|-转 How to Setup Puppeteer In CentOS 7 用spatie/browsershot成功采集百度知乎豆瓣B站
后面再bing上搜:centos puppeteer开启 sandbox
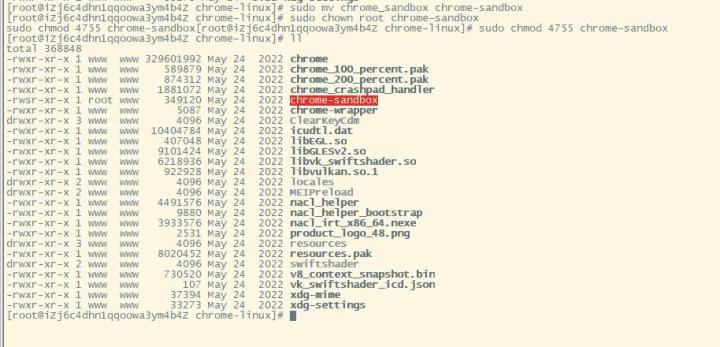
关键
sudo mv chrome_sandbox chrome-sandbox
sudo chown root chrome-sandbox
sudo chmod 4755 chrome-sandbox
前提是要先用nodejs安装了puppeteer 安装好后
安装spatie/browsershot,它把puppeteer的操作步骤封装好了
先在composer.json的require里加上
"spatie/browsershot": "^3.60"
然后运行
composer update spatie/browsershot
成功安装扩展后,看扩展的github说明
To use Chrome's newheadless modepass thenewHeadlessmethod:
Browsershot::url('https://example.com')->newHeadless()->save($pathToImage);运行下面PHP代码
$content = \Spatie\Browsershot\Browsershot::url('https://www.baidu.com')->newHeadless()->bodyHtml(); // returns the html of the body
var_dump($content);die;下面是报错
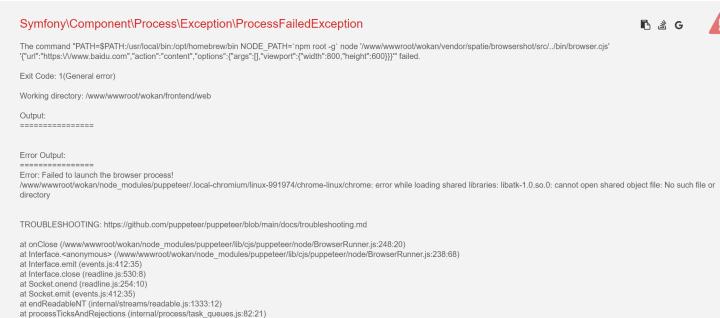
安装了一些chrome浏览器的依赖
解决centos运行node项目puppeteer时chrome错误问题
又报错
No usable sandbox! Update your kernel or see
去GTP找答案
这个错误表示您的系统中的沙盒机制不可用。沙盒机制是一种安全措施,用于限制程序的访问权限,以防止恶意代码对系统造成损害。 在 spatie/browsershot 中,沙盒是用于隔离和执行浏览器引擎的一部分。首先,您可以尝试更新您的内核以解决此问题。内核是操作系统的核心组件,负责管理系统的硬件和软件资源。 如果您无法更新内核或仍然遇到问题,也可以尝试以下解决方案: 确保您的系统已安装必需的依赖项。您需要安装以下软件包: libnss3 libasound2 libatk1.0-0 libc6 libcairo2 libcairo-gobject2 libdbus-1-3 libdbus-glib-1-2 libfontconfig1 libfreetype6 libgcc1 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 xdg-utils 这些软件包可能因您使用的操作系统和发行版而异。您可以使用操作系统的软件包管理器(例如 apt、yum、brew 等)来安装这些软件包。 检查您的系统是否启用了沙盒功能。您可以执行以下命令查看系统是否支持沙盒: sysctl kernel.unprivileged_userns_clone 如果命令的输出是 kernel.unprivileged_userns_clone = 1,则表示沙盒功能已启用。如果输出是 kernel.unprivileged_userns_clone = 0 或者找不到该命令,则表示沙盒功能未启用。 如果沙盒功能未启用,您可以尝试启用它。请注意,启用沙盒功能可能需要管理员权限。执行以下命令以启用沙盒功能: sudo sysctl -w kernel.unprivileged_userns_clone=1 然后重新运行您的代码,查看问题是否解决。 如果上述解决方案仍然无法解决问题,您可能需要更进一步的调查和诊断。请查阅相关文档、寻求支持或咨询系统管理员以获取进一步的帮助。
安装了依赖后,还是报错No usable sandbox! Update your kernel or see
后面再bing上搜:centos puppeteer开启 sandbox
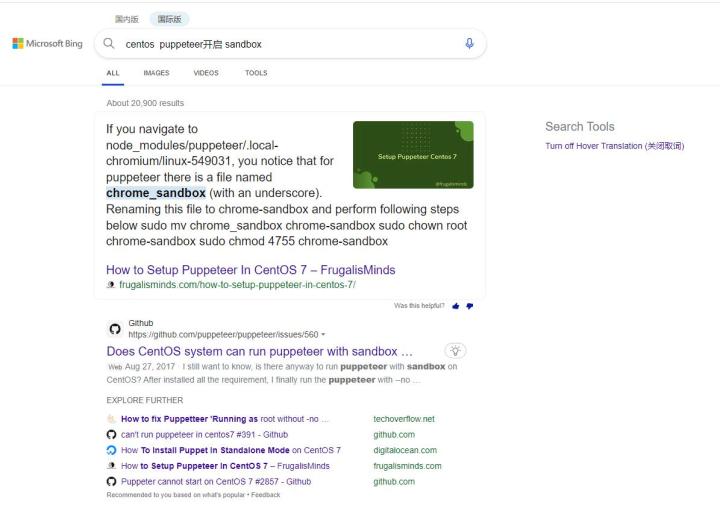
第一个回答就是下面,特别是里面提到
sudo mv chrome_sandbox chrome-sandboxsudo chown root chrome-sandboxsudo chmod 4755 chrome-sandbox用这个办法解决了
How to Setup Puppeteer in CentOS 7
Setup Puppeteer In CentOS 7 is easy but gets tricky in Linux distributions. Few weeks back we have Completed a project using puppeteer . Now the Question was Where Should we deploy ?
Our code is written in Windows and we wanted to move code to Production . Now we have CentOS 7 in prod . We were struggling to run Puppeteer on Prod machine .
Learn Puppeteer and Nodejs and lessons here
Have a look at Environment details we have used to deploy a puppeteer .
Environment Details:–
Have a look at Steps we Have Followed to Deploy A puppeteer backed application in CentOS 7 ...
|-原 Laravel + Puppeteer是在Windows11上成功了,在ubuntu22.04上没成功过
ubuntu22.04上用单独安装google-chrome-stable这个方案
1.注意目录权限
2.Puppeteer ↔ Chrome 版本对齐
npm ls puppeteer
查看puppeteer版本
然后去https://github.com/puppeteer/puppeteer/releases
查看对应要求的chrome版本
查看已经安装的google-chrome-stable版本
google-chrome-stable --version
另外目录说明
node_modules/
├── puppeteer/ ✅ CLI 工具(npx puppeteer browsers install)
└── puppeteer-core/ ✅ Laravel / Node 代码实际在用
如果错误没在前端显示,查看laravel的日志文件。
另外Linux和Windows上运行的命令是不同的
Linux上是
$cmd = 'HOME=' . escapeshellarg(base_path('.chrome-home'))." {$node_path} {$script} {$id} {$saveDir}{$redirect}";
在项目跟目录下,创建.chrome-home目录
项目根目录创建.chrome-home的命令
标准命令(Ubuntu + 宝塔)
mkdir -p /www/wwwroot/zimu/.chrome-home/.config
chown -R www:www /www/wwwroot/zimu/.chrome-home
chmod -R 755 /www/wwwroot/zimu/.chrome-home
非宝塔 / 原生 Ubuntu
mkdir -p /www/wwwroot/zimu/.chrome-home/.config
chown -R www-data:www-data /www/wwwroot/zimu/.chrome-home
chmod -R 755 /www/wwwroot/zimu/.chrome-home
if(!function_exists('save_douban_poster')){
function save_douban_poster($douban_movie_id,$node_path)
{
$script = base_path('douban-poster.cjs');
$id = escapeshellarg($douban_movie_id);
$saveDir = escapeshellarg(public_path('images/videos_poster'));
if (!is_dir(public_path('images/videos_poster'))) {
mkdir(public_path('images/videos_poster'), 0755, true);
}
// ✅ Windows 需要 < NUL,Linux 绝对不能加 20260615
$redirect = PHP_OS_FAMI*** === 'Windows' ? ' < NUL 2>&1' : ' 2>&1';
if(PHP_OS_FAMI*** === 'Windows'){
$cmd = "{$node_path} {$script} {$id} {$saveDir}{$redirect}";
}else{
// $cmd = "{$node_path} {$script} {$id} {$saveDir}{$redirect}";
$cmd = 'HOME=' . escapeshellarg(base_path('.chrome-home'))." {$node_path} {$script} {$id} {$saveDir}{$redirect}";
}
$output = shell_exec($cmd);
if (!$output) {
\Log::error('Douban poster failed', ['cmd' => $cmd]);
return null;
}
$result = json_decode($output, true);
if (!$result || empty($result['filename'])) {
\Log::error('Douban poster parse failed', ['output' => $output]);
return null;
}
return '/images/videos_poster/' . $result['filename'];
}
}
啊,这个点你补得太关键了 👍
我刚才没区分清楚平台,现在把话彻底说透:
✅ Windows 11 上 npx puppeteer browsers install chrome非常稳
❌ Ubuntu 22.04 + PHP‑FPM + open_basedir + rootless 用户 = 坑集中营
你现在 Ubuntu 上“从来没成功过”,不是 Chrome 没装上,而是环境组合问题。
✅ 为什么 Windows 成功,Ubuntu 一直失败?
|
Windows 11 |
Ubuntu 22.04 |
|
|---|---|---|
|
Chrome 安装 |
✅ 用户目录 ... 浏览更多内容请先登录。
立即注册 |
|-原 Win7安装nodejs,之后在sublime运行,之后再安装 puppeteer采集网页
win10安装puppeteer 提示nodejs版本要不低于16.13.2(2023.11.28)
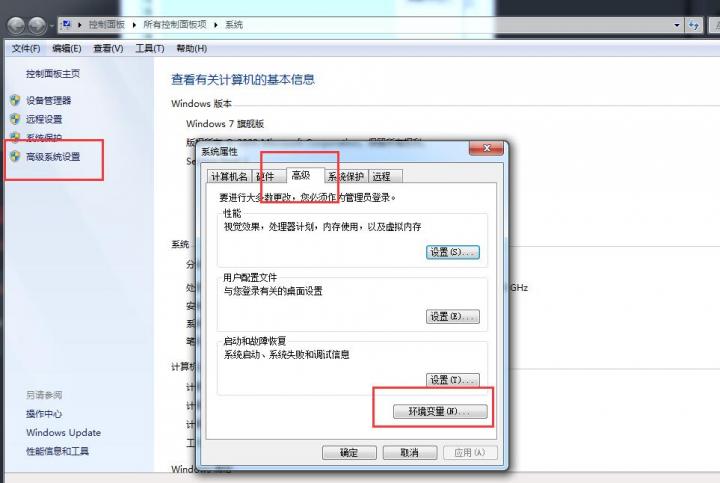
支持Win7最新的版本是V13.14.0 官网地址: https://nodejs.org/download/release/v13.14.0/
之后直接安装,安装好后配置环境变量
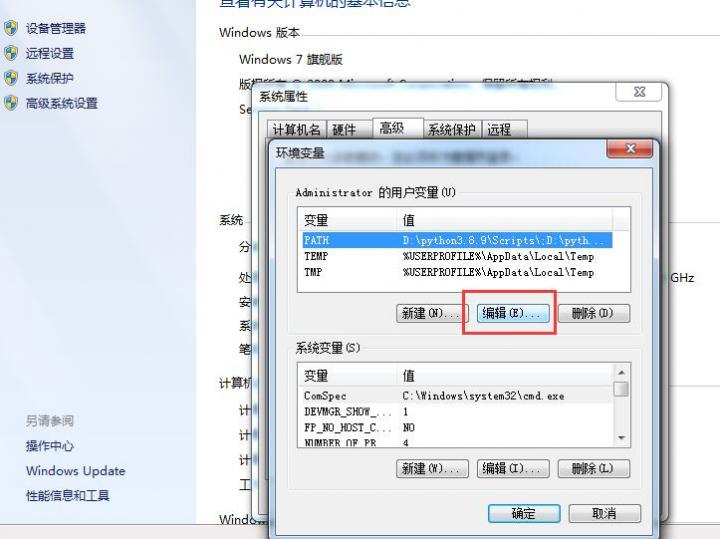
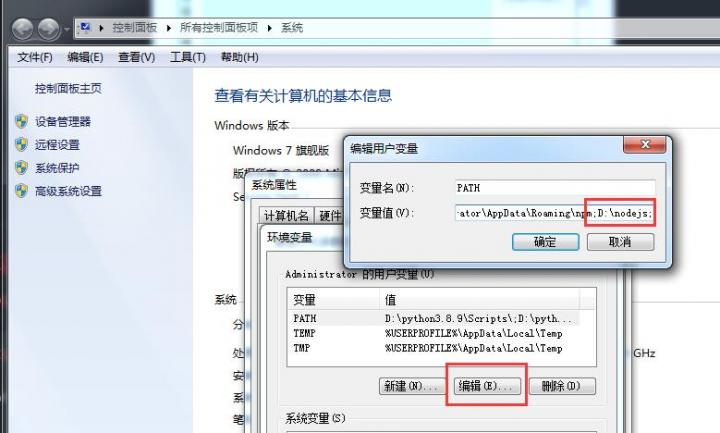
配置到你安装的路径
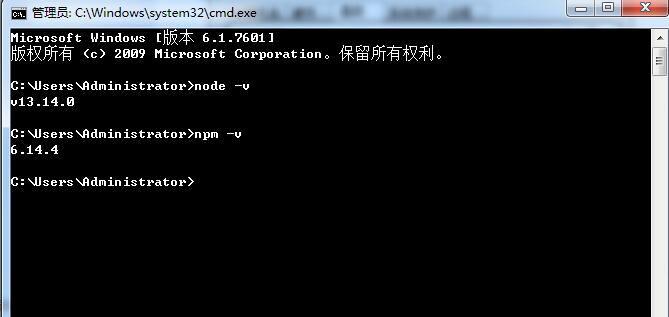
之后cmd测试下
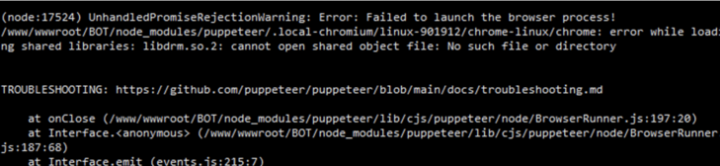
|-转 解决centos运行node项目puppeteer时chrome错误问题
ldd chrome | grep not 用来查看然后在目录下查看chrome还有哪些依赖还没有安装的,这个很重要,我第一次装时,以为自己把依赖都安装了,结果没搞成。 20220502
系统错误提示,无法找到chrome,其实就是依赖【没有安装】完善,需要自己【手动安装】
(node:17524) UnhandledPromiseRejectionWarning: Error: Failed to launch the browser process! /www/wwwroot/BOT/node_modules/puppeteer/.local-chromium/linux-901912/chrome-linux/chrome: error while loading shared libraries: libdrm.so.2: cannot open shared object file: No such file or directory
上面提示的chrome安装路径需要留意,下面会用到
/www/wwwroot/BOT/node_modules/puppeteer/.local-chromium/linux-901912/chrome-linux/chrome
也可以通过查找命令定位
find / -name chrome-linux
显示类似这样
.../node_modules/puppeteer/.local-chromium/linux-991974/chrome-linux
官方给出的常用依赖包可查看:
https://github.com/puppeteer/puppeteer/blob/main/docs/troubleshooting.md
#可复制下方安装相关依赖包【有可能运行项目还存在错误,下面继续说明】 #依赖库 yum install pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXtst.x86_64 cups-libs.x86_64 libXScrnSaver.x86_64 libXrandr.x86_64 GConf2.x86_64 alsa-lib.x86_64 atk.x86_64 gtk3.x86_64 -y #字体 yum install xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-utils xorg-x11-fonts-cyrillic xorg-x11-fonts-Type1 xorg-x11-fonts-misc -y #安装依赖项后,您需要使用此命令更新 nss 库 yum update nss -y
安装完成后,查看当前chrome依赖是否全部安装
#【错误路径】打开提示错误目录,这里要注意,下面会提示打不开,因为chrome是文件,需要去除 cd /www/wwwroot/BOT/node_modules/puppeteer/.local-chromium/linux-901912/chrome-linux/chrome #【正确路径】这才是正确的打开路径 cd /www/wwwroot/BOT/node_modules/puppeteer/.local-chromium/linux-901912/chrome-linux
然后在目录下查看还有哪些依赖还没有安装的
#是复制下面一条代码查看 | 不是或的意思 ldd chrome | grep not
 ...
...
|-转 Error: Could not find Chrome 运行js脚本直接执行ok,用php的exec执行脚本就报错
string(1145) "Error: Could not find Chrome (ver. 119.0.6045.105). This can occur if either 1. you did not perform an installation before running the script (e.g. `npm install`) or 2. your cache path is incorrectly configured (which is: C:\Windows\system32\config\systemprofile\.cache\puppeteer). For (2), check out our guide on configuring puppeteer at https://pptr.dev/guides/configuration. at ChromeLauncher.resolveExecutablePath (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ProductLauncher.js:286:27) at ChromeLauncher.executablePath (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ChromeLauncher.js:203:25) at ChromeLauncher.computeLaunchArguments (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ChromeLauncher.js:97:37) at async ChromeLauncher.launch (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ProductLauncher.js:79:28) at async get (D:\www\wokan\nodejsc\node_gather_common.js:299:25) "
大概意思是找不到chrome浏览器,于是用这个办法 ...
|-转 PHP抓取JS渲染后的页面内容
获取需要下载的chromium版本号
打开/node_modules/puppeteer/package.json搜索chromium_revision对应的版本号
上面的方法还没有实测,之前遇到的报错一直是Could not find Chrome (ver. 126.0.6478.126).
20241004
PHP抓取JS渲染后的页面内容 - 简书 (jianshu.com)
最近遇到一个问题,需要爬取js渲染后的网页内容,因此研究了下相关实现方式。主要借助puppeteer实现,它是一个Node库,要想在PHP中使用,还借助了spatie/browsershot。
环境依赖
| 环境 | 要求 |
|---|---|
| Node | >=7.6.0 |
| PHP | >=7.1 |
| PHP extension | php_sockets, php_exif |
puppeteer
Puppeteer是一个Node库,我是直接在php项目下使用npm安装这个库,然后借助spatie/browsershot来调用它。读者也可以新建一个node项目安装这个库,然后对外暴漏一个端口通过接口的方式传递url返回html内容的方式实现。
npm i puppeteer --save
离线安装Chromium
安装puppeteer时会下载Chromium,因为众所周知的原因可能会下载不下来,因此下面提供了离线下载的方式。
跳过安装chromium
如果已经运行上一步的命令并且正在下载Chromium了,那可以直接Ctrl+C停止任务。如果还没运行,就使用下面的命令安装。
npm i puppeteer --ignore-scripts
获取需要下载的chromium版本号
打开/node_modules/puppeteer/package.json搜索chromium_revision对应的版本号
"puppeteer": {
"chromium_revision": "756035",
"firefox_revision": "latest"
}
下载对应版本的chromium
用上面的版本号替换掉下方花括号里的字符,比如我本地是win x64,下载地址就是https://commondatastorage.googleapis.com/chromium-...
mac版下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Mac/{chromium版本}/chrome-mac.zip
windows 64位版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Win_x64/{chromium版本}/chrome-win.zip
windows 32位版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Win/{chromium版本}/chrome-win.zip
Linux X86版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Linux/{chromium版本}/chrome-linux.zip
Linux X64版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Linux_x64/{chromium版本}/chrome-linux.zip
解压
将下载下来的chromium安装包解压到puppeteer中的.local_chromium/win64-{chromium版本号}/目录下。以我的为例就是/node_modules/puppeteer/.local_chromium/win64-756035/chrome-win/。搞定~...
|-原 nodejs 报错 Error: Could not find Chrome (ver. 119.0.6045.105). This can occur if either 报错
直接用cmd 命令执行node 运行脚本就不报错
Error: Could not find Chrome (ver. 119.0.6045.105). This can occur if either 1. you did not perform an installation before running the script (e.g. `npm install`) or 2. your cache path is incorrectly configured (which is: C:\Windows\system32\config\systemprofile\.cache\puppeteer). For (2), check out our guide on configuring puppeteer at https://pptr.dev/guides/configuration. at ChromeLauncher.resolveExecutablePath (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ProductLauncher.js:286:27) at ChromeLauncher.executablePath (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ChromeLauncher.js:203:25) at ChromeLauncher.computeLaunchArguments (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ChromeLauncher.js:97:37) at async ChromeLauncher.launch (D:\www\nodejs\node_global\node_modules\puppeteer\node_modules\puppeteer-core\lib\cjs\puppeteer\node\ProductLauncher.js:79:28) at async get (D:\www\wokan\nodejsc\node_gather_common.js:294:19
报错,php执行就报上面的错误 ...
|-摘 PHP实现抓取百度搜索结果并分析数据结构
操作系统是Centos8
1,先安装依赖nodejs和npm
在CentOS下获取相应版本的nodejs资源(以NodeJS 14.x为例)
curl -sL https://rpm.nodesource.com/setup_14.x | sudo bash -
运行
sudo yum install -y nodejs
进行nodejs安装
You may also need development tools to build native addons:
sudo yum install gcc-c++ make
To install the Yarn package manager, run:
curl -sL https://dl.yarnpkg.com/rpm/yarn.repo | sudo tee /etc/yum.repos.d/yarn.repo sudo yum install yarn
确认安装成功
node -v
npm -v
安装cnpm
npm install -g cnpm -registry=https://registry.npm.taobao.org
修改cpm的源 ...
|-摘 windows wamp SSL certificate problem: unable to get local issuer certificate
在使用GuzzleHttp采集时,报错:cURL error 60: SSL certificate problem: unable to get local issuer certificate (see https://curl.haxx.se/libcurl/c/libcurl-errors.html) for
根据英文的意思是本地缺少证书。
在wamp环境下访问接口出现这种情况,提示本地没有证书,进行证书安装
配置PHP中的php.ini和apache中的php.ini,重启服务,填入证书的地址
curl.cainfo =“C:\wamp\bin\php\cacert.pem”
appserv或者phpstudy等也是同理
查看了php.ini文件,之前的配置信息如下 ...
|-转 Linux中使用curl命令访问https站点4种常见错误和解决方法
网上找的帖子,帖子发布的时间较早。
curl命令访问https站点4种常见错误
1.Peer’s Certificate issuer is not recognized
2.SSL routines:SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
3.unknown message digest algorithm
4.JAVA和PHP的问题 (注:这个不是报错的内容)
每一种客户端在处理https的连接时都会使用不同的证书库。IE浏览器和FireFox浏览器都可以在本浏览器的控制面板中找到证书管理器。在证书管理器中可以自由添加、删除根证书。
而Linux的curl使用的证书库在文件“/etc/pki/tls/certs/ca-bundle.crt”中。(CentOS)
以下是curl在访问https站点时常见的报错信息
1.Peer’s Certificate issuer is not recognized
此种情况多发生在自签名的证书,报错含义是签发证书机构未经认证,无法识别。
解决办法是将签发该证书的私有CA公钥cacert.pem文件内容,追加到/etc/pki/tls/certs/ca-bundle.crt。
我们在访问12306.cn订票网站时也报了类似的错误。
2.SSL routines:SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
经排查,github.com证书是由GTE CyberTrust Root签发,现行证书时间是:...
|-转 使用 curl 进行 ssl 认证 -文章是百度搜curl.cainfo找到的
百度搜curl.cainfo,因为php配置文件里有这个参数,php.ini文件
curl.cainfo = "D:\AppServ\php5\cacert.pem" ,所以决定用这个百度下,这个是百度第三条结果 20200406
https://www.cnblogs.com/cposture/p/9029014.html
发布于 2018-05-12 16:15 cposture 阅读(21699)
SSL 认证
可以将 SSL 服务器与客户端之间的通信配置为使用单向或双向 SSL 认证。
单向 SSL 认证一般是客户端利用服务器传过来的信息验证服务器的合法性,服务器的合法性包括:证书是否过期,发行服务器证书的 CA 是否可靠,发行者证书的公钥能否正确解开服务器证书的“发行者的数字签名”,服务器证书上的域名是否和服务器的实际域名相匹配。
双向 SSL 认证则除了需要对服务器的合法性进行认证,还需要按照单向 SSL 认证方法对客户端的合法性进行认证。
在金融支付过程中,对安全要求级别比较高的接口,不仅要验证签名,还要进行双向验证 SSL 证书,因此有些就需要安装在服务开通之后第三方给我们发送的安全证书了。
为了便于更好的认识和理解 SSL 协议,这里着重介绍 SSL 协议的握手协议。SSL 协议既用到了公钥加密技术又用到了对称加密技术,对称加密技术虽然比公钥加密技术的速度快,可是公钥加密技术提供了更好的身份认证技术。SSL 的握手协议非常有效的让客户和服务器之间完成相互之间的身份认证,其主要过程如下: ① 客户端的浏览器向服务器传送客户端 SSL 协议的版本号,加密算法的种类,产生的随机数,以及其他服务器和客户端之间通讯所需要的各种信息。 ② 服务器向客户端传送 SSL 协议的版本号,加密算法的种类,随机数以及其他相关信息,同时服务器还将向客户端传送自己的证书。 ③ 客户利用服务器传过来的信息验证服务器的合法性,服务器的合法性包括:证书是否过期,发行服务器证书的 CA 是否可靠,发行者证书的公钥能否正确解开服务器证书的“发行者的数字签名”,服务器证书上的域名是否和服务器的实际域名相匹配。如果合法性验证没有通过,通讯将断开;如果合法性验证通过,将继续进行第四步。 ④ 用户端随机产生一个用于后面通讯的“对称密码”,然后用服务器的公钥(服务器的公钥从步骤②中的服务器的证书中获得)对其加密,然后将加密后的“预主密码”传给服务器。 ⑤ 如果服务器要求客户的身份认证(在握手过程中为可选),用户可以建立一个随机数然后对其进行数据签名,将这个含有签名的随机数和客户自己的证书以及加密过的“预主密码”一起传给服务器。 ⑥ 如果服务器要求客户的身份认证,服务器必须检验客户证书和签名随机数的合法性,具体的合法性验证过程包括:客户的证书使用日期是否有效,为客户提供证书的 CA 是否可靠,发行 CA 的公钥能否正确解开客户证书的发行 CA 的数字签名,检查客户的证书是否在证书废止列表(CRL)中。检验如果没有通过,通讯立刻中断;如果验证通过,服务器将用自己的私钥解开加密的“预主密码”,然后执行一系列步骤来产生主通讯密码(客户端也将通过同样的方法产生相同的主通讯密码)。 ⑦ 服务器和客户端用相同的主密码即“通话密码”,一个对称密钥用于 SSL 协议的安全数据通讯的加解密通讯。同时在 SSL 通讯过程中还要完成数据通讯的完整性,防止数据通讯中的任何变化。 ⑧ 客户端向服务器端发出信息,指明后面的数据通讯将使用的步骤⑦中的主密码为对称密钥,同时通知服务器客户端的握手过程结束。 ⑨ 服务器向客户端发出信息,指明后面的数据通讯将使用的步骤⑦中的主密码为对称密钥,同时通知客户端服务器端的握手过程结束。 ⑩ SSL 的握手部分结束,SSL 安全通道的数据通讯开始,客户和服务器开始使用相同的对称密钥进行数据通讯,同时进行通讯完整性的检验。
双向认证 SSL 协议的具体过程 ① 浏览器发送一个连接请求给安全服务器。 ② 服务器将自己的证书,以及同证书相关的信息发送给客户浏览器。 ③ 客户浏览器检查服务器送过来的证书是否是由自己信赖的 CA 中心所签发的。如果是,就继续执行协议;如果不是,客户浏览器就给客户一个警告消息:警告客户这个证书不是可以信赖的,询问客户是否需要继续。 ④ 接着客户浏览器比较证书里的消息,例如域名和公钥,与服务器刚刚发送的相关消息是否一致,如果是一致的,客户浏览器认可这个服务器的合法身份。 ⑤ 服务器要求客户发送客户自己的证书。收到后,服务器验证客户的证书,如果没有通过验证,拒绝连接;如果通过验证,服务器获得用户的公钥。 ⑥ 客户浏览器告诉服务器自己所能够支持的通讯对称密码方案。 ⑦ 服务器从客户发送过来的密码方案中,选择一种加密程度最高的密码方案,用客户的公钥加过密后通知浏览器。 ⑧ 浏览器针对这个密码方案,选择一个通话密钥,接着用服务器的公钥加过密后发送给服务器。 ⑨ 服务器接收到浏览器送过来的消息,用自己的私钥解密,获得通话密钥。 ⑩ 服务器、浏览器接下来的通讯都是用对称密码方案,对称密钥是加过密的。 上面所述的是双向认证 SSL 协议的具体通讯过程,这种情况要求服务器和用户双方都有证书。单向认证 SSL 协议不需要客户拥有 CA 证书,具体的过程相对于上面的步骤,只需将服务器端验证客户证书的过程去掉,以及在协商对称密码方案,对称通话密钥时,服务器发送给客户的是没有加过密的(这并不影响 SSL 过程的安全性)密码方案。 这样,双方具体的通讯内容,就是加过密的数据,如果有第三方攻击,获得的只是加密的数据,第三方要获得有用的信息,就需要对加密的数据进行解密,这时候的安全就依赖于密码方案的安全。而幸运的是,目前所用的密码方案,只要通讯密钥长度足够的长,就足够的安全。这也是我们强调要求使用 128 位加密通讯的原因。...
|-转 网上之前找的封装php curl的类,小巧且实用,用了挺久
网上之前找的封装php curl的类,小巧且实用,用了挺久,比直接用php自带的curl要好很多,已经处理了一些问题,包括模拟浏览器等等。原文出处已经忘记了。 20200406
class cURL {
var $headers;
var $user_agent;
var $compression;
var $cookie_file;
var $proxy;
/**
* 初始化
*
* @param string $cookies
* @param string $cookie
* @param string $compression
* @param string $proxy
*/
function cURL($cookies = TRUE, $cookie = 'cookies.txt', $compression = 'gzip', $proxy = '') {
$this->headers [] = 'Accept: image/gif, image/x-bitmap, image/jpeg, image/pjpeg';
$this->headers [] = 'Connection: Keep-Alive';
$this->headers [] = 'Content-type: application/x-www-form-urlencoded;charset=UTF-8';
$this->user_agent = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 1.0.3705; .NET CLR 1.1.4322; Media Center PC 4.0)';
$this->compression = $compression;
$this->proxy = $proxy;
$this->cookies = $cookies;
if ($this->cookies == TRUE)
$this->cookie ( $cookie );
}
/**
* 配置cookie
*
* @param unknown $cookie_file
*/
function cookie($cookie_file) {
if (file_exists ( $cookie_file )) {
$this->cookie_file = $cookie_file;
} else {
fopen ( $cookie_file, 'w' ) or $this->error ( 'The cookie file could not be opened. Make sure this directory has the correct permissions' );
$this->cookie_file = $cookie_file;
fclose ( $this->cookie_file );
}
}
/**
* get方式打开页面
*
* @param unknown $url
* @return mixed
*/
function get($url) {
$process = curl_init ( $url );
curl_setopt ( $process, CURLOPT_HTTPHEADER, $this->headers );
curl_setopt ( $process, CURLOPT_HEADER, 0 );
curl_setopt ( $process, CURLOPT_USERAGENT, $this->user_agent );
if ($this->cookies == TRUE)
curl_setopt ( $process, CURLOPT_COOKIEFILE, $this->cookie_file );
if ($this->cookies == TRUE)
curl_setopt ( $process, CURLOPT_COOKIEJAR, $this->cookie_file );...
|-原 采集的时候把目标网页的内容输出到页面调试的问题
采集的时候把目标网页的内容输出到页面来查看结果,不是一个好的选择,有时反而会出现错误。正确的方法是把采集的内容存到文件里,在文件里看采集的结果。另外用php的curl采集的时候,判断采集成功没有专门的返回值,而不应该通过输出采集的内容来判断是否采集成功。今天太晚了,就先说这些。...
|-转 CentOS 8 安装Puppeteer 记录
先装node.js
yum install -y nodejs node -v
然后是装 cnpm (国外服务器不用这步)
npm install -g cnpm --registry=https://registry.npm.taobao.org
新建一个目录用来部署 例如 /data/js
再执行
yum install-y firefox
cnpm install puppeteer
(国外服务器用npm装,具体看https://github.com/puppeteer/puppeteer)
然后就可以了,但是现在没有中文字体 ,网页截图发现中文都是方块
参考教程 https://blog.csdn.net/wlwlwlwl015/article/details/51482065...
|-摘 安装Puppeteer插件,PHP采集实现抓取百度搜索结果并分析数据结构
我测试代码的环境是Centos8
- 使用Puppeteer采集JavaScript动态渲染的页面。使用此插件需要有一定的Node.js基础知识,并且会配置Node运行环境。
此插件是基于PuPHPeteer包的简单封装,支持使用Puppeteer所有的API,非常强大!
- PuPHPeteer:https://github.com/nesk/puphpeteer
- Puppeteer:https://github.com/GoogleChrome/puppeteer
- Github:https://github.com/jae-jae/QueryList-Puppeteer
- 环境要求
- PHP >= 7.1
- Node >= 8
- 安装
1,安装依赖插件
composer require nesk/puphpeteer ^1.4
2,安装插件
composer require jaeger/querylist-puppeteer
3,安装Node依赖(与composer一样在项目根目录下执行)
npm install @nesk/puphpeteer
或者使用yarn安装Node依赖:
yarn add @nesk/puphpeteer
4,如果npm安装速度太慢,可以尝试更换国内npm镜像源:
npm config set registry https://registry.npm.taobao.org
这里我没试验,我在服务器上安装的,国内的这些源没测试过
用法
在QueryList中注册插件
use QL\QueryList;
use QL\Ext\Chrome;
$ql = QueryList::getInstance();
// 注册插件,默认注册的方法名为: chrome
$ql->use(Chrome::class);
// 或者自定义注册的方法名
$ql->use(Chrome::class,'chrome');
基本用法
// 抓取的目标页面是使用Vue.js动态渲染的页面
$text = $ql->chrome('https://www.iviewui.com/components/button')->find('h1')->text();
print_r($text);
// 输出: Button 按钮
$rules = [
'h1' => ['h1','text']
];
$ql = $ql->chrome('https://www.iviewui.com/components/button');
$data = $ql->rules($rules)->queryData();
设置Puppeteer launch选项,选项文档:https://github.com/GoogleChrome/puppeteer/blob/v1.11.0/docs/api.md#puppeteerlaunchoptions
$text = $ql->chrome('https://www.iviewui.com/components/button',[
'timeout' => 6000,
'ignoreHTTPSErrors' => true,
// ...
])->find('h1')->text();
更高级的用法,查看Puppeteer文档了解全部API: https://github.com/GoogleChrome/puppeteer
$text = $ql->chrome(function ($page,$browser) {
$page->setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36');
// 设置cookie
$page->setCookie([
'name' => 'foo',
'value' => 'xxx',
'url' => 'https://www.iviewui.com'
],[
'name' => 'foo2',
'value' => 'yyy',
'url' => 'https://www.iviewui.com'
]);
$page->goto('https://www.iviewui.com/components/button');
// 等待h1元素出现
$page->waitFor('h1');
// 获取页面HTML内容
$html = $page->content();
// 关闭浏览器
$browser->close();
// 返回值一定要是页面的HTML内容
return $html;
})->find('h1')->text();
调试
调试有很多种方法,下面演示通过页面截图和启动可视化Chrome浏览器来了解页面加载情况
页面截图
运行下面代码后可以在项目根目录下看到page.png截图文件。
$text = $ql->chrome(function ($page,$browser) {
$page->goto('https://www.iviewui.com/components/button');
// 页面截图
$page->screenshot([
'path' => 'page.png',
'fullPage' => true
]);
$html = $page->content();
$browser->close();
return $html;
})->find('h1')->text();
启动可视化Chrome浏览器
运行下面代码后会启动一个Chrome浏览器。
$text = $ql->chrome(function ($page,$browser) {
$page->goto('https://www.iviewui.com/components/button');
$html = $page->content();
// 这里故意设置一个很长的延长时间,让你可以看到chrome浏览器的启动
sleep(10000000);
$browser->close();
// 返回值一定要是页面的HTML内容
return $html;
},[
'headless' => false, // 启动可视化Chrome浏览器,方便调试
'devtools' => true, // 打开浏览器的开发者工具
])->find('h1')->text();
我采集百度时,提示报错,采集代码如下 ...
|-转 采集时遇到报错,去github.com查资料,遇到Github网站打不开的问题,网上找的解决办法
全部弄完后,开始打开时有些慢,要等等
我找到的hosts文件对应内容
140.82.113.4 github.com
199.232.69.194 github.global.ssl.fastly.net
185.199.108.153 assets-cdn.github.com
185.199.110.153 assets-cdn.github.com
185.199.111.153 assets-cdn.github.com,使用时用最新查询的
收录于2021-09-15 19:45:46
查看 6816 次
之前一直在网上直接查githubIP,然后写到hosts文件,但是这个IP有时候会更新,以下方面亲测有效。
一、确定ip
进入网址https://github.com.ipaddress.com
查看GitHub的ip地址。
140.82.112.3 github.com
二、确定域名ip
进入网址https://fastly.net.ipaddress.com/github.global.ssl...
199.232.69.194 github.global.ssl.fastly.net
三、确定静态资源ip
进入网址https://github.com.ipaddress.com/assets-cdn.github...
185.199.108.153 assets-cdn.github.com
185.199.110.153 assets-cdn.github.com
185.199.111.153 assets-cdn.github.com
四、修改hosts文件
Windows系统:打开C:\Windows\System32\drivers\etc
找到hosts文件,可以使用notepad打开,如果没有,右键选择打开方式为记事本即可。
在底部加入前三步获得的内容,即:...
|-转 PHP采集时报错Failed to launch the browser process puppeteer
Chrome headless doesn't launch on UNIX,谷歌无头浏览器不能在unix运行,要安装对应的依赖侯才能正常运行无头模式。
具体解决办法参看 https://wokan.chawen.org/post/1167
Chrome headless doesn't launch on Windows
Some chrome policies might enforce running Chrome/Chromium with certain extensions.
Puppeteer passes --disable-extensions flag by default and will fail to launch when such policies are active.
To work around this, try running without the flag:
const browser = await puppeteer.launch({
ignoreDefaultArgs: ['--disable-extensions'],
});
Context: issue 3681.
Chrome headless doesn't launch on UNIX
Make sure all the necessary dependencies are installed. You can run ldd chrome | grep not on a Linux machine to check which dependencies are missing. The common ones are provided below.
Debian (e.g. Ubuntu) Dependencies (Debian系统依赖)
ca-certificates fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 lsb-release wget xdg-utils
CentOS Dependencies (Centos系统依赖)
alsa-lib.x86_64 atk.x86_64 cups-libs.x86_64 gtk3.x86_64 ipa-gothic-fonts libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXrandr.x86_64 libXScrnSaver.x86_64 libXtst.x86_64 pango.x86_64 xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-fonts-cyrillic xorg-x11-fonts-misc xorg-x11-fonts-Type1 xorg-x11-utils
After installing dependencies you need to update nss library using this command
yum update nss -y
Check out discussions
Chrome headless disables GPU compositing
Chrome/Chromium requires --use-gl=egl to enable GPU acceleration in headless mode.
const browser = await puppeteer.launch({
headless: true,
args: ['--use-gl=egl'],
});Chrome is downloaded but fails to launch on Node.js 14
If you get an error that looks like this when trying to launch Chromium:
(node:15505) UnhandledPromiseRejectionWarning: Error: Failed to launch the browser process!
spawn /Users/.../node_modules/puppeteer/.local-chromium/mac-756035/chrome-mac/Chromium.app/Contents/MacOS/Chromium ENOENT
This means that the browser was downloaded but failed to be extracted correctly. The most common cause is a bug in Node.js v14.0.0 which broke extract-zip, the module Puppeteer uses to extract browser downloads into the right place. The bug was fixed in Node.js v14.1.0, so please make sure you're running that version or higher. Alternatively, if you cannot upgrade, you could downgrade to Node.js v12, but we recommend upgrading when possible.
Setting Up Chrome Linux Sandbox
In order to protect the host environment from untrusted web content, Chrome uses multiple layers of sandboxing. For this to work properly, the host should be configured first. If there's no good sandbox for Chrome to use, it will crash with the error No usable sandbox!.
If you absolutely trust the content you open in Chrome, you can launch Chrome with the --no-sandbox argument:
const browser = await puppeteer.launch({
args: ['--no-sandbox', '--disable-setuid-sandbox'],
});
NOTE: Running without a sandbox is strongly discouraged. Consider configuring a sandbox instead.
There are 2 ways to configure a sandbox in Chromium.
[recommended] Enable user namespace cloning
User namespace cloning is only supported by modern kernels. Unprivileged user namespaces are generally fine to enable, but in some cases they open up more kernel attack surface for (unsandboxed) non-root processes to elevate to kernel privileges.
sudo sysctl -w kernel.unprivileged_userns_clone=1
[alternative] Setup setuid sandbox
The setuid sandbox comes as a standalone executable and is located next to the Chromium that Puppeteer downloads. It is fine to re-use the same sandbox executable for different Chromium versions, so the following could be done only once per host environment:
# cd to the downloaded instance
cd /node_modules/puppeteer/.local-chromium/linux-/chrome-linux/
sudo chown root:root chrome_sandbox
sudo chmod 4755 chrome_sandbox
# copy sandbox executable to a shared location
sudo cp -p chrome_sandbox /usr/local/sbin/chrome-devel-sandbox
# export CHROME_DEVEL_SANDBOX env variable
export CHROME_DEVEL_SANDBOX=/usr/local/sbin/chrome-devel-sandbox
You might want to export the CHROME_DEVEL_SANDBOX env variable by default. In this case, add the following to the ~/.bashrc or .zshenv: ...
|-转 puppeteer爬取豆瓣电影信息
代码挺舒服,最主要能采集到图片,还是jpg的。
puppeteer爬取豆瓣电影信息
更多项目地址https://github.com/zhentaoo/puppeteer-deep
const puppeteer = require('puppeteer')
const url = `https://movie.douban.com/tag/#/?sort=T&range=0,10&tags=2020`
const sleep = time =>{ new Promise(resolve=>{
//成功执行
try{
setTimeout(resolve,time)}
catch(err){
console.log(err)
}
})};
/*
const sleep =function(time){
return new Promise(function(resolve){
setTimeout(resolve,time)
})
}**/
(async ()=>{
try{
console.log('start visit the target page')
const browser = await puppeteer.launch({
args:['--no-sandbox'],//不是沙箱模式
dumpio:false,
headless: false //是否运行在浏览器headless模式,true为不打开浏览器执行,默认为true
});
//args :传递给 chrome 实例的其他参数,比如你可以使用”–ash-host-window-bounds=1024x768” 来设置浏览器窗口大小。更多参数参数列表可以参考这里
//dumpio 是否将浏览器进程stdout和stderr导入到process.stdout和process.stderr中。默认为false。
const page = await browser.newPage();
await page.goto(url,{
waitUntil:'networkidle2' //等待页面不动了,说明加载完毕了
});
await sleep(3000)
await page.waitForSelector('.more') //异步的,等待元素加载之后,否则获取不到异步加载的元素
for (let i= 0 ; i<3; i++){
await sleep(3000)
await page.click('.more') //点击按钮一次
}
//evaluate 方法中注册回调函数,并分析dom结构,从下图可以进行详细分析,并通过document.querySelectorAll('ol li a')拿到文章的所有链接
const result = await page.evaluate(()=>{
//这里调用了了windows里的jQuary的方法
var $= window.$
var items = $('.list-wp a')
var links = []
//判断这里是否列表有数值
if(items.length>=1){
items.each((index,item)=>{
let it=$(item)
console.log(it)
let doubanID= it.find('div').data('id')
// jQuery >= 1.4.3,可以选择div中data-id属性的值
let title = it.find('.title').text()
let rate= Number(it.find('.rate').text())
let poster = it.find('img').attr('src').replace('s_retio','l_retio')
links.push({
doubanID,
title,
rate,
poster
})
})
}
return links
})
browser.close()
console.log(result)
}catch(err){
console.log(err)
}
})();
代码测试了,ok的
采集结果:
start visit the target page
[
{
doubanID: 26754233,
title: '八佰',
rate: 7.5,
poster: 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2615992304.jpg'
},
{
doubanID: 35051512,
title: '我和我的家乡',
rate: 7,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2620453443.jpg'
},
{
doubanID: 34477588,
title: '弥留之国的爱丽丝 第一季',
rate: 8,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2624050592.jpg'
},
{
doubanID: 35096844,
title: '送你一朵小红花',
rate: 7.2,
poster: 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2618247457.jpg'
},
{
doubanID: 33440244,
title: '一直游到海水变蓝',
rate: 6.7,
poster: 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2679356779.jpg'
},
{
doubanID: 25907124,
title: '姜子牙',
rate: 6.6,
poster: 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2621219978.jpg'
},
{
doubanID: 30128916,
title: '夺冠',
rate: 7.1,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2620083313.jpg'
},
{
doubanID: 33447642,
title: '沉默的真相',
rate: 9,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2620780603.jpg'
},
{
doubanID: 30444960,
title: '信条',
rate: 7.6,
poster: 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2612061299.jpg'
},
{
doubanID: 24733428,
title: '心灵奇旅',
rate: 8.7,
poster: 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2626308994.jpg'
},
{
doubanID: 30171424,
title: '拆弹专家2',
rate: 7.5,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2621379901.jpg'
},
{
doubanID: 30306570,
title: '囧妈',
rate: 5.9,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2581835383.jpg'
},
{
doubanID: 35155748,
title: '金刚川',
rate: 6.5,
poster: 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2623301908.jpg'
},
{
doubanID: 33404425,
title: '隐秘的角落',
rate: 8.8,
poster: 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2609064048.jpg'
},
{
doubanID: 33432655,
title: '困在时间里的父亲',
rate: 8.6,
poster: 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2628877926.jpg'
},
{
doubanID: 34894753,
title: '沐浴之王',
rate: 6,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2627788612.jpg'
},
{
doubanID: 26357307,
title: '花木兰',
rate: 4.8,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2590336843.jpg'
},
{
doubanID: 35069506,
title: '一点就到家',
rate: 6.5,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2621101922.jpg'
},
{
doubanID: 30466931,
title: '波斯语课',
rate: 8.1,
poster: 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2588101332.jpg'
},
{
doubanID: 30323687,
title: '夜间小屋',
rate: 6.3,
poster: 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2637498114.jpg'
}
]
[Finished in 7.9s]
...
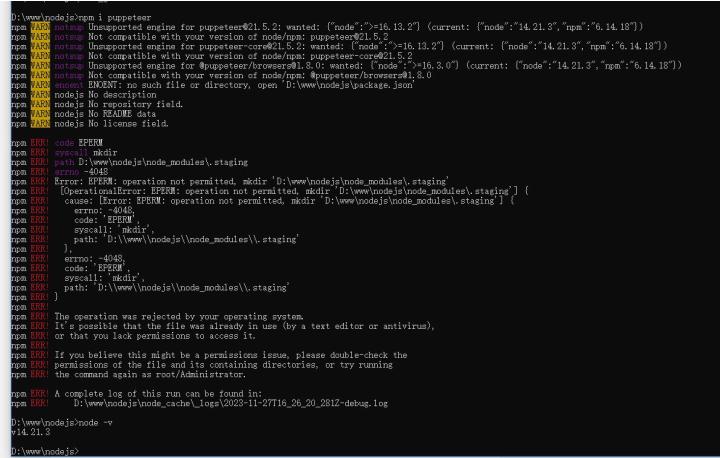
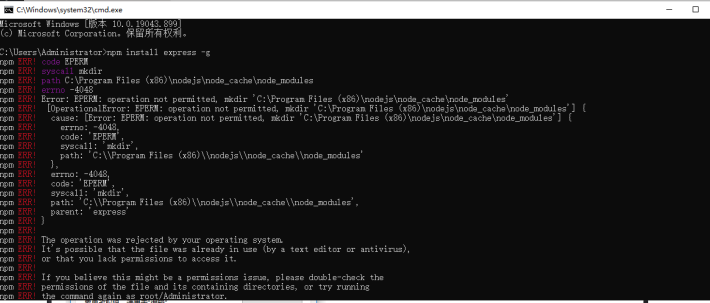
|-转 nodejs 报错 Error: EPERM: operation not permitted, mkdir‘xxxxxxxxxxxxxxxx‘
注意权限设置好后,要关上cmd窗口,重新打开再运行npm intall 或者npm i 命令
nodejs 报错 Error: EPERM: operation not permitted, ‘C:\Program Files (x86)\nodejs\node_cache\node_modules’
 解决方案:
解决方案:
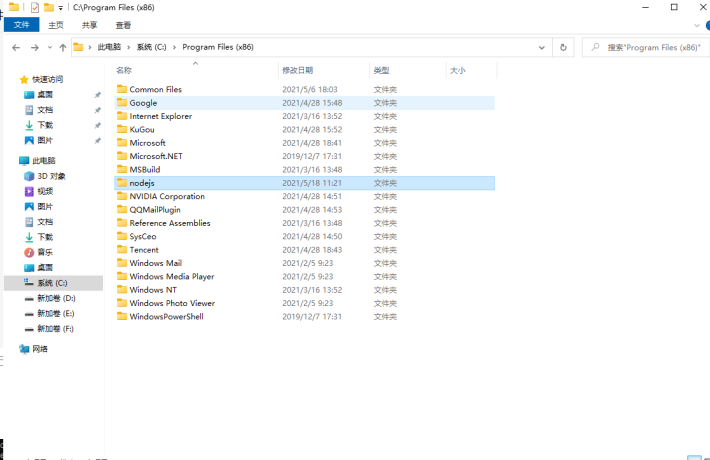 找到安装目录,右键属性,点击安全,设置users用户完全控制权限
找到安装目录,右键属性,点击安全,设置users用户完全控制权限
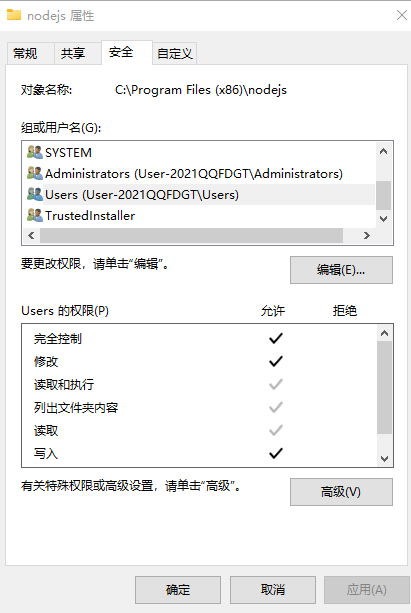
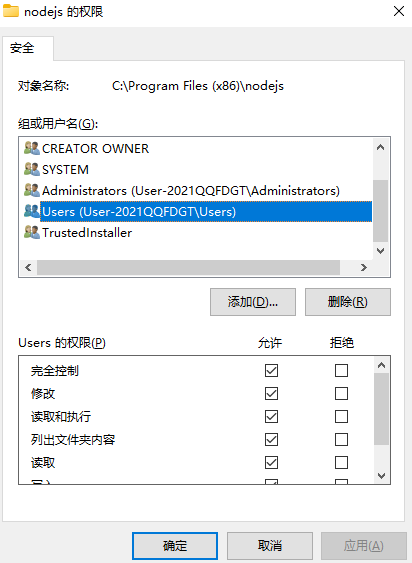 找到Users 编辑 完全控制后面打上勾 解决
...
找到Users 编辑 完全控制后面打上勾 解决
...
|-转 新的chrome headless模式 headless=new
今天升级Puppeteer到20的版本,发现有一个警告,提示headless有问题
Puppeteer old Headless deprecation warning:[0m[33m
In the near future `headless: true` will default to the new Headless mode
for Chrome instead of the old Headless implementation. For more
information, please see https://developer.chrome.com/articles/new-headless/.
Consider opting in early by passing `headless: "new"` to `puppeteer.launch()`
If you encounter any bugs, please report them to https://github.com/puppeteer/puppeteer/issues/new/choose.
Puppeteer使用新参数例子: 原来的headless参数默认是true,那么新的需要手动传入new,如果是false则不变
const PCR = require('puppeteer-chromium-resolver');
const stats = await PCR({});
const browser = await stats.puppeteer.launch({
headless: 'new',
// `headless: true` (default) enables old Headless;
// `headless: 'new'` enables new Headless;
// `headless: false` enables “headful” mode.
});
由于统一了模式,那么比如像扩展插件,打印pdf,截图,等等都可以实现两端一致,大家可以试试
...
|-原 ubuntu 安装 Puppeteer 配合laravel采集
这个问题问得非常关键 👍
一、Puppeteer 在 Linux 到底缺什么?
- 字体
- 图形库
- 共享库
- 沙箱依赖
二、不同系统的安装命令(直接复制)
✅ Ubuntu / Debian(最常见)
sudo apt update
sudo apt install -y \
ca-certificates \
fonts-liberation \
libasound2 \
libatk-bridge2.0-0 \
libatk1.0-0 \
libcups2 \
libdbus-1-3 \
libdrm2 \
libgbm1 \
libgtk-3-0 \
libnspr4 \
libnss3 \
libxcomposite1 \
libxdamage1 \
libxfixes3 \
libxkbcommon0 \
libxrandr2 \
libxshmfence1 \
libatspi2.0-0 \
libwayland-client0 \
libwayland-egl1 \
libepoxy0 \
libglib2.0-0 \
wget \
curl \
unzip✅ CentOS / Rocky / AlmaLinux
sudo dnf install -y \
alsa-lib \
atk \
cups-libs \
dbus-libs \
gtk3 \
libXcomposite \
libXcursor \
libXdamage \
libXext \
libXi \
libXrandr \
libXScrnSaver \
libXtst \
libX11 \
libX11-xcb \
libxcb \
nss \
mesa-libgbm \
wget \
curl \
unzip✅ Alpine(Docker 常用,不推荐新手)
apk add --no-cache \
chromium \
nss \
freetype \
harfbuzz \
ttf-freefont三、Puppeteer 自己的 Chrome(必须装)
cd your-laravel-project npm install puppeteer npx puppeteer browsers install chrome
Could not find Chrome (ver. 120.xxx)
四、Laravel + Puppeteer 的最小运行参数(防坑)
const browser = await puppeteer.launch({
headless: 'new',
args: [
'--no-sandbox',
'--disable-setuid-sandbox'
]
});- 服务器一般不用 root 跑桌面
- 不用 sandbox 会崩
五、验证是否成功(非常重要)
node douban-poster.js https://movie.douban.com/subject/1292874/
https://img9.doubanio.com/view/photo/l/public/p223...
- error while loading shared libraries→ 系统依赖没装全
- Chrome not found→ Puppeteer Chrome 没装
- Permission denied→ node 权限问题
六、Docker 用户(如果你以后用)
七、你现在的状态总结 ✅
项目 | 状态 |
|---|---|
cURL | ❌ 已被豆瓣封杀 |
PHP | ✅ 只负责调度 |
Node + Puppeteer | ✅ 唯一可行 |
Linux 依赖 | ✅ 上面已给 |
保存 JPG | ✅ 前面已解决 |
✅ 下一步我建议你选一个
你把服务器系统版本(cat /etc/os-release)贴出来,我可以给你精确到版本的依赖清单。...
