转 [PHP] 网盘搜索引擎-采集爬取百度网盘分享文件实现网盘搜索
测试了下,文章种用的方法不知道怎么获取到uk,现在(2020年)百度网盘的分享链接格式还有另一种:
https://pan.baidu.com/s/1o7U6SNw#list/path=/office2013
这种的也可以用https://pan.baidu.com/share/link?shareid=2434074159&uk=2651084301&fid=1039049442
下一篇主要介绍xunsearch分词和全文搜索和这次的完整代码(只找到前两篇文章,没找到第三篇文章)|不知道获取订阅用户列表的接口的这个思路现在还能不能用 20201001
百度网盘分享链接有两种格式
https://pan.baidu.com/share/link?shareid=2434074159&uk=2651084301&fid=1039049442
https://pan.baidu.com/s/1o7U6SNw#list/path=/office2013
原文链接:https://www.cnblogs.com/taoshihan/p/6798719.html
https://www.cnblogs.com/taoshihan/p/6808575.html
标题起的太大了,都是骗人的。最近使用PHP实现了简单的网盘搜索程序,并且关联了微信公众平台。用户可以通过公众号输入关键字,公众号会返回相应的网盘下载地址。就是这么一个简单的功能,类似很多的网盘搜索类网站,我这个采集和搜索程序都是PHP实现的,全文和分词搜索部分使用到了开源软件xunsearch,现在就来介绍一下实现过程。
1. 获取一批网盘用户
2. 根据网盘用户获取分享列表
3. xunsearch实现全文检索和分词检索
4. 微信公众平台接口开发
功能展示:

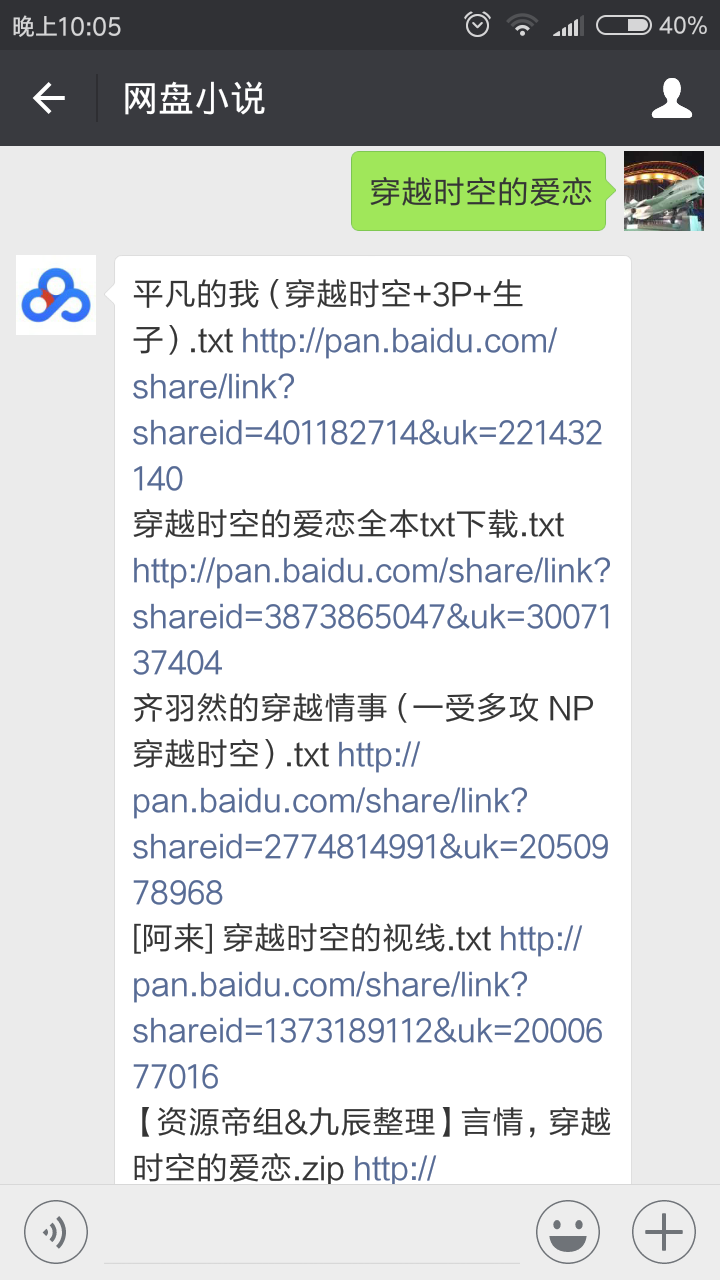
获取并采集百度网盘用户
要想获取到分享列表,首先要先把百度的用户信息收集下来,现在我来介绍如何找到一大批百度的用户。先把浏览器的审查元素打开,查看HTTP的请求包,打开自己的百度网盘主页地址https://pan.baidu.com/pcloud/home,查看订阅的用户列表,观察请求。
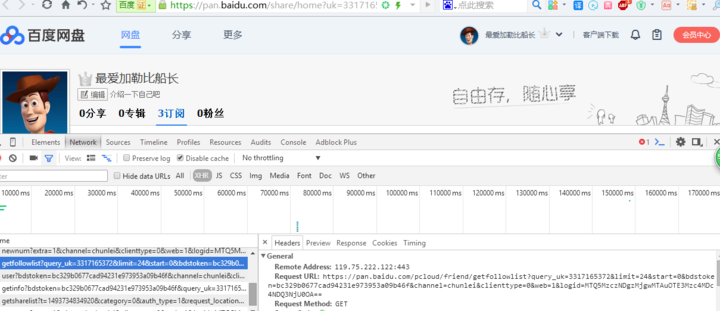
https://pan.baidu.com/pcloud/friend/getfollowlist?... 这个请求就是获取订阅用户列表的接口。
上面的参数含义分别是:query_uk (我自己的id编号,百度都是以uk来命名的) ; limit (分页时每页显示的条数) ; start (分页起始编号) ; 剩下的参数全都并无任何卵用。
精简后的接口地址是:https://pan.baidu.com/pcloud/friend/getfollowlist?query_uk={$uk}&limit=24&start={$start}
处理分页的获取订阅者接口地址
先暂时假设,我订阅了2400个用户,这个数量基本够用了。每页显示24个用户,那么就会分100页,则先看如何生成这个100个url。
<?php
/*
* 获取订阅者
*/
class UkSpider{
private $pages;//分页数
private $start=24;//每页个数
public function __construct($pages=100){
$this->pages=$pages;
}
/**
* 生成接口的url
*/
public function makeUrl($rootUk){
$urls=array();
for($i=0;$i<=$this->pages;$i++){
$start=$this->start*$i;
$url="http://pan.baidu.com/pcloud/friend/getfollowlist?query_uk={$rootUk}&limit=24&start={$start}";
$urls[]=$url;
}
return $urls;
}
}
$ukSpider=new UkSpider();
$urls=$ukSpider->makeUrl(3317165372);
print_r($urls);获取的url接口列表结果:
Array
(
[0] => http://pan.baidu.com/pcloud/friend/getfollowlist?query_uk=3317165372&limit=24&start=0
[1] => http://pan.baidu.com/pcloud/friend/getfollowlist?query_uk=3317165372&limit=24&start=24
[2] => http://pan.baidu.com/pcloud/friend/getfollowlist?query_uk=3317165372&limit=24&start=48
[3] => http://pan.baidu.com/pcloud/friend/getfollowlist?query_uk=3317165372&limit=24&start=72
[4] => http://pan.baidu.com/pcloud/friend/getfollowlist?query_uk=3317165372&limit=24&start=96
[5] => http://pan.baidu.com/pcloud/friend/getfollowlist?query_uk=3317165372&limit=24&start=120使用CURL请求接口地址
请求接口地址时,可以直接使用file_get_contents()函数,但是我这里使用的是PHP的CURL扩展函数,因为在获取分享文件列表时需要修改请求的header头信息。
此接口返回的JSON信息结构如下
{
"errno": 0,
"request_id": 3319309807,
"total_count": 3,
"follow_list": [
{
"type": -1,
"follow_uname": "热心***联盟",
"avatar_url": "http://himg.bdimg.com/sys/portrait/item/7fd8667f.jpg",
"intro": "",
"user_type": 0,
"is_vip": 0,
"follow_count": 0,
"fans_count": 21677,
"follow_time": 1493550371,
"pubshare_count": 23467,
"follow_uk": 3631952313,
"album_count": 0
},
{
"type": -1,
"follow_uname": "绾*兮",
"avatar_url": "http://himg.bdimg.com/sys/portrait/item/fa5ec198.jpg",
"intro": "万里淘金,为你推荐精品全本小说,满满的资源福利!",
"user_type": 6,
"is_vip": 0,
"follow_count": 10,
"fans_count": 5463,
"follow_time": 1493548024,
"pubshare_count": 2448,
"follow_uk": 1587328030,
"album_count": 0
},
{
"type": -1,
"follow_uname": "自**检票",
"avatar_url": "http://himg.bdimg.com/sys/portrait/item/8c5b2810.jpg",
"intro": "没事看点小说。",
"user_type": 0,
"is_vip": 0,
"follow_count": 299,
"fans_count": 60771,
"follow_time": 1493547941,
"pubshare_count": 13404,
"follow_uk": 1528087287,
"album_count": 0
}
]
}如果要做一个综合性的网盘搜索网站,就可以把这些信息全都存入数据库,现在我只是做一个很简单的小说搜索网站,因此只留下了订阅盘主的uk编号。...
