|-转 什么是B-Tree
B-Tree就是我们常说的B树,一定不要读成B减树,否则就很丢人了。B树这种数据结构常常用于实现数据库索引,因为它的查找效率比较高。磁盘IO与预读磁盘读取依靠的是机...
B-Tree就是我们常说的B树,一定不要读成B减树,否则就很丢人了。B树这种数据结构常常用于实现数据库索引,因为它的查找效率比较高。
磁盘IO与预读
磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,大概9ms左右。这个成本是访问内存的十万倍左右;正是由于磁盘IO是非常昂贵的操作,所以计算机操作系统对此做了优化:预读;每一次IO时,不仅仅把当前磁盘地址的数据加载到内存,同时也把相邻数据也加载到内存缓冲区中。因为局部预读原理说明:当访问一个地址数据的时候,与其相邻的数据很快也会被访问到。每次磁盘IO读取的数据我们称之为一页(page)(注:此说法不准确)。一页的大小与操作系统有关,一般为4k或者8k。这也就意味着读取一页内数据的时候,实际上发生了一次磁盘IO。
(注:这里一次磁盘IO的说法不准确,我在网上找到一个比较准确的说法:
单个IO操作
当控制磁盘的控制器接到操作系统的读IO操作指令的时候,控制器就会给磁盘发出一个读数据的指令,并同时将要读取的数据块的地址传递给磁盘,然后磁盘会将读取到的数据传给控制器,并由控制器返回给操作系统,完成一个写IO的操作;同样的,一个写IO的操作也类似,控制器接到写的IO操作的指令和要写入的数据,并将其传递给磁盘,磁盘在数据写入完成之后将操作结果传递回控制器,再由控制器返回给操作系统,完成一个写IO的操作。单个IO操作指的就是完成一个写IO或者是读IO的操作。
)
B-Tree与二叉查找树的对比
我们知道二叉查找树查询的时间复杂度是O(logN),查找速度最快和比较次数最少,既然性能已经如此优秀,但为什么实现索引是使用B-Tree而不是二叉查找树,关键因素是磁盘IO的次数。
数据库索引是存储在磁盘上,当表中的数据量比较大时,索引的大小也跟着增长,达到几个G甚至更多。当我们利用索引进行查询的时候,不可能把索引全部加载到内存中,只能逐一加载每个磁盘页,这里的磁盘页就对应索引树的节点。
一、 二叉树
我们先来看二叉树查找时磁盘IO的次:定义一个树高为4的二叉树,查找值为10:
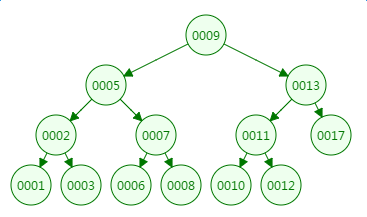
第一次磁盘IO:
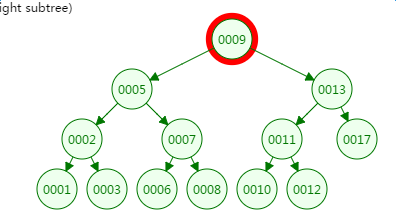
第二次磁盘IO
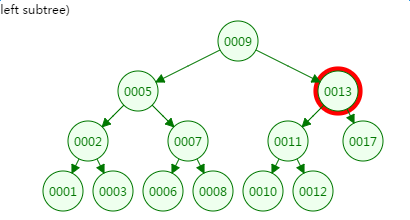
第三次磁盘IO:...
