转 查问我看笔记功能的实现过程之三-MYSQL8.0全文索引使用
概述:
在一堆文字中找到含有关键字的应用。当然也可以用以下语句实现:
SELECT * FROM <表名> WHERE <字段名> like ‘%ABC%’
但是它的效率太低,是全盘扫描。
Mysql 提供了更高效的方法全文索引(FULLTEXT)
重要:
Mysql 5.6之前版本,只有myisam支持全文索引,5.6之后,Innodb和myisam均支持全文索引。
只有char、varchar、text类型字段能创建全文索引。
当大量写入数据时,建议先写入数据,后再建立全文索引,提高效率。
Mysql内置ngram 解析器,可以解析中日韩三国文字。有汉字的一定要启用它。
英文分词用空格,逗号;中文分词用 ngram_token_size 设定,后面有讲解。
全文索引在引用前需要新设定下变量
均在my.ini文件中设定,在 [mysqld]的下面追加
需要将搜索短语长度设定合适
// MyISAM
ft_min_word_len = 4; 默认值
ft_max_word_len = 84; 默认值
// InnoDB
innodb_ft_min_token_size = 3; 默认值
innodb_ft_max_token_size = 84; 默认值
//ngram解析器令牌长度----即aiginst()中字符串切分的最小字符长度
ngram_token_size = 2~10 ; 默认值
一般设定:(以下例子均是假定设置如下)
在 [mysqld]的下面追加:
innodb_ft_min_token_size = 1
ft_min_word_len = 1
ngram_token_size = 1
设定好后需要关闭mysql服务,再重启mysql服务。在全文查询前,需要先将全文索引删除(如果有),再重新建。
创建全文索引
建议建表后新建
ALTER TABLE <表名> add FULLTEXT INDEX <索引名>(字段名1,字段2,,) [ WITH PARSER ngram];
全文索引查询
SELECT <字段表> FROM <表名> WHERE MATCH(字段) AGAINST (‘要搜索的关键词’ 搜索模式);
三种全文搜索模式:
自然语言模式,默认,一般省略不写
IN NATURAL LANGUAGE MODE,
例子1:
SELECT foldID,foldName FROM fold WHERE MATCH(foldName) AGAINST (‘张三’ );...
mysql数据库存入报错,好像是内容超出了Text格式的长度
Database Exception – yii\db\Exception
Error Info: Array
(
[0] => HY000
[1] => 1366
[2] => Incorrect string value: '\xE5' for column 'content_no_html' at row 1
)
↵...
mysql数据库存入报错之二,好像是内容超出了Text格式的长度
SQLSTATE[22001]: String data, right truncated: 1406 Data too long for column 'content_no_html' at row 1
The SQL being executed was: UPDATE `w_post` SET `content_no_html`='...
实测,mysql8 中文全文索引
$sql='select * from w_note where match(content_no_html) against("全文")';// 17条 // $sql="select * from w_note where match(content_no_html) against('全文')";// 17条 // $sql='select * from w_n不对额,说是双引号的含义和单引号不同,但是结果条数相同的,内容也是一样的
Mysql8全文索引查询实测-match(title) against
mysql8配置文件在[mysqld]后加下面代码
[mysqld]
#MyISAM
ft_min_word_len = 1
#InnoDB
innodb_ft_min_token_size = 1
#ngram
ngram_token_size = 1
重启了apache,然后给w_post建立索引
ALTER TABLE `w_post` ADD FULLTEXT(`title`) with parser ngram;
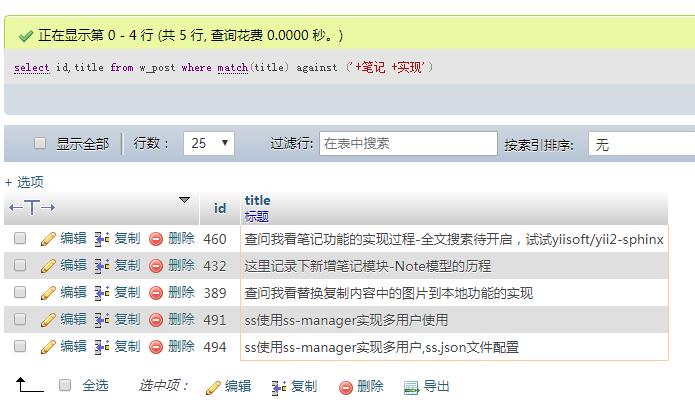
select id,title from w_post where match(title) against ('+笔记 +实现');
返回结果如下,排序前面的是包含笔记和实现的,然后是只包含笔记的,然后是只包含实现的
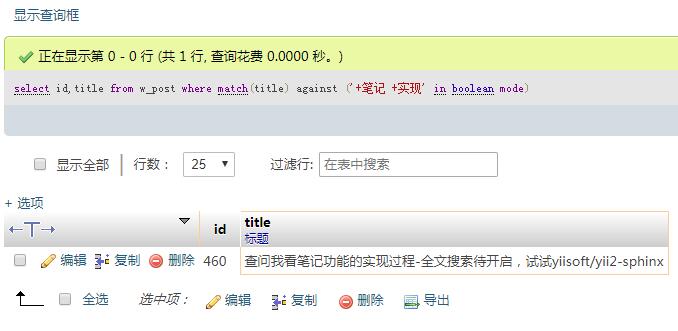
select id,title from w_post where match(title) against ('+笔记 +实现' in boolean mode);
返回结果如下,返回包含笔记和实现的。
select id,title from w_post where match(title) against ('+"笔记" & +"实现"');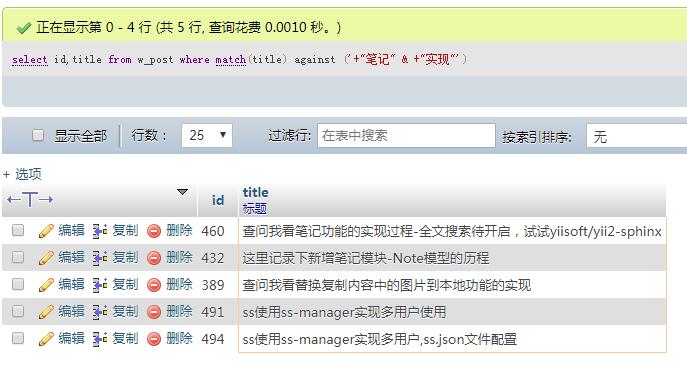
select id,title from w_post where match(title) against ('+"笔记" & +"实现"' in boolean mode);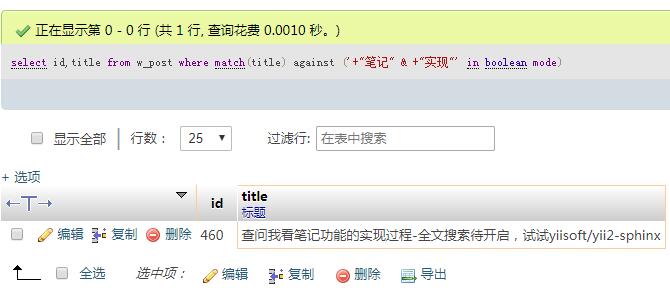
select id,title from w_post where match(title) against ('"笔记" & "实现"' in boolean mode);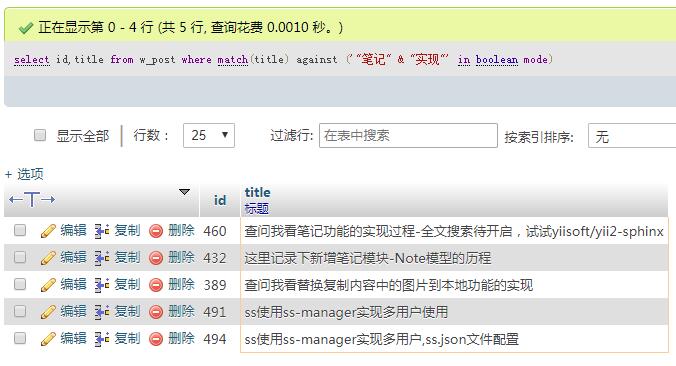 ...
...
mysql无组件中文全文索引,兼容各个版本,上亿数据亲测无压力
感觉这个思路好像不错,先切分为单个的汉字,但每个要查询的字段,都要建立一个对应的字段,数据量多了不少。20200410 2341
一直有人找我咨询全文索引问题,特别是sphinx问题。我给大家一个比sphinx更容易上手的方案:
一、原理
mysql较早版本不支持全文索引是因为字节切分问题,数据是二进制存储的,有的字符是2个字节,有的是3个或者4个,mysql无法精确的处理好切割位置。
我这个方案是定义切割字符,预先切割好数据存入数据库。
方案已经稳定使用6年,上过亿级数据,查询无压力和延时
二、直接给大家一个php语言写的案例
/*
表结构:
CREATE TABLE `full_text` (
`id` int(11) NOT NULL,
`text` mediumtext NOT NULL,
`full_index` mediumtext NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
ALTER TABLE `full_text` ADD PRIMARY KEY (`id`);
ALTER TABLE `full_text` ADD FULLTEXT KEY `full_index` (`full_index`);
ALTER TABLE `full_text` MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
*/
define('FTS',"|");
//text为原文本,full_index为全文索引
//插入数据
$text = "《唐诗三百首》选诗范围相当广泛,收录了77家诗";
$text = toUtf8($text);//UTF8并非必要
$full_index = fullTextSplit($text,true);
$insert_sql = "INSERT INTO `full_text` (`id`, `text`, `full_index`) VALUES (NULL, '".$text."', '".$full_index."')";
echo $insert_sql,"\r\n";
//查询语句
$query_field = 'full_index';//索引字段
$query_single_word = '唐诗';
$query_sql = "SELECT * FROM `full_text` WHERE ".keyword2FullTextSql($query_single_word,$query_field);
echo $query_sql,"\r\n";
$query_multi_word = '唐诗 收录';
$query_sql = "SELECT * FROM `full_text` WHERE ".keyword2FullTextSql($query_multi_word,$query_field);
echo $query_sql,"\r\n";
//索引子串
function fullTextSplit($text,$wrap = false){
if (!defined('FTS')) define('FTS', '|');
$cind = 0;
$new_text = FTS;
for($i = 0; $i < strlen($text); $i++){
if(strlen(substr($text, $cind, 1)) > 0){
if(ord(substr($text, $cind, 1)) < 192){
if(preg_match("/[a-zA-Z0-9\.]/",substr($text, $cind, 1))){
$is_numeric = preg_match("/[0-9\.]/",substr($text, $cind, 1));
if($cind $is_numeric_next){
$new_text .= substr($text, $cind, 1).FTS;
}else{
$new_text .= substr($text, $cind, 1);
}
}else{
$new_text .= FTS;
}
$cind++;
}elseif(ord(substr($text, $cind, 1)) < 224) {
$new_text .= FTS.substr($text, $cind, 2);
$cind+=2;
}else{
$new_text .= FTS.substr($text, $cind, 3).FTS;
$cind+=3;
}
}
}
$new_text = explode(FTS,$new_text);
$new_text = arrayFilter($new_text);
if($wrap){
return FTS. implode(FTS,$new_text) .FTS;
}else{
return implode(FTS,$new_text);
}
}
//查询sql
function keyword2FullTextSql($keyword,$field){
$keyword = explode('|',$keyword);
$keyword = array_unique(array_diff($keyword,array('',NULL,false)));
$keyword_sql = array();
if(!empty($keyword)){
$return = '';
foreach($keyword as $kw){
$kw = explode(' ',$kw);
$kw = array_unique(array_diff($kw,array('',NULL,false)));
if(!empty($kw)){
foreach($kw as $key => $val){
$kw[$key] = '"'.fullTextSplit($val,true).'"';
}
$keyword_sql[] = ' MATCH(`'.$field.'`) AGAINST(\'+'.implode(' +',$kw).'\' IN BOOLEAN MODE)';
}
}
}
if(!empty($keyword_sql)){
return '('. implode(" OR ",$keyword_sql) .')';
}else{
return false;
}
}
//转换编码(非必须)
function toUtf8($text,$ignore = false){
if(is_array($text)){
foreach($text as $k=>$v){
$text[$k] = toUtf8($text[$k],$ignore);
}
return $text;
}else{
$charset = mb_detect_encoding($text,array('UTF-8','ASCII','EUC-CN','CP936','BIG-5','GB2312','GBK'));
if ($charset != 'UTF-8' && !empty($charset)){
@$text = mb_convert_encoding($text, "UTF-8", $charset);
}else{
@$text = mb_convert_encoding($text, "UTF-8", 'auto');
}
if($ignore) $text = iconv('UTF-8','UTF-8//IGNORE',$text);
return preg_replace ( '/()/i', "\\1UTF-8\\3", $text, 1 );
}
}
//数组过滤
function arrayFilter($array){
$array = array_diff($array,array('',NULL,false));
return $array;
}
...
Yii2中自带分页类实现分页
Yii2中自带分页类实现分页
Yii2中自带分页类实现分页
1.首先写控制器层
先引用pagination类
use yii\data\Pagination;
写自己的方法:
function actionFenye(){ $data = Field::find(); //Field为model层,在控制器刚开始use了field这个model,这儿可以直接写Field,开头大小写都可以,为了规范,我写的是大写 $pages = new Pagination(['totalCount' =>$data->count(), 'pageSize' => '2']); //实例化分页类,带上参数(总条数,每页显示条数) $model = $data->offset($pages->offset)->limit($pages->limit)->all(); return $this->renderPartial('fenye',[ 'model' => $model, 'pages' => $pages, ]); }...
用match查询yi和yii返回结果都是0条,索引用的是ngram
mysql配置
#MyISAM
ft_min_word_len = 2
#InnoDB
innodb_ft_min_token_size = 2
#ngram
ngram_token_size = 2
索引建立的语句
ALTER TABLE `w_post` ADD FULLTEXT(`title`) with parser ngram;
//返回0条
select id,title from w_post where match(title) against ('Yii') or match(content_no_html) against ('Yii');
select id,title from w_post where match(title) against ('yii') or match(content_no_html) against ('yii');...
