|-摘 Python和PHP获取百度url跳转的真实地址代码(2022年4月实测有效)
网上看了很多代码才找到能用的,上面的是Python的,下面是PHP的
import re
import requests
url = 'https://www.baidu.com/link?url=LvLG_dBUflW6_bQnGRssL5cLtpkqIJffMsdVmAiHeF8gIpu806BVDB8OfqmKFg51&wd=&eqid=c62b889a00114f8700000006625b68e5'
def get_real_url(v_url):
"""
获取百度链接真实地址
:param v_url: 百度链接地址
:return: 真实地址
"""
r = requests.get(v_url,allow_redirects=False) # 不允许重定向
if r.status_code == 302: # 如果返回302,就从响应头获取真实地址
real_url = r.headers.get('Location')
else: # 否则从返回内容中用正则表达式提取出来真实地址
real_url = re.findall("URL='(.*?)'", r.text)[0]
print('real_url is:', real_url)
return real_url
get_real_url(url)返回的结果:real_url is: https://wokan.chawen.org/post/354...
|-转 用undetected_chromedriver代替selenium解决浏览器打不开网页
整理的很完整,good,要是早看到能节省我十几个小时不止,只不过我几乎是也走了一遍试了各种办法都是失败,最后在网上搜到了用undetected_chromedriver,解决了后在考虑有时候undetected_chromedriver启动浏览器会失败的情况,搜的时候搜到了这篇文章 2024年3月10日 23:17
用undetected_chromedriver代替selenium解决浏览器打不开网页-CSDN博客
关于Python爬虫代码打开网页的方法,教科书以及前辈们都推荐requests和selenium两种途径来打开网页。
但现在越来越多网站建立反爬虫机制,比如我最近爬的一个机构网站,首页需要登录,前辈们的旧方法越来越不管用了:
方案1:requests的get和post:需要录入headers,以及post所需的表单数据。但我败在了获取post的表单数据这一步,试了很长时间都无法登录。
结果:requests方案失败。
方案2:selenium的webdriver:打开Chrome浏览器来模拟人工登录,往headers添加user-agent的代码如下:
- from selenium import webdriver
- from selenium.webdriver.chrome.options import Options
- options = webdriver.ChromeOptions()
- driver = webdriver.Chrome(options=options)
- driver.execute_cdp_cmd("Network.setExtraHTTPHeaders",
- {"headers":
- {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
- }
- })
- url=http://这里改为你要打开的网址
- driver.get(url)
浏览器显示:Chrome正受到自动测试软件的控制。某些网站已经检测到是selenium在模拟浏览器,尽管我怎么设置headers也无济于事,浏览器打开的页面不是空白,就是返回400或502等错误代码。
结果:selenium的webdriver方案失败。
方案3:浏览器按F12,打开console,输入命令:window.navigator.webdriver,如果返回True则说明网站会检测selenium的webdriver。前辈们的方法是在driver.get命令之前增加下面的代码,使得window.navigator.webdriver返回undefined:
- # 去除“Chrome正受到自动测试软件的控制”的显示
- options.add_experimental_option("excludeSwitches", ["enable-automation"])
- # 防止网站检测selenium的webdriver
- driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
- "source": """
- Object.defineProperty(navigator, webdriver, {
- get: () => undefined
- })
- """})
结果:插入undefined代码,浏览器页面依旧显示空白,失败。
方案4:改用Firefox浏览器,不用添加方案3的代码。
前辈们推荐过该方案,可能对某些网站有效,但在我要爬的机构网站还是失败。代码我就不贴了。 ...
|-转 Pip/python-如何查看已安装的包有哪些版本?如何查看某个包存在哪些版本?pip list-pip freeze-pip show package
Pip/python-如何查看已安装的包有哪些版本?如何查看某个包存在哪些版本?pip list-pip freeze-pip show package_pip查看某个包的版本-CSDN博客
目录
1.2显示指定包findstr、show、.__version__
一、如何查看已安装的包有哪些版本?
下面以pycharm中的terminal终端模式和windows系统自带的行模式为框架进行讲解。在Windows系统下,pycharm的terminal终端模式其实就是调用cmd和powershell,可以根据设置设为是调用powershell还是cmd。下图是调用powershell,
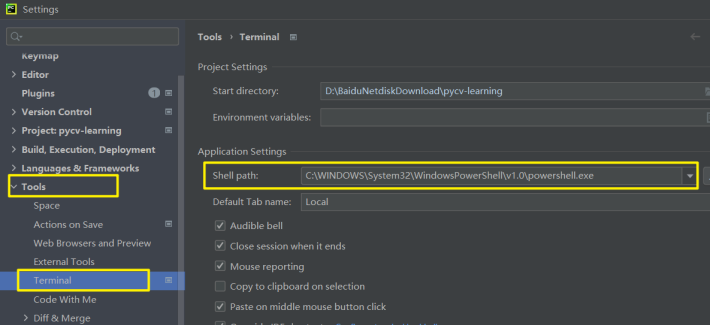
图1 更改pycharm的terminal中shell path为

图2 更改pycharm的terminal中shell path为cmd
1.在terminal终端模式或者cmd命令行模式下
1.1显示所有包pip list和pip freeze
如果已经安装的包数量不够多,可以直接使用pip list和pip freeze显示所有包及其版本。
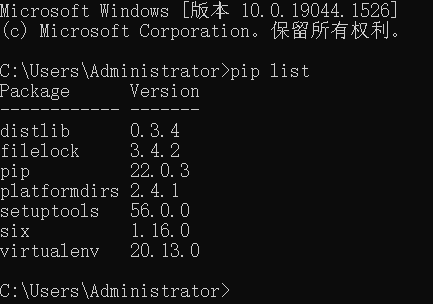
图3 在cmd黑窗口中执行pip list命令的输出结果
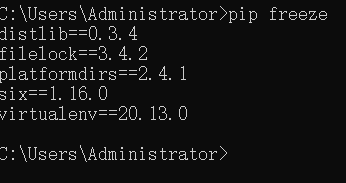
图4 在cmd黑窗口中执行pip freeze命令的输出结果
从图3和图4中可见,这两种方法得到的结果内容相同,只是显示样式不一样。
1.2显示指定包、show、.__version__
如果已安装的包很多,那么还是建议想查看什么包就指定什么包。
下面以查看已安装的numpy的版本为例,如果想看其他包,直接替换就行。
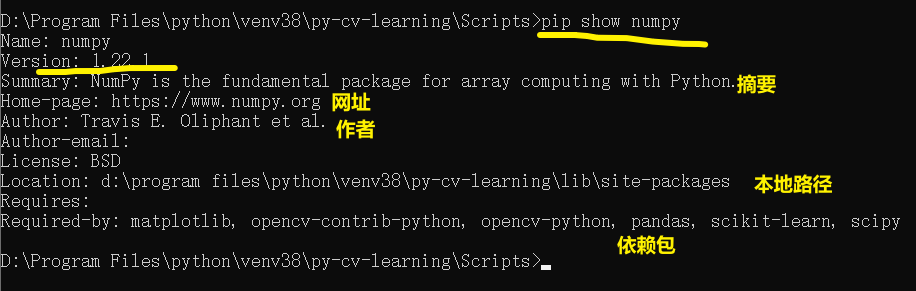
(1)pip show numpy
这个命令显示的信息很多,不仅显示了已安装包的版本,还有它的网址、简介等信息。
 ...
...
|-转 sublime text下 Python 问题:TabError: inconsistent use of tabs and spaces in indentation 缩进问题
File "G:\ST\Python\code.py", line 52 while left < right and (nums[left] == nums[left+1]): TabError: inconsistent use of tabs and spaces in indentation
怎么都搞不定,原因是自己偷懒了,从LeetCode上面复制了头部,尾部是自己手写的,方案就是全部推倒,重来,全部手写。
class Solution:
def threeSum(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
网友方案,检查subline的空格制表显示就可以清楚的显示出自己是否真的空格了。
操作:
在 text中Preferences->Settings-User中添加以下代码:
, "draw_white_space": "all"
注意:如果你的设置里面还有其他东西,你就需要添加逗号让两个不同的设置分割开来
sublime 会显示横线和点出来 ...
