|-转 NLP入门——从0到实现文本分类
https://zhuanlan.zhihu.com/p/77726136
读了后有些启发,原作者为了比赛看了不少资料,特别是还找到了谷歌的免费GPU资源,来解决训练模型算力不够的问题。他自己写的利用GPU的文章已经不见了。我自己网上找了个:https://blog.csdn.net/edmond999/article/details/122577420 Google Colab和Kaggle搭配使用
暑假酷暑难耐,需要寻找一种方式让自己时刻感到凉爽,正巧,科大讯飞推出大数据应用分类标注挑战赛,我就报名参加了。本人以前没接触过NLP,所以做比赛时前期分数很难上去,心拔凉拔凉的。
先大致说下比赛是干什么的吧,本次比赛要求参赛者根据app的应用描述信息给出app的分类,说白了就是文本分类问题。官方给的训练集样例如下。

OK,交代了比赛的背景,下面我先大致说下为什么我要写下这篇文章,通过这篇文章你能获得什么,然后就是本文的重头戏——从0到实现文本分类(真的不需要你有NLP基础哦)。
1. 我为什么要写下这篇文章
这个比赛是我做的第一个完整的比赛,从7月3号到现在一直都在做,现在初赛结束了,目前排名第4。
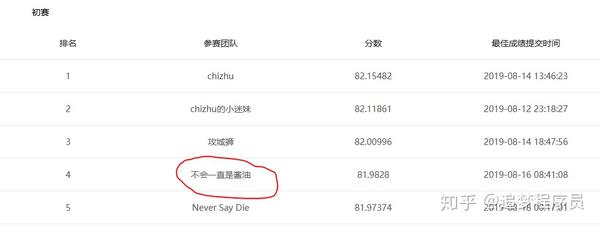
用心付出的事物总是值得回味,所以我写下了这篇文章,记录比赛经历和一些心得体会,希望对后来者有所帮助,也激励自己前进。
我将大致分享如下东西:
- 比赛过程中代码和数据如何整理。
- 缺少计算资源,如何使用免费的GPU计算资源。
- 文本分类算法。从传统机器学习到深度学习,到最近的NLP利器bert模型。
你从本文能获得什么:
- 大量的有用资料。我在比赛的过程中,不断的进行学习,期间阅读了许多优秀的文章(有算法原理、实战教程),我将会在文中分享给你。
- NLP知识和文本分类算法。
- 比赛过程中的注意事项。我踩过的炕你就不要再踩了。
我的整个分享将结合比赛以实现文本分类为主线,从机器学习到深度学习,再到bert。其中关于“比赛过程中代码和数据如何整理”、“缺少计算资源,如何使用免费的GPU计算资源”,“比赛过程中的注意事项”等话题将穿插其中。
好了,下面我们就正式开始吧。
2. 传统机器学习实现文本分类
首先我们要明白这个问题属于机器学习的哪一类问题,很显然,这属于有监督学习中的分类问题。传统机器学习分类器有SVM、决策树、逻辑回归等,都可以尝试下。
假设我们现在选择逻辑回归作为分类器模型,现在就应该把我们的训练数据喂给分类器,wait,原始训练数据都是中文,不可能直接喂给LR,因为我们的LR等分类器只认识数字。
好了,第一个问题来了,怎么把一行中文文本数字化?
如何将文本数字化是NLP领域的基础工作,也是多数任务的第一步。据我了解,将文本数字化的技术大致分为向量空间模型和文本的分布式表示。下面我将详细介绍这两种技术。
2.1 文本数字化——向量空间模型
向量空间模型要做的事情就是将一行文本转换为一个向量。其中典型的技术有词袋模型、TF-IDF(词频逆文档频率)模型。
为了简单易懂,我们拿“我是天才,我爱读书”、“你是帅哥,你爱美女”这两句话来说明模型如何向量化文本。
一段话是由多个词组成的,要想把一段话转换为一个向量,我们首先需要给词进行编码。给单词编码一般采用one-hot编码(独热编码),其思想就是给每个不同的单词一个唯一对应的数字。
比如,“我是天才,我爱读书”可以看成由“我”、“是”、“天才”、“我”、“爱”、“读书”这6个词组成的序列。
我”编码为1、“是”编码为2、“天才”编码为3、“爱”编码为4、“读书”编码为5。
同样的,“你是帅哥,你爱美女”可以看成由“你”、“是”、“帅哥”、“你”、“爱”、“美女”这6个词组成的序列。
“你”编码为6,“帅哥”编码为7,“美女”编码为8。
现在假设不同单词的个数为n,我们可以用1到n的自然数来编码这n个不同的单词,为了向量化文本,我们用一个n维的向量表示一段话,向量中的n个位置表示该编码的单词在文本中的权重。
“我是天才,我爱读书”、“你是帅哥,你爱美女”这两段话总共有8个不同的单词,我们看可以用8维的向量表示每一句话。
“我是天才,我爱读书”可以向量化为 [2, 1,1,1,1,0,0,0]。在“我是天才,我爱读书”这段话中,“我”出现了两次,并且“我”的编码为1,所有向量的第一个位置的值为2。...
