cookies (v0.92增加)* 支持再转向的时候传递cookies
要求:
Snoopy requires PHP with PCRE (Perl Compatible Regular Expressions),which should be PHP 3.0.9 and up. For read timeout support, it requiresPHP 4 Beta 4 or later. Snoopy was developed and tested with PHP 3.0.12.
类方法:
fetch($URI)———–
这是为了抓取网页的内容而使用的方法。$URI参数是被抓取网页的URL地址。抓取的结果被存储在 $this->results 中。如果你正在抓取的是一个框架,Snoopy将会将每个框架追踪后存入数组中,然后存入 $this->results。
fetchtext($URI)—————
本方法类似于fetch(),唯一不同的就是本方法会去除HTML标签和其他的无关数据,只返回网页中的文字内容。
fetchform($URI)—————
本方法类似于fetch(),唯一不同的就是本方法会去除HTML标签和其他的无关数据,只返回网页中表单内容(form)。
fetchlinks($URI)—————-
本方法类似于fetch(),唯一不同的就是本方法会去除HTML标签和其他的无关数据,只返回网页中链接(link)。默认情况下,相对链接将自动补全,转换成完整的URL。
submit($URI,$formvars)———————-
本方法向$URL指定的链接地址发送确认表单。$formvars是一个存储表单参数的数组。
submittext($URI,$formvars)————————–
本方法类似于submit(),唯一不同的就是本方法会去除HTML标签和其他的无关数据,只返回登陆后网页中的文字内容。
submitlinks($URI)—————-
本方法类似于submit(),唯一不同的就是本方法会去除HTML标签和其他的无关数据,只返回网页中链接(link)。默认情况下,相对链接将自动补全,转换成完整的URL。
类属性: (缺省值在括号里)
$host 连接的主机$port 连接的端口$proxy_host 使用的代理主机,如果有的话$proxy_port 使用的代理主机端口,如果有的话$agent 用户代理伪装 (Snoopy v0.1)$referer 来路信息,如果有的话$cookies cookies, 如果有的话$rawheaders 其他的头信息, 如果有的话$maxredirs 最大重定向次数, 0=不允许 (5)$offsiteok whether or not to allow redirects off-site. (true)$expandlinks 是否将链接都补全为完整地址 (true)$user 认证用户名, 如果有的话$pass 认证用户名, 如果有的话$accept http 接受类型 (image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*)$error 哪里报错, 如果有的话$response_code 从服务器返回的响应代码$headers 从服务器返回的头信息$maxlength 最长返回数据长度$read_timeout 读取操作超时 (requires PHP 4 Beta 4+)设置为0为没有超时$timed_out 如果一次读取操作超时了,本属性返回 true (requires PHP 4 Beta 4+)$maxframes 允许追踪的框架最大数量$status 抓取的http的状态$temp_dir 网页服务器能够写入的临时文件目录 (/tmp)$curl_path cURL binary 的目录, 如果没有cURL binary就设置为 false
1. 采集页面内容
| 01 | include(include/snoopy.class.php); |
| 02 | echo "<pre>"; |
| 03 | $snoopy = new Snoopy; |
| 04 | $snoopy->host = http://www.baidu.com; |
| 05 | $snoopy-> fetchtext($snoopy->host); //获取所有文本内容(去掉html代码) |
| 06 | /* |
| 07 | $snoopy->fetch($snoopy->host); //获取页面所有链接 |
| 08 | $snoopy->fetchlinks($snoopy->host); //获取页面所有链接 |
| 09 | $snoopy->fetchlinks($snoopy->host); //获取链接 |
| 10 | $snoopy->fetchform($snoopy->host); //获取表单 |
| 11 | */ |
| 12 | print_r($snoopy->results); |
2. 下载指定url图片
| 01 | include_once( include/snoopy.class.php ); //调用Snoopy类 |
| 02 |
| 03 | function getImage($id,$url) { |
| 04 |
| 05 | $filename = $id . ".jpg"; |
| 06 |
| 07 | $temp = new Snoopy; |
| 08 | $temp -> fetch($url); |
| 09 | if($temp->results != "") { |
| 10 | $handle = fopen("images/" . $filename, "w"); |
| 11 | fwrite($handle, $temp->results);//写入抓得内容 |
| 12 | fclose($handle); |
| 13 | } |
| 14 | return $filename; |
| 15 | } |
3. 获取表单
| 1 | $snoopy = new Snoopy; |
| 2 | $snoopy->fetchform("http://lzw.me/login.asp"); |
| 3 | print $snoopy->results; |
4. 表单提交(如登陆等)
| 01 | $formvars["username"] = "test"; |
| 02 | $formvars["pwd"] = "123456"; |
| 03 |
| 04 | $action = "http://lzw.me/login.asp";//表单提交地址 |
| 05 | $snoopy->submit($action,$formvars);//$formvars为提交的数组 |
| 06 | echo $snoopy->results; //获取表单提交后的 返回的结果 |
| 07 | /*可选 |
| 08 | $snoopy->submittext($action,$formvars); //提交后只返回 去除html的 文本 |
| 09 | $snoopy->submitlinks($action,$formvars); //提交后只返回 链接 |
| 10 | */ |
5. 伪装ip,伪装浏览器
查看源码| 01 | $formvars["username"] = "admin"; |
| 02 | $formvars["pwd"] = "admin"; |
| 03 | $action = "http://lzw.me"; |
| 04 | include "snoopy.php"; |
| 05 | $snoopy = new Snoopy; |
| 06 | $snoopy->cookies["PHPSESSID"] = fc106b1918bd522cc863f36890e6fff7; //伪装sessionid |
| 07 | $snoopy->agent = Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727; //伪装浏览器 |
| 08 | $snoopy->referer = "http://lzw.me"; //伪装来源页地址 http_referer |
| 09 | $snoopy->rawheaders["Pragma"] = "no-cache"; //cache 的http头信息 |
| 10 | $snoopy->rawheaders["X_FORWARDED_FOR"] = "127.0.0.101"; //伪装ip |
| 11 | $snoopy->submit($action,$formvars); |
| 12 | echo $snoopy->results; |
snoopy下载
snoopy最新的是2008年更新的1.2.4版本,其开源下载地址如下,如果您下载遇到困难,可与志文工作室联系。...
|-转 PHP使用Browsershot进行网页截图
Browsershot是什么

Spatie Browsershot 是一个开源PHP库,它允许开发者在PHP应用程序中生成网页的截图。 这个库特别适用于Laravel框架,但也可以在其他 PHP 应用程序中使用。
主要特点
- 无头浏览器截图:使用无头版本的 Chrome 或 Chromium 浏览器来捕获网页的截图,无需打开完整的浏览器界面。
- 多种输出格式:支持生成 PNG、JPEG 以及 PDF 格式的文件。
- 自定义选项:可以自定义截图的尺寸、缩放比例、用户代理、超时时间等。
- 等待特定元素:可以设置等待页面上的某个元素出现或者等待一定时间后再进行截图。
- JavaScript支持:能够等待页面上的 JavaScript 加载完成,确保动态内容被正确渲染。
- 自定义HTML:不仅支持对在线网页进行截图,还可以对自定义的 HTML 字符串进行截图。
- 错误处理:提供清晰的错误信息,帮助开发者快速定位问题。
- 易于集成:通过 Composer 进行安装,易于集成到现有的 PHP 项目中。
安装
Spatie Browsershot 可以通过 Composer 进行安装:
composer require spatie/browsershot
使用
使用时,可以通过简单的门面方法调用:
use Spatie\Browsershot\Browsershot; Browsershot::url(https://www.baidu.com)->save(/path/to/save/baidu.png);
一些使用方法介绍
- url(string $url): 指定要截图的网页URL。
- save(string $filePath): 设置截图保存的路径。
- windowSize(int $width, int $height): 设置截图的宽度和高度。
- timeout(int $timeout): 设置超时时间,单位为秒。
- waitUntilNetworkIdle(bool $strict = true): 等待网络空闲,即所有请求都已完成。
- setChromePath(string $path): 设置Chrome或Chromium浏览器的可执行文件路径。
示例 ...
