|-转 一人搞定30万商品分类:AI落地实践中的故事
传统的关键字匹配不合适,比如葡萄,葡萄干,葡萄糖,葡萄石就是四种品类。 传统的NLP处理也有局限性,且需要重新训练。
使用 M3E 您需要先安装 sentence-transformers
基于真实需求,让AI落地,使用embedding模型做大数据量分类。
为数十万商品分类通常想到的办法是用NLP+特定分类算法(如是SVM)来实现,涉及数据清洗,特征提取,模型训练,调试和集成等工作。看起来是项大工程。 借助现有AI的能力,可以加速实现。本文是基于真实需求场景的探索和回顾。
背景
近期遇到一个做电商的朋友需求,他们的电商平台上有几十万商品,上千种商品品类。而商品品类的划分数据来自多个电商平台,标准描述不统一,分类也有出错的情况,需要对所有商品品类做一个统一的梳理。梳理商品品类的工作由人工完成的话,会很耗时费力。期望借助AI的能力帮忙梳理已有商品品类的划分,而且对于新加入的商品,能自动为其分类。
传统的关键字匹配不合适,比如葡萄,葡萄干,葡萄糖,葡萄石就是四种品类。 传统的NLP处理也有局限性,且需要重新训练。
另外,还有限制条件:
- 商品名主要是中文
- 只能在内网使用
- 没有性能强大(更别提GPU)的服务器
思路
首先想到的是微调一个4bit量化的中文LLM,来实现输入商品名,返回商品二级和一级分类。
已知:
- ChatGLM3 4bit模型在一般的CPU服务器,16GB内存情况下是能跑起来。
- 需要准备500到1000条高质量,覆盖面广的训练数据。
- 需要调教和控制输出格式。
实测下来,4bit LLM能力有限,输出的准确度和格式的一致性不能保证。需要多次“炼丹”,结果还不能保证达到想要的效果。
换个思路,我们要解决传统关键字匹配的问题,本质上是语义的匹配。在以前做知识库问答的过程中用到的embeddings不就是实现了语义的匹配吗?前述的商品分类需求中,并不涉及语言理解和逻辑推理,那其实可以不用LLM。是不是只需要embedding模型就能实现了?
嵌入式模型(Embedding)是一种广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域的机器学习模型,它可以将高维度的数据转化为低维度的嵌入空间(embedding space),并保留原始数据的特征和语义信息,从而提高模型的效率和准确性
说人话,嵌入式模型就是把词或句用多维向量来表示,向量之间的距离表示语义的相近程度。向量之间的距离越短,表示语义越接近。比如“土豆”->[0,1,2],“马铃薯”->[0,1,1],“土狗”->[1,0,0]。 比较[0,1,2]与[0,1,1]的距离要小于[0,1,2]与[1,0,0]的距离,得出结论“土豆”表达的意思与“马铃薯”更接近。
上面的例子中只是一个3维向量,而实际可用的嵌入式模型中,维度要大得多,比如OpenAI提供的Embeddings接口支持1536维度,开源的中文embeddings中m3e-base支持768维度。
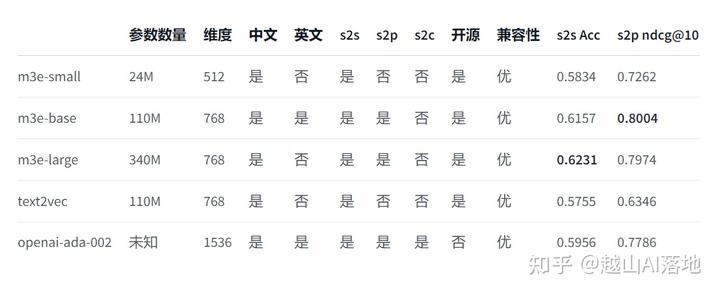
所以,我们需要以下服务:
- embedding模型,这里选m3e-base
- 本地向量数据库,选Milvus
- 本地关系数据库, 选MySQL
embedding 模型, 矢量数据库和关系数据库有许多其它可选的,这里不展开讨论选型了哈。
实现
1. 准备标准的商品分类
商品分类的元数据可以从已有的商品分类中提炼,也可借助于AI生成新的。
由于AI推理的一定局限性和输出有token限制,我们不要一次性让它生成所有的商品分类。采取分步策略,可以获得更好的结果。
先生成一级目录,再一个个生成二级目录,再生成对应的三级目录。这个过程循环操作并记录,理论上就能得到一个全新的,覆盖面较全的商品分类元数据了。


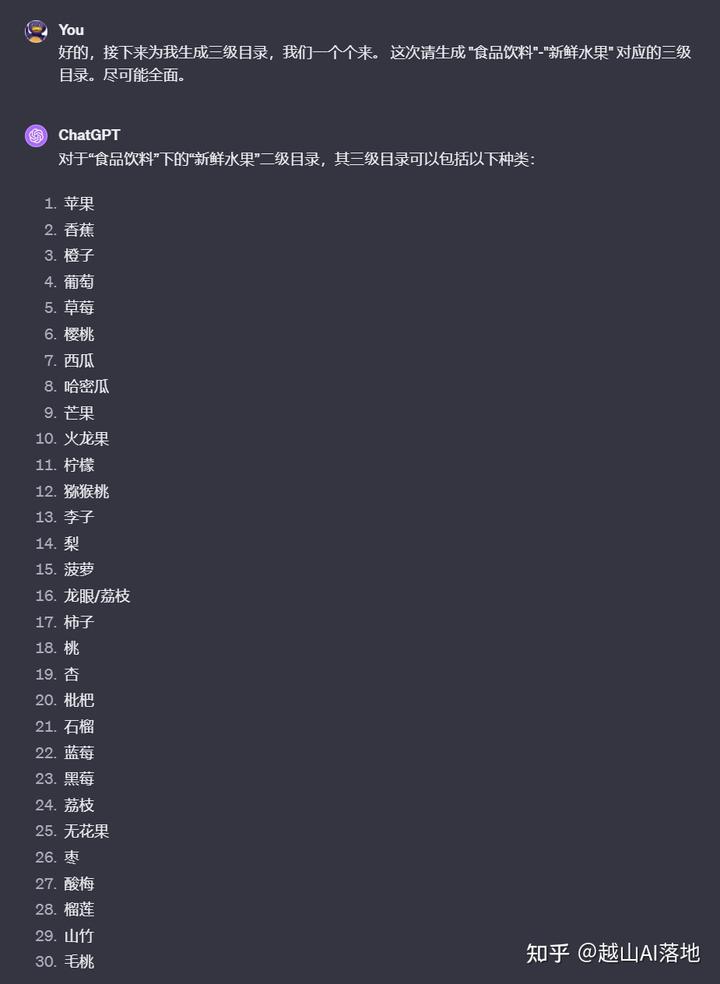
这样操作有个弊端,对话轮次太多了,得有几百次。我们可以用工程化的方法来操作,也就是程序调用API。用Shell或Python都可以,可以让ChatGPT帮忙写这脚本。
# 第一步:生成二级目录
def generate_second_level_categories(first_level_category):
# 生成二级目录的 prompt
prompt = f"一级目录: {first_level_category};"
# 调用 OpenAI API 生成二级目录
response = call_openai_api(prompt)
# 解析二级目录
second_level_categories = response.split(",")
print(f"一级目录: {first_level_category}; 二级目录: {second_level_categories}")
return second_level_categories
# 第二步:生成三级目录
def generate_third_level_categories(first_level_category, second_level_category):
# 生成三级目录的 prompt
prompt = f"一级目录: {first_level_category}; 二级目录: {second_level_category};"
# 调用 OpenAI API 生成三级目录
response = call_openai_api(prompt)
# 解析三级目录
third_level_categories = response.split(",")
print(f"一级目录: {first_level_category}; 二级目录: {second_level_category}; 三级目录: {third_level_categories}")
return third_level_categories
# 保存结果
with open("categories.csv", "w", newline="") as csvfile:
writer = csv.writer(csvfile)
for first_level_category, second_level_category, third_level_category in third_level_categories.items():
writer.writerow([third_level_category, second_level_category, first_level_category])
生成的商品类目并不是我想要的TSV格式,但只要有格式,就好解析。再让AI写个脚本来把这些数据加载到MySQL。至此,商品分类元数据准备完毕。 ...
