|-转 Linux终端查看最消耗CPU内存的进程
1.CPU占用最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k3|head -10
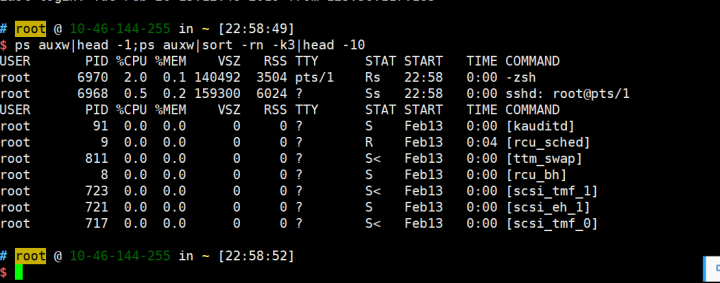
2.内存消耗最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k4|head -10
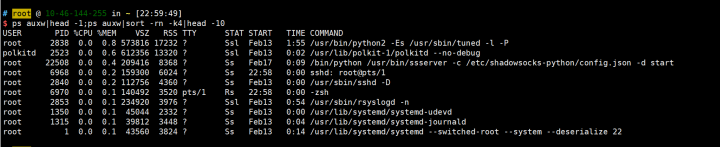
3.虚拟内存使用最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k5|head -10
 ...
...
|-转 解决Apache长时间占用内存大的问题,Apache 内存优化方法
答:用记事本打开apache2\conf\httpd.conf,
我在centos5上装了kloxo,找了半天 httpd.conf在 /etc/httpd/conf/目录下。
查找MaxRequestsPerChild,将MaxRequestsPerChild 0改成MaxRequestsPerChild 50即可。
影响apache性能的几个重要参数(conf/httpd.conf中设置)
KeepAlive 是否允许持续连接
MaxKeepAliveRequests 允许的持续连接的最大数
KeepAliveTimeout 持续连接在没有请求多少秒后切断
StartServers 最初启动时启动多少个服务器进程
MinSpareServers 空闲服务器进程的最小数
MaxSpareServers 空闲服务器进程的最大数
MaxClients 同时处理的请求数(最重要的参数,要少于ServerLimit)
MaxRequestsPerChild 每个子进程处理的最大请求数
它们之前的关系:
prefork控制进程在最初建立“StartServers”个子进程后,为了满足MinSpareServers设置的需要创建一个进程,等待一秒钟,继续创建两个,再等待一秒钟,继续创建四个……如此按指数级增加创建的进程数,最多达到每秒32个,直到满足MinSpareServers设置的值为止。这种模式可以不必在请求到来时再产生新的进程,从而减小了系统开销以增加性能。MaxSpareServers设置了最大的空闲进程数,如果空闲进程数大于这个值,Apache会自动kill掉一些多余进程。这个值不要设得过大,但如果设的值比MinSpareServers小,Apache会自动把其调整为MinSpareServers+1。如果站点负载较大,可考虑同时加大MinSpareServers和 MaxSpareServers。MaxRequestsPerChild设置的是每个子进程可处理的请求数。每个子进程在处理了 “MaxRequestsPerChild”个请求后将自动销毁。0意味着无限,即子进程永不销毁。虽然缺省设为0可以使每个子进程处理更多的请求,但如果设成非零值也有两点重要的好处:1、可防止意外的内存泄漏。2、在服务器负载下降的时侯会自动减少子进程数。
ServerLimit 2000
StartServers 10
MinSpareServers 10
MaxSpareServers 15
MaxClients 1000
MaxRequestsPerChild 2048
调试过程中用到的指令:
# ps -ef|grep http|wc -l //查看请求总数
# cat /proc/loadavg //查看平均负载(loadavg),loadavg高于1,表明任务队列出现了等待,CPU忙不过来了。超过2以上就会明显感到性能降低了
# netstat -ant | grep :80 | wc -l //查看TCP连接数
# top //查看系统运行情况
====================================================================
apache的内存使用
apache进程在使用内存时,是“渐长”的。也就是说,直到这个进程死掉,使用内存的数量是一直增长而不会减少的。这样的话,apache进程使用内存的多少,就决定于你的应用程序最大使用内存量了。
keepalive参数
KeepAliveTimeout 这个参数决定了,在什么都不做之前,一个http进程能够等待多长时间?设想一下,如果keepalive设置为on,而 keepalivetimeout设置为一个比较大的数字,apache占用内存会很快的增长。这是因为,一个apache进程完成了一个任务(并达到了一定的内存占用,想一下“渐进”模式),并不会马上退出,而是等待一个keepalivetimeout时间。假设用户的链接请求持续不断的到来,则积累起来的无用的apache进程就会相当多,直到timeout,这些进程才会被杀死。
但是,keepalive的确对于静态的文件,比如图像文件的传送是很有效的,因此,keepalive要设置为on,(off)但是keepalvietimeout要设置的小些,比如5s 15
MaxRequestsPerChild
这个参数是说,apache进程在处理了多少个请求之后,必须退出,重新开始,以免在处理中的内存问题。
对于php脚本来说,把这个参数设置的小一些是有好处的,可以避免程序使用的内存持续增长对apache带来的压力:让这个参数定期释放内存,因为php是在脚本执行完毕后,自动释放只用的资源(内存)的。
比如设置为50?如果太小的话,重新产生一个apache进程也是要消耗资源的,这是一个平衡问题。
有一台服务器 IBM P550 小型机上的 IHS 在连续运行几天后,其中的一个 httpd 进程占用内存接近几百兆。
IHS 其实就是 Apache ,AIX 5.3 下运行在 worker 方式下,它被看作 Apache 未来的主流工作模式,它是一种多进程与多线程混合的模式。
Apache的主流工作模式MPM模式。MPM是Multi-Processing-Modules的简称,意思是多道处理模块。MPM模块有不同的种类。现在用的比较多的MPM种类主要是prefork和worker。prefork的工作方式是多个进程工作,每个进程会在处理一定数量的请求后结束(这个数量可能是无穷),没有线程的概念。worker被看作apache未来的主流工作模式,它是一种多进程与多线程混合的模式。
配置文件 httpd.conf 中 work 的参数配置项:
<IfModule worker.c>
ThreadLimit 100
ServerLimit 250
StartServers 8
MaxClients 25600
MinSpareThreads 100
MaxSpareThreads 300
ThreadsPerChild 100
MaxRequestsPerChild 0
</IfModule>
关键的问题出现在 MaxRequestsPerChild 参数。MaxRequestsPerChild这个指令设定一个独立的子进程将能处理的请求数量。
在处理“MaxRequestsPerChild 数字”个请求之后,子进程将会被父进程终止,这时候子进程占用的内存就会释放,如果再有访问请求,父进程会重新产生子进程进行处理。
如果MaxRequestsPerChild缺省设为0(无限)可以使每个子进程处理更多的请求,不会因为不断终止、启动子进程降低访问效率。
但如果占用了200~300M内存,即使负载下来时占用的内存也不会减少。内存较大的服务器可以设置为0或较大的数字。内存较小的服务器不妨设置成30、50、100,以防内存溢出。...
|-转 生产出现oom(out of memory)问题,怎么排查?
ucloud上报工单,out of memory killed process 2480 (httpd),IT回复了这篇文章作为参考
https://www.cnblogs.com/c-xiaohai/p/12489336.html
1、使用dmesg命令查看系统日志
dmesg |grep -E ‘kill|oom|out of memory’,可以查看操作系统启动后的系统日志,这里就是查看跟内存溢出相关联的系统日志。
2、这时候,需要启动项目,使用ps命令查看进程
ps -aux|grep java命令查看一下你的java进程,就可以找到你的java进程的进程id。
3、接着使用top命令
top命令显示的结果列表中,会看到%MEM这一列,这里可以看到你的进程可能对内存的使用率特别高。以查看正在运行的进程和系统负载信息,包括cpu负载、内存使用、各个进程所占系统资源等。
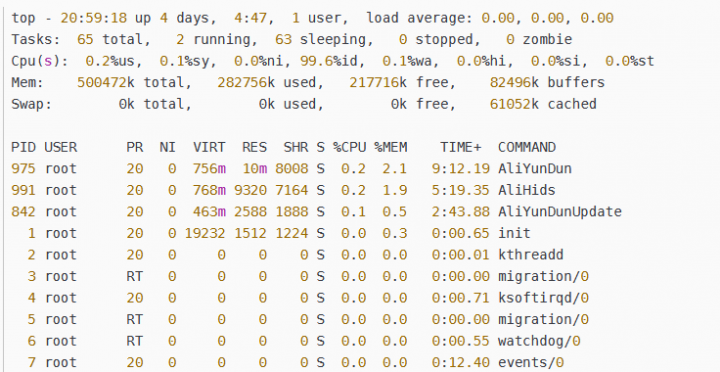
4、使用jstat命令
用jstat -gcutil 20886 1000 10命令,就是用jstat工具,对指定java进程(20886就是进程id,通过ps -aux | grep java命令就能找到),按照指定间隔,看一下统计信息,这里会每隔一段时间显示一下,包括新生代的两个S0、s1区、Eden区,以及老年代的内存使用率,还有young gc以及full gc的次数。
使用 jstat -gcutil 8968 500 5 表示每500毫秒打印一次Java堆状况(各个区的容量、使用容量、gc时间等信息),打印5次
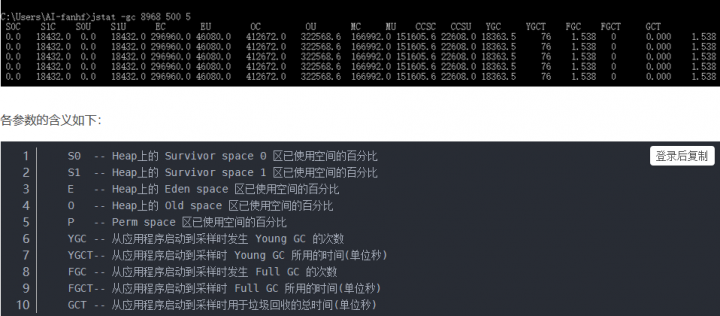
例如:
看到的东西类似下面那样:
S0 S1 E O YGC FGC
26.80 0.00 10.50 89.90 86 954
其实如果大家了解原理,应该知道,一般来说大量的对象涌入内存,结果始终不能回收,会出现的情况就是,快速撑满年轻代,然后young gc几次,根本回收不了什么对象,导致survivor区根本放不下,然后大量对象涌入老年代。老年代很快也满了,然后就频繁full gc,但是也回收不掉。
然后对象持续增加不就oom了,内存放不下了,爆了呗。
所以jstat先看一下基本情况,马上就能看出来,其实就是大量对象没法回收,一直在内存里占据着,然后就差不多内存快爆了。
5、使用jmap命令查看
执行jmap -histo pid可以打印出当前堆中所有每个类的实例数量和内存占用,如下,class name是每个类的类名([B是byte类型,[C是char类型,[I是int类型),bytes是这个类的所有示例占用内存大小,instances是这个类的实例数量。
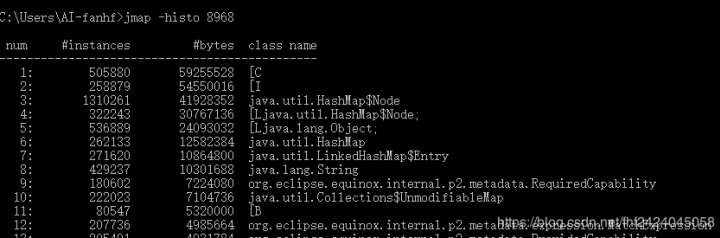
6、把当前堆内存的快照转储到dumpfile_jmap.hprof文件中,然后可以对内存快照进行分析
使用jmap -dump:format=b,file=文件名[pid],就可以把指定java进程的堆内存快照搞到一个指定的文件里去,但是jmap -dump:format其实一般会比较慢一些,也可以用gcore工具来导出内存快照
例如:jmap -dump:format=b,file=D:/log/jvm/dumpfile_jmap.hprof20886
接着就是可以用MAT工具,或者是Eclipse MAT的内存分析插件,来对hprof文件进行分析,看看到底是哪个王八蛋对象太多了,导致内存溢出了

或者使用jdk的目录下的bin目录下的:jvisualvm.exe
8、总结:
一般常见的OOM,要么是短时间内涌入大量的对象,导致你的系统根本支持不住,此时你可以考虑优化代码,或者是加机器;要么是长时间来看,你的很多对象不用了但是还被引用,就是内存泄露了,你也是优化代码就好了;这就会导致大量的对象不断进入老年代,然后频繁full gc之后始终没法回收,就撑爆了...
