|-转 Python爬虫练手,一个简单的Python资讯采集案例
在网上找的,感觉还行,收藏一下
一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采集和保存!
应用到的库
requests,time,re,UserAgent,etree
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
列表页面
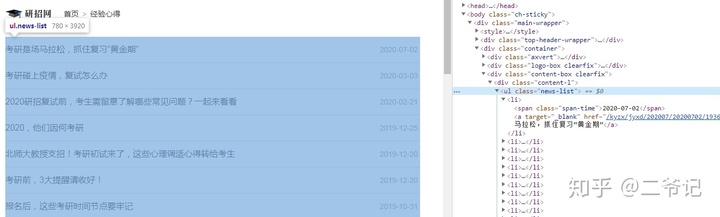
列表页,链接xpath解析
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
详情页
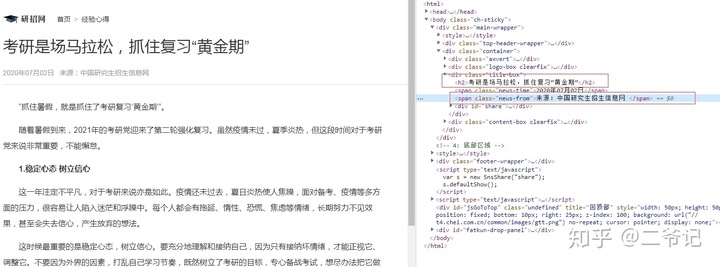
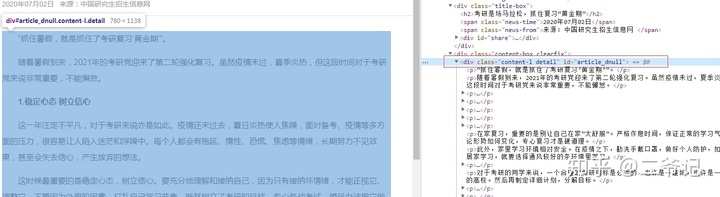
内容xpath解析
h2=req.xpath('//div[@class="title-box"]/h2/text()')[0]
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
内容格式化处理
detail='\n'.join(details)
标题格式化处理,替换非法字符
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替换为下划线
保存数据,保存为txt文本
def save(self,h2, author, detail):
with open(f'{h2}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author))
print(f"保存{h2}.txt文本成功!")
遍历数据采集,yield处理
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
程序运行效果

程序采集效果
附源码参考:
#研招网考研资讯采集
#20200710 by微信:huguo00289
# -*- coding: UTF-8 -*-
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
class RandomHeaders(object):
ua=UserAgent()
@property
def random_headers(self):
return {
'User-Agent': self.ua.random,
}
class Spider(RandomHeaders):
def __init__(self,url):
self.url=url
def parse_home_list(self,url):
response=requests.get(url,headers=self.random_headers).content.decode('utf-8')
req=etree.HTML(response)
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
print(href_list)
for href in href_list:
item = self.parse_detail(f'https://yz.chsi.com.cn{href}')
yield item
def parse_detail(self,url):
print(f">>正在爬取{url}")
try:
response = requests.get(url, headers=self.random_headers).content.decode('utf-8')
time.sleep(2)
except Exception as e:
print(e.args)
self.parse_detail(url)
else:
req = etree.HTML(response)
try:
h2=req.xpath('//div[@class="title-box"]/h2/text()')[0]
h2=self.validate_title(h2)
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
detail='\n'.join(details)
print(h2, author, detail)
self.save(h2, author, detail)
return h2, author, detail
except IndexError:
print(">>>采集出错需延时,5s后重试..")
time.sleep(5)
self.parse_detail(url)
@staticmethod
def validate_title(title):
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
def save(self,h2, author, detail):
with open(f'{h2}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author))
print(f"保存{h2}.txt文本成功!")
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
if __name__=="__main__":
url="https://yz.chsi.com.cn/kyzx/jyxd/"
spider=Spider(url)
for data in spider.get_tasks():
prin
免责声明:代码仅学习使用,勿用于非法用途...
浏览更多内容请先登录。
立即注册
更新于:2022-05-27 11:35:12
相关内容
python代码整理(2022年4月-2024年3月)
Python和PHP获取百度url跳转的真实地址代码(2022年4月实测有效)
Pip/python-如何查看已安装的包有哪些版本?如何查看某个包存在哪些版本?pip...
用undetected_chromedriver代替selenium解决浏览器打不开网页
sublime text下 Python 问题:TabError: inconsistent use of tabs and s...
WEB技术
WEB技术之前端技术
WEB技术之后端技术
WEB应用转手机APP,手机APP制作平台推荐
WEB应用与手机APP
Android相关
2017 年 Web 开发工程师技术发展路线图
session:手动删除客户端上的所有cookie,再次访问的时候为什么还是登录状态?
WEB技术之前端技术2
Python的扩展和模块安装时遇到的问题整理
windows环境下python3安装Crypto扩展
pip install 报错 ERROR: Can not execute setup.py since setuptools i...
运行python -V 报错 -bash: python: command not found
protobuf requires Python ‘>=3.7‘ but the running Python is 3.6.5的解...
推荐内容
