转 Docker介绍
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
一个完整的Docker有以下几个部分组成:
- DockerClient客户端
- Docker Daemon守护进程
- Docker Image镜像
起源
Docker自2013年以来非常火热,无论是从 github 上的代码活跃度,还是Redhat在RHEL6.5中集成对Docker的支持, 就连Google的 Compute Engine 也支持 docker 在其之上运行。
一款开源软件能否在商业上成功,很大程度上依赖三件事 - 成功的 user case(用例), 活跃的社区和一个好故事。 dotCloud 之家的 PaaS 产品建立在docker之上,长期维护且有大量的用户,社区也十分活跃,接下来我们看看docker的故事。
- 环境管理复杂 - 从各种OS到各种中间件到各种app, 一款产品能够成功作为开发者需要关心的东西太多,且难于管理,这个问题几乎在所有现代IT相关行业都需要面对。
- 云计算时代的到来 - AWS的成功, 引导开发者将应用转移到 cloud 上, 解决了硬件管理的问题,然而中间件相关的问题依然存在 (所以openstack HEAT和 AWS cloudformation 都着力解决这个问题)。开发者思路变化提供了可能性。
- 虚拟化手段的变化 - cloud 时代采用标配硬件来降低成本,采用虚拟化手段来满足用户按需使用的需求以及保证可用性和隔离性。然而无论是KVM还是Xen在 docker 看来,都在浪费资源,因为用户需要的是高效运行环境而非OS, GuestOS既浪费资源又难于管理, 更加轻量级的LXC更加灵活和快速
- LXC的移动性 - LXC在 linux 2.6 的 kernel 里就已经存在了,但是其设计之初并非为云计算考虑的,缺少标准化的描述手段和容器的可迁移性,决定其构建出的环境难于迁移和标准化管理(相对于KVM之类image和snapshot的概念)。docker 就在这个问题上做出实质性的革新。这是docker最独特的地方。
 VM技术和容器技术对比
VM技术和容器技术对比面对上述几个问题,docker设想是交付运行环境如同海运,OS如同一个货轮,每一个在OS基础上的软件都如同一个集装箱,用户可以通过标准化手段自由组装运行环境,同时集装箱的内容可以由用户自定义,也可以由专业人员制造。这样,交付一个软件,就是一系列标准化组件的集合的交付,如同乐高积木,用户只需要选择合适的积木组合,并且在最顶端署上自己的名字(最后一个标准化组件是用户的app)。这也就是基于docker的PaaS产品的原型。
Docker 架构
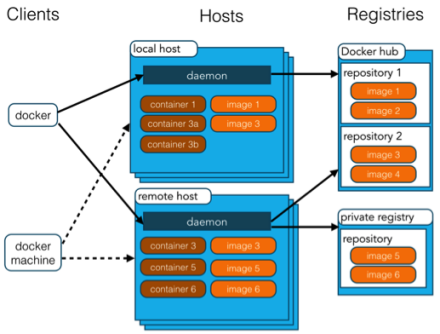
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。Docker 容器通过 Docker 镜像来创建。容器与镜像的关系类似于面向对象编程中的对象与类。[3]
Docker | 面向对象 |
|---|---|
容器 | 对象 |
镜像 | 类 |
特性
在docker的网站上提到了docker的典型场景:
- Automating the packaging and deployment of applications(使应用的打包与部署自动化)
- Creation of lightweight, private PAAS environments(创建轻量、私密的PAAS环境)
- Automated testing and continuous integration/deployment(实现自动化测试和持续的集成/部署)
- Deploying and scaling web apps, databases and backend services(部署与扩展webapp、数据库和后台服务)
由于其基于LXC的轻量级虚拟化的特点,docker相比KVM之类最明显的特点就是启动快,资源占用小。因此对于构建隔离的标准化的运行环境,轻量级的PaaS(如dokku), 构建自动化测试和持续集成环境,以及一切可以横向扩展的应用(尤其是需要快速启停来应对峰谷的web应用)。
- 构建标准化的运行环境,现有的方案大多是在一个baseOS上运行一套puppet/chef,或者一个image文件,其缺点是前者需要base OS许多前提条件,后者几乎不可以修改(因为copy on write 的文件格式在运行时rootfs是read only的)。并且后者文件体积大,环境管理和版本控制本身也是一个问题。
- PaaS环境是不言而喻的,其设计之初和dotcloud的案例都是将其作为PaaS产品的环境基础
- 因为其标准化构建方法(buildfile)和良好的REST API,自动化测试和持续集成/部署能够很好的集成进来
- 因为LXC轻量级的特点,其启动快,而且docker能够只加载每个container变化的部分,这样资源占用小,能够在单机环境下与KVM之类的虚拟化方案相比能够更加快速和占用更少资源
局限
Docker并不是全能的,设计之初也不是KVM之类虚拟化手段的替代品,简单总结几点:
- Docker是基于Linux 64bit的,无法在32bit的linux/Windows/unix环境下使用
- LXC是基于cgroup等linux kernel功能的,因此container的guest系统只能是linux base的
- 隔离性相比KVM之类的虚拟化方案还是有些欠缺,所有container公用一部分的运行库
- 网络管理相对简单,主要是基于namespace隔离
- cgroup的cpu和cpuset提供的cpu功能相比KVM的等虚拟化方案相比难以度量(所以dotcloud主要是按内存收费)
- Docker对disk的管理比较有限
- container随着用户进程的停止而销毁,container中的log等用户数据不便收集
针对1-2,有windows base应用的需求的基本可以pass了; 3-5主要是看用户的需求,到底是需要一个container还是一个VM, 同时也决定了docker作为 IaaS 不太可行。
针对6,7虽然是docker本身不支持的功能,但是可以通过其他手段解决(disk quota, mount --bind)。总之,选用container还是vm, 就是在隔离性和资源复用性上做权衡。
另外即便docker 0.7能够支持非AUFS的文件系统,但是由于其功能还不稳定,商业应用或许会存在问题,而AUFS的稳定版需要kernel 3.8, 所以如果想复制dotcloud的成功案例,可能需要考虑升级kernel或者换用ubuntu的server版本(后者提供deb更新)。这也是为什么开源界更倾向于支持ubuntu的原因(kernel版本)
Docker并非适合所有应用场景,Docker只能虚拟基于Linux的服务。Windows Azure 服务能够运行Docker实例,但到目前为止Windows服务还不能被虚拟化。
可能最大的障碍在于管理实例之间的交互。由于所有应用组件被拆分到不同的容器中,所有的服务器需要以一致的方式彼此通信。这意味着任何人如果选择复杂的基础设施,那么必须掌握应用编程接口管理以及集群工具,比如Swarm、Mesos或者Kubernets以确保机器按照预期运转并支持故障切换。
Docker在本质上是一个附加系统。使用文件系统的不同层构建一个应用是有可能的。每个组件被添加到之前已经创建的组件之上,可以比作为一个文件系统更明智。分层架构带来另一方面的效率提升,当你重建存在变化的Docker镜像时,不需要重建整个Docker镜像,只需要重建变化的部分。
可能更为重要的是,Docker旨在用于弹性计算。每个Docker实例的运营生命周期有限,实例数量根据需求增减。在一个管理适度的系统中,这些实例生而平等,不再需要时便各自消亡了。
针对Docker环境存在的不足,意味着在开始部署Docker前需要考虑如下几个问题。首先,Docker实例是无状态的。这意味着它们不应该承载任何交易数据,所有数据应该保存在数据库服务器中。
其次,开发Docker实例并不像创建一台虚拟机、添加应用然后克隆那样简单。为成功创建并使用Docker基础设施,管理员需要对系统管理的各个方面有一个全面的理解,包括Linux管理、编排及配置工具比如Puppet、Chef以及Salt。这些工具生来就基于命令行以及脚本。[5]
原理
Docker核心解决的问题是利用LXC来实现类似VM的功能,从而利用更加节省的硬件资源提供给用户更多的计算资源。同VM的方式不同,LXC其并不是一套硬件虚拟化方法 - 无法归属到全虚拟化、部分虚拟化和半虚拟化中的任意一个,而是一个操作系统级虚拟化方法, 理解起来可能并不像VM那样直观。所以我们从虚拟化到docker要解决的问题出发,看看他是怎么满足用户虚拟化需求的。
用户需要考虑虚拟化方法,尤其是硬件虚拟化方法,需要借助其解决的主要是以下4个问题:
- 隔离性 - 每个用户实例之间相互隔离, 互不影响。 硬件虚拟化方法给出的方法是VM, LXC给出的方法是container,更细一点是kernel namespace
- 可配额/可度量 - 每个用户实例可以按需提供其计算资源,所使用的资源可以被计量。硬件虚拟化方法因为虚拟了CPU, memory可以方便实现, LXC则主要是利用cgroups来控制资源
- 移动性 - 用户的实例可以很方便地复制、移动和重建。硬件虚拟化方法提供snapshot和image来实现,docker(主要)利用AUFS实现
- 安全性 - 这个话题比较大,这里强调是host主机的角度尽量保护container。硬件虚拟化的方法因为虚拟化的水平比较高,用户进程都是在KVM等虚拟机容器中翻译运行的, 然而对于LXC, 用户的进程是lxc-start进程的子进程, 只是在Kernel的namespace中隔离的, 因此需要一些kernel的patch来保证用户的运行环境不会受到来自host主机的恶意入侵, dotcloud(主要是)利用kernel grsec patch解决的.
Linux Namespace
LXC所实现的隔离性主要是来自kernel的namespace, 其中pid, net, ipc, mnt, uts 等namespace将container的进程, 网络, 消息, 文件系统和hostname 隔离开。
pid namespace
之前提到用户的进程是lxc-start进程的子进程, 不同用户的进程就是通过pidnamespace隔离开的,且不同 namespace 中可以有相同PID。具有以下特征:
- 每个namespace中的pid是有自己的pid=1的进程(类似/sbin/init进程)
- 每个namespace中的进程只能影响自己的同一个namespace或子namespace中的进程
- 因为/proc包含正在运行的进程,因此在container中的pseudo-filesystem的/proc目录只能看到自己namespace中的进程
- 因为namespace允许嵌套,父namespace可以影响子namespace的进程,所以子namespace的进程可以在父namespace中看到,但是具有不同的pid
正是因为以上的特征,所有的LXC进程在docker中的父进程为docker进程,每个lxc进程具有不同的namespace。同时由于允许嵌套,因此可以很方便的实现 LXC in LXC
net namespace
有了 pid namespace, 每个namespace中的pid能够相互隔离,但是网络端口还是共享host的端口。网络隔离是通过netnamespace实现的,
每个net namespace有独立的 network devices, IP addresses, IP routing tables, /proc/net 目录。这样每个container的网络就能隔离开来。
LXC在此基础上有5种网络类型,docker默认采用veth的方式将container中的虚拟网卡同host上的一个docker bridge连接在一起。
ipc namespace
container中进程交互还是采用linux常见的进程间交互方法(interprocess communication - IPC), 包括常见的信号量、消息队列和共享内存。然而同VM不同,container 的进程间交互实际上还是host上具有相同pid namespace中的进程间交互,因此需要在IPC资源申请时加入namespace信息 - 每个IPC资源有一个的 32bit ID。
mnt namespace
类似chroot,将一个进程放到一个特定的目录执行。mnt namespace允许不同namespace的进程看到的文件结构不同,这样每个 namespace 中的进程所看到的文件目录就被隔离开了。同chroot不同,每个namespace中的container在/proc/mounts的信息只包含所在namespace的mount point。
uts namespace
UTS(“UNIX Time-sharing System”) namespace允许每个container拥有独立的hostname和domain name,
使其在网络上可以被视作一个独立的节点而非Host上的一个进程。
usernamespace
每个container可以有不同的 user 和 group id, 也就是说可以以container内部的用户在container内部执行程序而非Host上的用户。
有了以上6种namespace从进程、网络、IPC、文件系统、UTS和用户角度的隔离,一个container就可以对外展现出一个独立计算机的能力,并且不同container从OS层面实现了隔离。
Control Groups
cgroups 实现了对资源的配额和度量。 cgroups 的使用非常简单,提供类似文件的接口,在 /cgroup目录下新建一个文件夹即可新建一个group,在此文件夹中新建task文件,并将pid写入该文件,即可实现对该进程的资源控制。具体的资源配置选项可以在该文件夹中新建子 subsystem ,{子系统前缀}.{资源项} 是典型的配置方法,
如memory.usage_in_bytes 就定义了该group 在subsystem memory中的一个内存限制选项。
另外,cgroups中的 subsystem可以随意组合,一个subsystem可以在不同的group中,也可以一个group包含多个subsystem - 也就是说一个 subsystem。
关于术语定义
A *cgroup* associates a set of tasks with a set of parameters for one
or more subsystems.
A *subsystem* is a module that makes use of the task grouping
facilities provided by cgroups to treat groups of tasks in
particular ways. A subsystem is typically a "resource controller" that
schedules a resource or applies per-cgroup limits, but it may be
anything that wants to act on a group of processes, e.g. a
virtualization subsystem.
我们主要关心cgroups可以限制哪些资源,即有哪些subsystem是我们关心。
cpu: 在cgroup中,并不能像硬件虚拟化方案一样能够定义CPU能力,但是能够定义CPU轮转的优先级,因此具有较高CPU优先级的进程会更可能得到CPU运算。
通过将参数写入cpu.shares,即可定义改cgroup的CPU优先级 - 这里是一个相对权重,而非绝对值。当然在cpu这个subsystem中还有其他可配置项,手册中有详细说明。
cpusets: cpusets 定义了有几个CPU可以被这个group使用,或者哪几个CPU可以供这个group使用。在某些场景下,单CPU绑定可以防止多核间缓存切换,从而提高效率
memory: 内存相关的限制
blkio: block IO相关的统计和限制,byte/operation统计和限制(IOPS等),读写速度限制等,但是这里主要统计的都是同步IO
Linux 容器
- Kernel namespaces (ipc, uts, mount, pid, network and user)
- Apparmor and SELinux profiles
- Seccomp policies
- Chroots (using pivot_root)
- Kernel capabilities
- Control groups (cgroups)
LXC 向用户屏蔽了以上 kernel 接口的细节, 提供了如下的组件大大简化了用户的开发和使用工作:
- The liblxc library
- Several language bindings (python3, lua and Go)
- A set of standard tools to control the containers
- Container templates
LXC 旨在提供一个共享kernel的 OS 级虚拟化方法,在执行时不用重复加载Kernel, 且container的kernel与host共享,因此可以大大加快container的 启动过程,并显著减少内存消耗。在实际测试中,基于LXC的虚拟化方法的IO和CPU性能几乎接近 baremetal 的性能[9], 大多数数据有相比 Xen具有优势。当然对于KVM这种也是通过Kernel进行隔离的方式, 性能优势或许不是那么明显, 主要还是内存消耗和启动时间上的差异。在参考文献[10]中提到了利用iozone进行 Disk IO吞吐量测试KVM反而比LXC要快,而且笔者在device mapping driver下重现同样case的实验中也确实能得到如此结论。参考文献从网络虚拟化中虚拟路由的场景(网络IO和CPU角度)比较了KVM和LXC, 得到结论是KVM在性能和隔离性的平衡上比LXC更优秀 - KVM在吞吐量上略差于LXC, 但CPU的隔离可管理项比LXC更明确。
关于CPU, DiskIO, network IO 和 memory 在KVM和LXC中的比较还是需要更多的实验才能得出可信服的结论。
AUFS
Docker对container的使用基本是建立在LXC基础之上的,然而LXC存在的问题是难以移动 - 难以通过标准化的模板制作、重建、复制和移动 container。
在以VM为基础的虚拟化手段中,有image和snapshot可以用于VM的复制、重建以及移动的功能。想要通过container来实现快速的大规模部署和更新, 这些功能不可或缺。
Docker 正是利用AUFS来实现对container的快速更新 - 在docker0.7中引入了storage driver, 支持AUFS, VFS, device mapper, 也为BTRFS以及ZFS引入提供了可能。 但除了AUFS都未经过dotcloud的线上使用,因此我们还是从AUFS的角度介绍。
AUFS (AnotherUnionFS) 是一种 Union FS, 简单来说就是支持将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)的文件系统, 更进一步地, AUFS支持为每一个成员目录(AKA branch)设定'readonly', 'readwrite' 和 'whiteout-able' 权限, 同时AUFS里有一个类似
 图1
图1典型的Linux启动到运行需要两个FS - bootfs + rootfs (从功能角度而非文件系统角度)(图1)
bootfs (boot file system) 主要包含 bootloader 和 kernel, bootloader主要是引导加载kernel, 当boot成功后 kernel 被加载到内存中后 bootfs就被umount了.
rootfs (root file system) 包含的就是典型 Linux 系统中的 /dev, /proc, /bin, /etc 等标准目录和文件。
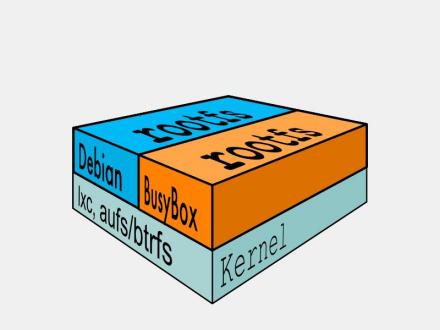 图2
图2典型的Linux在启动后,首先将 rootfs 置为 readonly, 进行一系列检查, 然后将其切换为 “readwrite” 供用户使用。在docker中,起初也是将 rootfs 以readonly方式加载并检查,然而接下来利用 union mount 的将一个 readwrite 文件系统挂载在 readonly 的rootfs之上,并且允许再次将下层的 file system设定为readonly 并且向上叠加, 这样一组readonly和一个writeable的结构构成一个container的运行目录, 每一个被称作一个Layer。如下(图3):
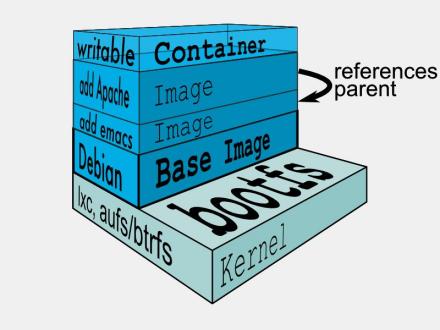 图3
图3所以docker将readonly的层称作 “image” - 对于container而言整个rootfs都是read-write的,但事实上所有的修改都写入最上层的writeable层中,
image不保存用户状态,可以用于模板、重建和复制。
(图4、5)
 图4
图4上层的image依赖下层的image,因此docker中把下层的image称作父image,没有父image的image称作base image (图6)
因此想要从一个image启动一个container,docker会先加载其父image直到base image,用户的进程运行在writeable的layer中。所有parent image中的数据信息以及ID、网络和lxc管理的资源限制等具体container的配置,构成一个docker概念上的container。如下(图7):
由此可见,采用AUFS作为docker的container的文件系统,能够提供如下好处:
 图5
图51.节省存储空间 - 多个container可以共享base image存储
2.快速部署 - 如果要部署多个container,base image可以避免多次拷贝
3.内存更省 - 因为多个container共享base image, 以及OS的disk缓存机制,多个container中的进程命中缓存内容的几率大大增加
4.升级更方便 - 相比于 copy-on-write 类型的FS,base-image也是可以挂载为可writeable的,可以通过更新base image而一次性更新其之上的container
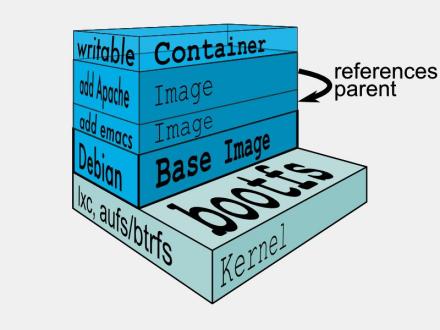 图6
图6以上5条 1-3 条可以通过 copy-on-write 的FS实现, 4可以利用其他的union mount方式实现, 5只有AUFS实现的很好。这也是为什么Docker一开始就建立在AUFS之上。
由于AUFS并不会进入linux主干 (According to Christoph Hellwig, linux rejects all union-type filesystems but UnionMount.),
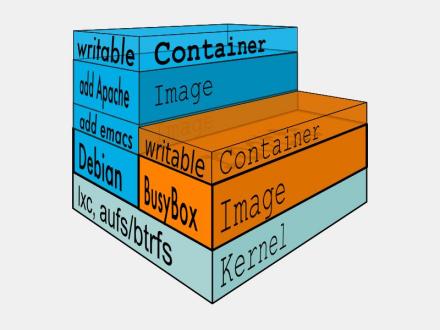 图7
图7GRSEC
grsec是linux kernel安全相关的patch, 用于保护host防止非法入侵。由于其并不是docker的一部分,我们只进行简单的介绍。
grsec可以主要从4个方面保护进程不被非法入侵:
- 随机地址空间 - 进程的堆区地址是随机的
- 用只读的memory management unit来管理进程流程, 堆区和栈区内存只包含数据结构/函数/返回地址和数据, 是non-executeable
- 审计和Log可疑活动
- 编译期的防护
安全永远是相对的,这些方法只是告诉我们可以从这些角度考虑container类型的安全问题可以关注的方面。
随着Docker在云计算市场中领先地位的日益稳固,容器技术也成为了一种主流技术。为了对用户的应用程序使用容器技术,可遵循以下五个步骤。
Docker容器技术已在云计算市场中风靡一时了,而众多主流供应商则面临着技术落后的窘境。那么,是什么让Docker容器技术变得如此受欢迎呢?对于刚入门的新手来说,容器技术可实现不同云计算之间应用程序的可移植性,以及提供了一个把应用程序拆分为分布式组件的方法。此外,用户还可以管理和扩展这些容器成为集群。
在企业用户准备把应用程序迁往容器之前,理解应用程序的迁移过程是非常重要的。这里将介绍把用户应用程序迁往Docker容器的五个基本步骤。
步骤1:
分解。一般来说,应用程序都是复杂的,它们都有很多的组件。例如,大多数应用程序都需要数据库或中间件服务的支持以实现对数据的存储、检索和集成。所以,需要通过设计和部署把这些服务拆分成为它们自己的容器。如果一个应用程序能够被拆分成为越多的分布式组件,那么应用程序扩展的选择则越多。但是,分布式组件越多也意味着管理的复杂性越高。
步骤2:
选择基础映像。当执行应用程序迁移时,应尽量避免推倒重来的做法。搜索Docker注册库找到一个基本的Docker映像并将其作为应用程序的基础来使用。
随着时间的推移,企业将会发现这些Docker注册库中基本映像的价值所在。请记住,Docker支持着一个Docker开发人员社区,所以项目的成功与否很大程度上取决于用户对于映像管理和改良的参与度。
步骤3:
安全管理问题。安全性和管理应当是一个高优先级的考虑因素;企业用户不应再把它们当作应用程序迁移至容器的最后一步。反之,企业必须从一开始就做好安全性和管理的规划,把它们的功能纳入应用程序的开发过程中,并在应用程序运行过程中积极主动地关注这些方面。这就是企业应当花大功夫的地方。
基于容器的应用程序是分布式应用程序。企业应当更新较老的应用程序以支持联合身份管理方法,这将非常有利于确保分布式应用程序的安全性。为了做到这一点,应为每一个应用程序组件和数据提供一个的标识符,这个标识符可允许企业在一个细粒度的级别上进行安全性管理。企业用户还应当增加一个日志记录的方法。
步骤4:
增加代码。为了创建镜像,企业用户需要使用一个Dockerfile来定义映像开发的必要步骤。一旦创建了映像,企业用户就应将其添加至Docker Hub。
步骤5:
配置测试部署。应对在容器中运行的应用程序进行配置,以便于让应用程序知道可以在哪里连接外部资源或者应用程序集群中的其他容器。企业用户可以把这些配置部署在容器中或使用环境变量。
对基于容器的应用程序进行测试类似于对其他分布式应用程序的测试。企业可以对每个容器进行组件测试,并将容器集群作为一个整体进行测试。 确定应用程序应如何能够在负载增加的情况下进行扩展。如果用户正在使用一个集群管理器(例如Swarm),则可测试其性能。
最后,把容器部署到实际生产环境中。为了积极主动地关注基于容器的应用程序的运行状况,可考虑实施必要的监控和管理机制 。确保打开日志记录功能。
很多应用程序迁移至云计算都是采用容器技术的。虽然迁移有一点复杂,但是容器可以保护应用程序投资并赋予了它一个更长的使用寿命。
确保环境安全
Docker十分火热,很多人表示很少见如此能够吸引行业兴趣的新兴技术。然而,当兴奋转化为实际部署时,企业需要注意Docker的安全性。
了解Docker的人都知道,Docker利用容器将资源进行有效隔离。因此容器相当于与Linux OS和hypervisor有着几乎相同的安全运行管理和配置管理级别。但当涉及到安全运营与管理,以及具有保密性、完整性和可用性的通用控件的支持时,Docker可能会让你失望。
当容器运行在本地系统上时,企业可以通过其安全规则确保安全性。但一旦容器运行在云端,事实就不会如此简单了。
当Docker运行在云提供商平台上时,安全性变得更加复杂。你需要知道云提供商正在做什么,或许你正在与别人共享一台机器。
虽然容器没有内置的安全因素,而且像Docker这样的新兴技术很难有比较全面的安全措施,但这并不意味着以后也不会出现。
部署安全性
也有专家将Docker安全问题的实质定位于配置安全,认为Docker的问题是很难配置一个安全的容器。虽然Docker的开发人员通过创建非常小的容器来降低攻击面,但问题在于大型企业内部在生产环境中运行Docker容器的员工需要有更多的可见性和可控性。
专家认为,大约90%的外部网络攻击并不是超级复杂的,攻击者多是利用了管理员的行为漏洞,比如配置错误或者未及时安装补丁。
因此,企业在部署数千或数万台容器时,能够确保这些容器都遵守企业安全策略进行配置是至关重要的事情。
Docker安全中心
在新的功能中有硬件的部分,可以 跨任何基础架构,允许开发和随后的升级中的数字编码签名。构建在Docker Trust框架之上用来进行镜像发布者认证,同时进行新的镜像扫描和官方漏洞检测,以便能够更好地理解容器内部是什么。
命名空间是本周发布的另外一个Docker安全升级。允许IT运用来为基于用户群组的容器指派授权,约束了主机的访问根源,并指定了系统管理员,限制了群组对于指定服务的访问。
镜像扫描对于Docker Hub上的所有官方版本都可用,同时命名空间和硬件签名则在Docker的实验渠道提供。
安全问题仍旧是容器采纳要解决的最大问题,尤其是如果大量容器是便携的,IDC研究经理Larry Carvalho说道。通过硬件解决这个问题很明智,因为这样更难以介入,并且提供了未来可能被使用的大量容器的效率。
对比 LXC
看似docker主要的OS级虚拟化操作是借助LXC, AUFS只是锦上添花。那么肯定会有人好奇docker到底比LXC多了些什么。无意中发现 stackoverflow 上正好有人问这个问题,
On top of this low-level foundation of kernel features, Docker offers a high-level tool with several powerful functionalities:
- Portable deployment across machines. Docker defines a format for bundling an application and all its dependencies into a single object which can be transferred to any docker-enabled machine, and executed there with the guarantee that the execution environment exposed to the application will be the same. Lxc implements process sandboxing, which is an important pre-requisite for portable deployment, but that alone is not enough for portable deployment. If you sent me a copy of your application installed in a custom lxc configuration, it would almost certainly not run on my machine the way it does on yours, because it is tied to your machine's specific configuration: networking, storage, logging, distro, etc. Docker defines an abstraction for these machine-specific settings, so that the exact same docker container can run - unchanged - on many different machines, with many different configurations.
- Application-centric. Docker is optimized for the deployment of applications, as opposed to machines. This is reflected in its API, user interface, design philosophy and documentation. By contrast, the lxc helper scripts focus on containers as lightweight machines - basically servers that boot faster and need less ram. We think there's more to containers than just that.
- Automatic build. Docker includes a tool for developers to automatically assemble a container from their source code, with full control over application dependencies, build tools, packaging etc. They are free to use make, maven, chef, puppet, salt, debian packages, rpms, source tarballs, or any combination of the above, regardless of the configuration of the machines.
- Versioning. Docker includes git-like capabilities for tracking successive versions of a container, inspecting the diff between versions, committing new versions, rolling back etc. The history also includes how a container was assembled and by whom, so you get full traceability from the production server all the way back to the upstream developer. Docker also implements incremental uploads and downloads, similar to “git pull”, so new versions of a container can be transferred by only sending diffs.
- Component re-use. Any container can be used as an “base image” to create more specialized components. This can be done manually or as part of an automated build. For example you can prepare the ideal python environment, and use it as a base for 10 different applications. Your ideal postgresql setup can be re-used for all your future projects. And so on.
- Sharing. Docker has access to a public registry (http://index.docker.io) where thousands of people have uploaded useful containers: anything from redis, couchdb, postgres to irc bouncers to rails app servers to hadoop to base images for various distros. The registry also includes an official “standard library” of useful containers maintained by the docker team. The registry itself is open-source, so anyone can deploy their own registry to store and transfer private containers, for internal server deployments for example.
- Tool ecosystem. Docker defines an API for automating and customizing the creation and deployment of containers. There are a huge number of tools integrating with docker to extend its capabilities. PaaS-like deployment (Dokku, Deis, Flynn), multi-node orchestration (maestro, salt, mesos, openstack nova), management dashboards (docker-ui, openstack horizon, shipyard), configuration management (chef, puppet), continuous integration (jenkins, strider, travis), etc. Docker is rapidly establishing itself as the standard for container-based tooling.
应用
有了docker这么个强有力的工具,更多的玩家希望了解围绕docker能做什么
Sandbox
作为sandbox大概是container的最基本想法了 - 轻量级的隔离机制, 快速重建和销毁, 占用资源少。用docker在开发者的单机环境下模拟分布式软件部署和调试,可谓又快又好。
同时docker提供的版本控制和image机制以及远程image管理,可以构建类似git的分布式开发环境。可以看到用于构建多平台image的packer以及同一作者的vagrant已经在这方面有所尝试了,笔者会后续的blog中介绍这两款来自同一geek的精致小巧的工具。
PaaS
dotcloud、heroku以及cloudfoundry都试图通过container来隔离提供给用户的runtime和service,只不过dotcloud采用docker,heroku采用LXC,cloudfoundry采用自己开发的基于cgroup的warden。基于轻量级的隔离机制提供给用户PaaS服务是比较常见的做法 - PaaS 提供给用户的并不是OS而是runtime+service,因此OS级别的隔离机制向用户屏蔽的细节已经足够。而docker的很多分析文章提到『能够运行任何应用的“PaaS”云』只是从image的角度说明docker可以从通过构建 image实现用户app的打包以及标准服务service image的复用,而非常见的buildpack的方式。
由于对Cloud Foundry和docker的了解,接下来谈谈笔者对PaaS的认识。PaaS号称的platform一直以来都被当做一组多语言的runtime和一组常用的middleware,提供这两样东西
即可被认为是一个满足需求的PaaS。然而PaaS对能部署在其上的应用要求很高:
- 运行环境要简单 - buildpack虽然用于解决类似问题,但仍然不是很理想
- 要尽可能的使用service - 常用的mysql, apache倒能理解,但是类似log之类的如果也要用service就让用户接入PaaS平台,让用户难以维护
- 要尽可能的使用"平台” - 单机环境构建出目标PaaS上运行的实际环境比较困难,开发测试工作都离不开"平台”
- 缺少可定制性 - 可选的中间件有限,难于调优和debug。
综上所述部署在PaaS上的应用几乎不具有从老平台迁移到之上的可能,新应用也难以进入参数调优这种深入的工作。个人理解还是适合快速原型的展现,和短期应用的尝试。
然而docker确实从另一个角度(类似IaaS+orchestration tools)实现了用户运行环境的控制和管理,然而又基于轻量级的LXC机制,确实是一个了不起的尝试。
笔者也认为IaaS + 灵活的orchestration tools(深入到app层面的管理 如bosh)是交付用户环境最好的方式。
国内也已经开始出现基于Docker的PaaS。2015年3月11日,云雀Alauda云平台正式开启内测,对外提供基于Docker的PaaS服务。
Open Solution
前文也提到docker存在disk/network不便限额和在较低版本kernel中(如RHEL的2.6.32)AUFS不支持的问题。
disk/network quota
虽然cgroup提供IOPS之类的限制机制,但是从限制用户能使用的磁盘大小和网络带宽上还是非常有限的。
Disk/network的quota有两种思路:
RHEL 6.5
这里简单介绍下device mapper driver的思路:
docker的dirver要利用snapshot机制,起初的fs是一个空的ext4的目录,然后写入每个layer。每次创建image其实就是对其父image/base image进行snapshot,
然后在此snapshot上的操作都会被记录在fs的metadata中和AUFS layer,docker commit将 diff信息在parent image上执行一遍.
Docker Datacenter
Docker Datacenter将五个之前独立的产品组合在一起,使用统一的Docker管理接口:管理用的Universal Control Plane;安全方面的Content Trust;编排用的Swarm;容器运行时的Engine;以及Trusted Registry。目标是填补两处空白,一处是使用Docker在开发、测试、质量保证和生产环境间打包应用,另一处是容器管理还不直接的传统IT运维。[18]
部署
1.Docker镜像
Docker 1.3 支持数字签名来确认官方仓库镜像的起源和完整性。因该功能仍在开发中所以Docker将抛出警告但不会阻止镜像的实际运行。
通常确保镜像只从受信库中检索并且不使用—insecure-registry=[]命令项。
2.网络命名空间
在默认情况下,Docker REST API用来控制容器通过系统Docker守护进程是能够通过Unix域套接字的方式暴露出来。在Docker上开启一个TCP端口(即 当引导Docker守护进程时必须使用 -H 选项绑定地址)将允许任何人通过该端口访问容器,有可能获得主机上的root访问权限以及在某些场景下本地用户所属的Docker组。
3.日志和审核
收集和归档与Docker相关的安全日志来达到审核和监督的目的。从host[8],可以使用下面的命令来访问容器外的日志文件:
docker run -v /dev/log:/dev/log/bin/sh
使用Docker命令内置:
docker logs ... (-f to follow log output)
日志文件也可以从持续存储导出到一个使用压缩包里面:
docker export ...
4.SELinux 或 AppArmor
Linux的内部安全模块,例如通过访问控制的安全策略来配置安全增强型Linux(SELinux)和AppArmor,从而实现强制性的访问控制(MAC)一套有限的系统资源的限制进程,如果先前已经安装和配置过SELinux,那么它可以使用setenforce 1在容器中被激活。Docker程序的SELinux支持是默认无效的,并且需要使用—selinux功能来被激活。通过使用新增的—security-opt来加载SELinux或者AppArmor的策略对容器的标签限制进行配置。该功能已经在Docker版本1.3[9]中介绍过。例如:
docker run --security-opt=secdriver:name:value -i -t centos bash
5.守护特权
不要使用--privileged命令行选项。这本来允许容器来访问主机上的所有设备,并为容器提供一个特定的LSM配置(例如SELinux或AppArmor),而这将给予如主机上运行的程序同样水平的访问。避免使用--privileged有助于减少主机泄露的攻击面和潜力。然而,这并不意味着程序将没有优先权的运行,当然这些优先权在最新的版本中还是必须的。发布新程序和容器的能力只能被赋予到值得信任的用户上。通过利用-u选项尽量减少容器内强制执行的权限。例如:
docker run -u-it/bin/bash
Docker组的任何用户部分可能最终从容器中的主机上获得根源。
6.cgroups
为了防止通过系统资源耗尽的DDoS攻击,可以使用特定的命令行参数被来进行一些资源限制。
CPU使用率:
docker run -it --rm --cpuset=0,1 -c 2 ...
内存使用:
docker run -it --rm -m 128m ...
存储使用:
docker -d --storage-opt dm.basesize=5G
磁盘I/O:
不支持Docker。BlockIO*属性可以通过systemd暴露,并且在支持操作系统中被用来控制磁盘的使用配额。
7.二进制SUID/GUID
SUID和GUID二进制文件不稳定的时候容易受到攻击,而这个时候是很危险的,,导致任意代码执行(如缓冲区溢出),因为它们会进程的文件所有者或组的上下文中运行。如果可能的话,禁止SUID和SGID使用特定的命令行参数来降低容器的功能。
docker run -it --rm --cap-drop SETUID --cap-drop SETGID ...
另一选择,可以考虑运用通过安装有nosuid属性的文件系统来移除掉SUID能力。
最后一个选择是从系统中彻底删除不需要的SUID和GUID二进制文件。这些类型的二进制文件可以在Linux系统中运行以下命令而找到:
find / -perm -4000 -exec ls -l {} \; 2>/dev/null
find / -perm -2000 -exec ls -l {} \; 2>/dev/null
可以使用类似于下面的[11]命令将SUID和GUID文件权限删除然后:
sudo chmod u-s filename sudo chmod -R g-s directory
8.设备控制组(/dev/*)
如果需要,使用内置的设备选项(不使用-v与--privileged参数)。此功能在推出1.2版本[12]。
例如(声卡使用):
docker run --device=/dev/snd:/dev/snd …
9.服务和应用
如果一个Docker容器有可能被泄露,为了减少横向运动的潜力,考虑隔离极易受影响的服务(如在主机或虚拟机上运行SSH服务)。此外,不要运行容器内不受信任的操作的应用程序。
10.安装项
当使用本机容器库时(即libcontainer)Docker就会自动处理这个。
但是,使用LXC容器库时,敏感的安装点最好通过运用只读权限来手动安装,其中包括:
/sys
/proc/sys
/proc/sysrq-trigger
/proc/irq
/proc/bus
安装权限应在以后删除,以防止重新挂载。
11.Linux内核
使用系统提供的更新工具来确保内核是实最新的(如apt-get,yum,等)。过时的内核可能更脆弱,并且被暴露一些漏洞。使用GRSEC或PAX来加强内核,即例如对内存破坏的漏洞来提供更高的安全性。
12.用户命名空间
Docker不支持用户的命名空间,但是的一个开发[13]功能。UID映射由LXC程序驱动,但在本机libcontainer库中不被支持。该功能将允许Docker程序像一个没有特权的用户在主机上运行,但显示出来的是和在容器中运行的一样。
13.libseccomp(和seccomp-bpf 扩展)
libseccomp库允许在基于一个白名单的方法上限制Linux内核的系统调用程序的使用。对于系统操作来说,不是很重要的系统调用程序,最好被禁用,以防止被破坏的容器被滥用或误用。
此功能工作正在进行中(LXC驱动程序中已经有了,但是在libcontainer中还没有完成,虽然是默认值)。使用LXC驱动程序[14]来重启Docker程序:
docker -d -e lxc
如何生成seccomp配置的说明都在“的contrib”[15]文件夹中的Docker GitHub的资源库。以后可以用下面的命令来创建一个基于Docker容器的LXC:
docker run --lxc-conf="lxc.seccomp=$file"
14.性能
只要可能,就将Linux性能降低到最小。Docker默认的功能包括:chown, dac_override, fowner, kill, setgid, setuid, setpcap, net_bind_service, net_raw, sys_chroot, mknod, setfcap, and audit_write.
从控制行来启动容器时,可以通过下述来进行控制:
--cap-add=[] 或者--cap-drop=[].
例如:
docker run --cap-drop setuid --cap-drop setgid -ti/bin/sh
15.多租环境
由于Docker容器内核的共享性质,责任分离在多租户环境中不能安全地实现。建议容器在那些没有其它的目的,也不用于敏感操作的主机上运行。可以考虑通过Docker控制来将所有服务移动到容器中。如果可能的话,通过使用--icc= false将跨容器通信降到最低,并必要时指定-link与Docker运行,或通过—export=port,不在主机上发布,而在容器上暴露一个端口。相互信任的容器的映像组来分离机器[17]。
16.完全虚拟化
使用一个完整的虚拟化解决方案包含Docker,如KVM。这将阻止一个内核漏洞在Docker镜像中被利用导致容器扩为主系统。
Docker镜像能够嵌套来提供该KVM虚拟层,参考Docker-in-Docker utility [18]中所示。
17.安全审核
对你的主系统和容器定期进行安全审核以查明错误配置或漏洞,这些能使你的系统损坏...
浏览更多内容请先登录。
立即注册
分享的网址网站均收集自搜索引擎以及互联网,非查问网运营,查问网并没有提供其服务,请勿利用其做侵权以及违规行为。
更新于:2021-12-11 13:29:36
相关内容
推荐内容
