摘 关于机器学习的内容的整理
关于机器学习的内容的整理
https://zhuanlan.zhihu.com/p/667126992 一人搞定30万商品分类:AI落地实践中的故事
http://www.uml.org.cn/ai/201812041.asp 一种基于神经网络的智能商品税收分类系统...
|-转 一人搞定30万商品分类:AI落地实践中的故事
传统的关键字匹配不合适,比如葡萄,葡萄干,葡萄糖,葡萄石就是四种品类。 传统的NLP处理也有局限性,且需要重新训练。
使用 M3E 您需要先安装 sentence-transformers
基于真实需求,让AI落地,使用embedding模型做大数据量分类。
为数十万商品分类通常想到的办法是用NLP+特定分类算法(如是SVM)来实现,涉及数据清洗,特征提取,模型训练,调试和集成等工作。看起来是项大工程。 借助现有AI的能力,可以加速实现。本文是基于真实需求场景的探索和回顾。
背景
近期遇到一个做电商的朋友需求,他们的电商平台上有几十万商品,上千种商品品类。而商品品类的划分数据来自多个电商平台,标准描述不统一,分类也有出错的情况,需要对所有商品品类做一个统一的梳理。梳理商品品类的工作由人工完成的话,会很耗时费力。期望借助AI的能力帮忙梳理已有商品品类的划分,而且对于新加入的商品,能自动为其分类。
传统的关键字匹配不合适,比如葡萄,葡萄干,葡萄糖,葡萄石就是四种品类。 传统的NLP处理也有局限性,且需要重新训练。
另外,还有限制条件:
- 商品名主要是中文
- 只能在内网使用
- 没有性能强大(更别提GPU)的服务器
思路
首先想到的是微调一个4bit量化的中文LLM,来实现输入商品名,返回商品二级和一级分类。
已知:
- ChatGLM3 4bit模型在一般的CPU服务器,16GB内存情况下是能跑起来。
- 需要准备500到1000条高质量,覆盖面广的训练数据。
- 需要调教和控制输出格式。
实测下来,4bit LLM能力有限,输出的准确度和格式的一致性不能保证。需要多次“炼丹”,结果还不能保证达到想要的效果。
换个思路,我们要解决传统关键字匹配的问题,本质上是语义的匹配。在以前做知识库问答的过程中用到的embeddings不就是实现了语义的匹配吗?前述的商品分类需求中,并不涉及语言理解和逻辑推理,那其实可以不用LLM。是不是只需要embedding模型就能实现了?
嵌入式模型(Embedding)是一种广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域的机器学习模型,它可以将高维度的数据转化为低维度的嵌入空间(embedding space),并保留原始数据的特征和语义信息,从而提高模型的效率和准确性
说人话,嵌入式模型就是把词或句用多维向量来表示,向量之间的距离表示语义的相近程度。向量之间的距离越短,表示语义越接近。比如“土豆”->[0,1,2],“马铃薯”->[0,1,1],“土狗”->[1,0,0]。 比较[0,1,2]与[0,1,1]的距离要小于[0,1,2]与[1,0,0]的距离,得出结论“土豆”表达的意思与“马铃薯”更接近。
上面的例子中只是一个3维向量,而实际可用的嵌入式模型中,维度要大得多,比如OpenAI提供的Embeddings接口支持1536维度,开源的中文embeddings中m3e-base支持768维度。
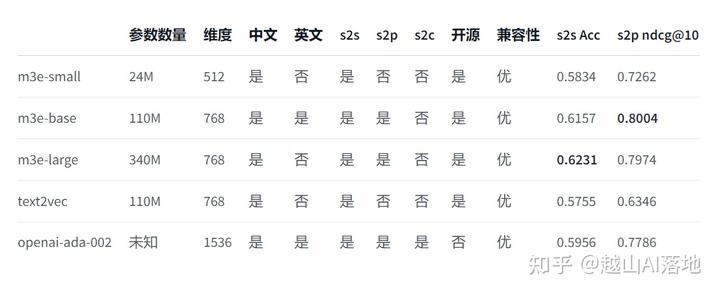
所以,我们需要以下服务:
- embedding模型,这里选m3e-base
- 本地向量数据库,选Milvus
- 本地关系数据库, 选MySQL
embedding 模型, 矢量数据库和关系数据库有许多其它可选的,这里不展开讨论选型了哈。
实现
1. 准备标准的商品分类
商品分类的元数据可以从已有的商品分类中提炼,也可借助于AI生成新的。
由于AI推理的一定局限性和输出有token限制,我们不要一次性让它生成所有的商品分类。采取分步策略,可以获得更好的结果。
先生成一级目录,再一个个生成二级目录,再生成对应的三级目录。这个过程循环操作并记录,理论上就能得到一个全新的,覆盖面较全的商品分类元数据了。


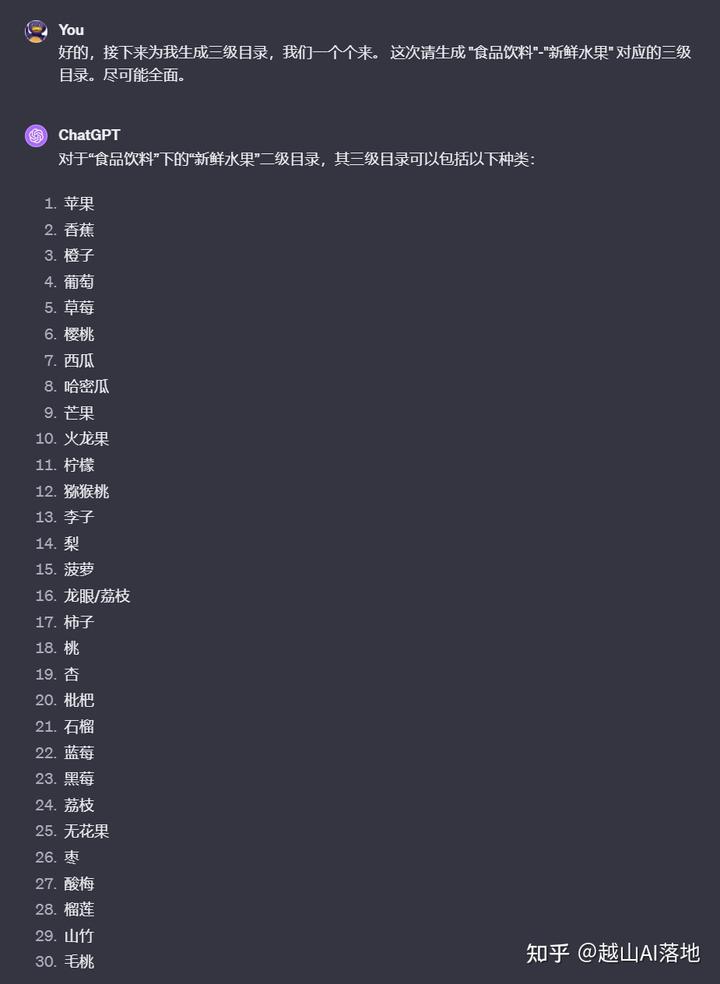
这样操作有个弊端,对话轮次太多了,得有几百次。我们可以用工程化的方法来操作,也就是程序调用API。用Shell或Python都可以,可以让ChatGPT帮忙写这脚本。
# 第一步:生成二级目录
def generate_second_level_categories(first_level_category):
# 生成二级目录的 prompt
prompt = f"一级目录: {first_level_category};"
# 调用 OpenAI API 生成二级目录
response = call_openai_api(prompt)
# 解析二级目录
second_level_categories = response.split(",")
print(f"一级目录: {first_level_category}; 二级目录: {second_level_categories}")
return second_level_categories
# 第二步:生成三级目录
def generate_third_level_categories(first_level_category, second_level_category):
# 生成三级目录的 prompt
prompt = f"一级目录: {first_level_category}; 二级目录: {second_level_category};"
# 调用 OpenAI API 生成三级目录
response = call_openai_api(prompt)
# 解析三级目录
third_level_categories = response.split(",")
print(f"一级目录: {first_level_category}; 二级目录: {second_level_category}; 三级目录: {third_level_categories}")
return third_level_categories
# 保存结果
with open("categories.csv", "w", newline="") as csvfile:
writer = csv.writer(csvfile)
for first_level_category, second_level_category, third_level_category in third_level_categories.items():
writer.writerow([third_level_category, second_level_category, first_level_category])
生成的商品类目并不是我想要的TSV格式,但只要有格式,就好解析。再让AI写个脚本来把这些数据加载到MySQL。至此,商品分类元数据准备完毕。 ...
|-转 win10开HYPER-V后物理机上不了外网
如果是广东地区首选DNS202.96.128.86 ,备选DNS 8.8.8.8 ,效果是最好的
win10开HYPER-V后物理机上不了外网,解决方法有2,如下
1、你的物理机有两个网卡,在给hyper-v新建虚拟交换机时选择没有使用的物理网卡,然后物理机使用另一个网卡。这样虚拟机物理机上网不受影响,流量正常。如下图

2、物理机只有一个网卡时,给虚拟机开外网时,物理机会暂时丢失外网。此时,给物理机配个DNS即可上外网。所以物理机上不了外网时,打开网卡设置配置一个DNS,比如8.8.8.8...
|-转 M3E: 文本嵌入模型入门
https://zhuanlan.zhihu.com/p/677061198

M3E: 文本嵌入模型入门

前言
在上一篇文章中,我们介绍了Milvus向量数据库,今天我们要介绍的是嵌入模型(Embedding Model),今天介绍的是M3E文本嵌入模型,同样这也是为AI大模型项目实战v0.3做铺垫。在实战v0.3中会用到M3E嵌入模型
我们会从以下几个方面介绍:...
|-转 【A情感文本分类实战】2024 Pytorch+Bert、Roberta+TextCNN、BiLstm、Lstm等实现IMDB情感文本分类完整项目(项目已开源)
原文较长这里只转载前一部分内容 20240325
https://blog.csdn.net/ccaoshangfei/article/details...
https://github.com/BeiCunNan/sentiment_analysis_Im...
?顶会的代码干净利索,借鉴其完成了以下工程
?本工程采用Pytorch框架,使用上游语言模型+下游网络模型的结构实现IMDB情感分析
?预训练大语言模型可选择Bert、Roberta
?下游网络模型可选择BiLSTM、LSTM、TextCNN、GRU、Attention以及其组合
?语言模型和网络模型扩展性较好,可以此为BaseLine再使用你的数据集,模型
?最终的准确率均在90%以上
?项目已开源,clone下来再配个简单环境就能跑
???有小伙伴询问如何融合使用Attention、LSTM+TextCNN和Lstm+TextCNN+Self-Attention的网络模型,现源码已经重新上传(2023-03),大家可以揣摩一下是如何结合的,如此,对照类似的做法,推广到其他模型上
如果这篇文章对您有帮助,期待大佬们Github上给个⭐️⭐️⭐️
一、Introduction
1.1 网络架构图
该网络主要使用上游预训练模型+下游情感分类模型组成
1.2 快速使用
该项目已开源在Github上,地址为 sentiment_analysis_Imdb
主要环境要求如下(环境不要太老基本没啥问题的)
下载该项目后,配置相对应的环境,在config.py文件中选择所需的语言模型和神经网络模型如下图所示,运行main.py文件即可
1.3 工程结构
logs 每次运行程序后的日志文件集合
config.py 全局配置文件
data.py 数据读取、数据清洗、数据格式转换、制作DataSet和DataLoader
main.py 主函数,负责全流程项目运行,包括语言模型的转换,模型的训练和测试
model.py 神经网络模型的设计和读取
二、Config
看了很多论文源代码中都使用parser容器进行全局变量的配置,因此作者也照葫芦画瓢编写了config.py文件(适配的话一般只改Base部分)
import argparse
import logging
import os
import random
import sys
import time
from datetime import datetime
import torch
def get_config():
parser = argparse.ArgumentParser()
'''Base'''
parser.add_argument('--num_classes', type=int, default=2)
parser.add_argument('--model_name', type=str, default='bert',
choices=['bert', 'roberta'])
parser.add_argument('--method_name', type=str, default='fnn',
choices=['gru', 'rnn', 'bilstm', 'lstm', 'fnn', 'textcnn', 'attention', 'lstm+textcnn',
'lstm_textcnn_attention'])
'''Optimization'''
parser.add_argument('--train_batch_size', type=int, default=4)
parser.add_argument('--test_batch_size', type=int, default=16)
parser.add_argument('--num_epoch', type=int, default=50)
parser.add_argument('--lr', type=float, default=1e-5)
parser.add_argument('--weight_decay', type=float, default=0.01)
'''Environment'''
parser.add_argument('--device', type=str, default='cpu')
parser.add_argument('--backend', default=False, action='store_true')
parser.add_argument('--workers', type=int, default=0)
parser.add_argument('--timestamp', type=int, default='{:.0f}{:03}'.format(time.time(), random.randint(0, 999)))
args = parser.parse_args()
args.device = torch.device(args.device)
'''logger'''
args.log_name = '{}_{}_{}.log'.format(args.model_name, args.method_name,
datetime.now().strftime('%Y-%m-%d_%H-%M-%S')[2:])
if not os.path.exists('logs'):
os.mkdir('logs')
logger = logging.getLogger()
logger.setLevel(logging.INFO)...
|-转 pytorch-textclassification是一个专注于中文文本分类(多类分类、多标签分类)的轻量级自然语言处理工具包,基于pytorch和transformers,包含各种实验
代码跑起来了,生成了模型文件后,没有说明如何使用模型进行分类预测。
代码中 path_root = os.path.abspath(os.path.join(os.path.dirname(__file__), "../..")),这里要改下
我这里改成了path_root = r'D:\python\python3.10.0\Lib\site-packages',因为我这边安装的包的位置是这里D:\python\python3.10.0\Lib\site-packages\pytorch_nlu\pytorch_textclassification。另外bert-base-chinese模型我是下载到本地的,位置在C:\Users\Administrator\Downloads\models\bert-base-chinese所以这里也修改了下,之后就能跑了
model_config["pretrained_model_name_or_path"] = r'C:\Users\Administrator\Downloads\models\bert-base-chinese'
先运行安装 # 清华镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Pytorch-NLU
本地bert-base-chinese模型的目录结构

代码跑起来了后的运行截图
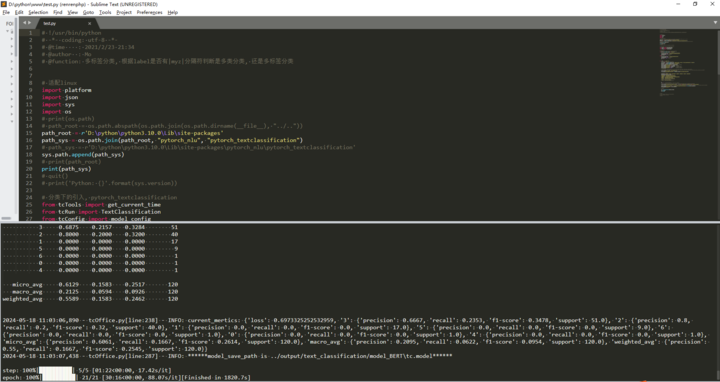
pytorch-textclassification
pytorch-textclassification是一个以pytorch和transformers为基础,专注于文本分类的轻量级自然语言处理工具包。支持中文长文本、短文本的多类分类和多标签分类。
目录
数据
数据来源
所有数据集均来源于网络,只做整理供大家提取方便,如果有侵权等问题,请及时联系删除。
- baidu_event_extract_2020, 项目以 2020语言与智能技术竞赛:事件抽取任务中的数据作为多分类标签的样例数据,借助多标签分类模型来解决, 共13456个样本, 65个类别;
- AAPD-dataset, 数据集出现在论文-SGM: Sequence Generation Model for Multi-label Classification, 英文多标签分类语料, 共55840样本, 54个类别;
- toutiao-news, 今日头条新闻标题, 多标签分类语料, 约300w-语料, 1000+类别;
- * unknow-data, 来源未知, 多标签分类语料, 约22339语料, 7个类别;
- SMP2018中文人机对话技术评测(ECDT), SMP2018 中文人机对话技术评测(SMP2018-ECDT)比赛语料, 短文本意图识别语料, 多类分类, 共3069样本, 31个类别;
- 文本分类语料库(复旦)语料, 复旦大学计算机信息与技术系国际数据库中心自然语言处理小组提供的新闻语料, 多类分类语料, 共9804篇文档,分为20个类别。
- MiningZhiDaoQACorpus, 中国科学院软件研究所刘焕勇整理的问答语料, 百度知道问答语料, 可以把领域当作类别, 多类分类语料, 100w+样本, 共17个类别;
- THUCNEWS, 清华大学自然语言处理实验室整理的语料, 新浪新闻RSS订阅频道2005-2011年间的历史数据筛选, 多类分类语料, 74w新闻文档, 14个类别;
- IF***TEK, 科大讯飞开源的长文本分类语料, APP应用描述的标注数据,包含和日常生活相关的各类应用主题, 链接为CLUE, 共17333样例, 119个类别;
- TNEWS, 今日头条提供的中文新闻标题分类语料, 数据集来自今日头条的新闻版块, 链接为CLUE, 共73360样例, 15个类别;
项目地址
- pytorch-textclassification:Pytorch-NLU/pytorch_nlu/pytorch_textclassification at main · yongzhuo/Pytorch-NLU
数据格式
1. 文本分类 (txt格式, 每行为一个json):
1.1 多类分类格式:
{"text": "人站在地球上为什么没有头朝下的感觉", "label": "教育"}
{"text": "我的小baby", "label": "娱乐"}
{"text": "请问这起交通事故是谁的责任居多小车和摩托车发生事故在无红绿灯", "label": "娱乐"}
1.2 多标签分类格式:
{"label": "3|myz|5", "text": "课堂搞东西,没认真听"}
{"label": "3|myz|2", "text": "测验90-94.A-"}
{"label": "3|myz|2", "text": "长江作业未交"}
使用方式
更多样例sample详情见test/tc目录 ...
|-转 一种基于神经网络的智能商品税收分类系统
http://www.uml.org.cn/ai/201812041.asp
|
1. 项目背景
1.1 业务问题描述
目前企业财务人员开取商品增值税发票时,票面上的商品需要与税务总局核定的税分类编码进行关联,按分类编码上注明的税率和征收率开具发票,使得税务机关可以统计、筛选、比对数据等,最终加强征收管理。为了满足这一要求,最关键的地方就在于确定商品的税分类编码。传统的方法是人工筛选商品关键字,然后在税务总局提供的税分类编码列表中查找,无法直接查找到的,根据政策先进行行业、大类的划分,再进行小类细划分,对于无法清楚界定、归类的,按照商品的材料或用途选择最近似的编码,最后根据编码确定商品名称和税率。
例如根据商品名“夏装雪纺条纹短袖 t 恤女春半袖衣服夏天中长款大码胖 mm 显瘦上衣夏”,预测相应的税分类编码(要求类目比较精细)、税分类简称、税分类描述以及对应的税率。商品量为千万甚至亿量级,通常商品名字数不会太多,税分类编码有 4200 多种,常见的商品税分类编码应该少于该数值。
1.2 解决方案
目前存在少部分自动税分类编码系统,采取的方案主要是根据大量的商品关键词建立关键词与税分类编码的一一对应关系,并存储在数据库中,开票人员首先仍然需要人工筛选商品关键词提供给税分类系统,系统在数据库中根据关键词进行查找,输出相应的税分类编码和税率等,如果没有匹配的结果将没有输出。原有系统存在的缺点主要是需要事先人工筛选商品关键词,而目前实际的商品名称五花八门,为了提高商品的检索量添加了大量的修饰词语,在人工筛选关键词这一步仍然存在不少工作量,不能做到完全的自动化处理。
本文的思路主要是将该问题当作一个短文本多分类问题,根据商品名称分词后生成的词向量,基于神经网络学习一个文本分类模型,在此基础上构建一个智能商品税分类系统。
2. 完整的技术方案
2.1 数据接入
大数据平台数据库内存有大量已开票商品数据,从已开票商品数据中提取商品名称、税分类编码和税率三个字段,同时要筛选掉税分类编码字段为空或者编码错误的数据,将最终获取的数据按行存储到文本文件中,为训练商品模型提供数据服务。
2.2 文本预处理
文本预处理是在文本中提取关键词表示文本的过程,主要包括文本分词和去停用词两个阶段。例如商品名“夏装雪纺条纹短袖 t 恤女春半袖衣服夏天中长款大码胖 mm 显瘦上衣夏”经文本分词和去停用词之后商品示例标题变成了下面“ / ”分割的一个个关键词的形式:
夏装 / 雪纺 / 条纹 / 短袖 / t 恤 / 女 / 春 / 半袖 / 衣服 / 夏天 / 中长款 / 大码 / 胖 mm / 显瘦 / 上衣 / 夏。
由于业内中文文本分词方法已经非常成熟,我们采用目前应用较多的中文分词库 jieba 进行分词。
2.3 词嵌入生成
word embedding(词嵌入)生成模型如图 1 所示。
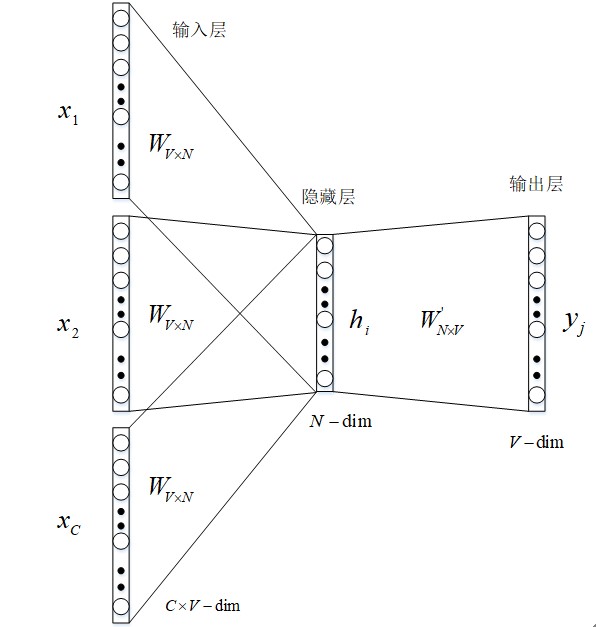
图 1 词嵌入生成模型架构
2.3.1 前向传播

2.3.2 反向传播和随机梯度下降学习权重
在学习权重矩阵 W 与 W’过程中,我们可以给这些权重赋一个随机值来初始化。然后按序训练样本,逐个观察输出与真实值之间的误差,并计算这些误差的梯度。并在梯度反方向纠正权重矩阵,这种方法被称为随机梯度下降,但这个衍生出来的方法叫做反向传播误差算法。具体步骤如下
首先定义 loss function(损失函数),这个损失函数就是给定输入上下文的输出词语的条件概率,一般都是取对数,如下所示:
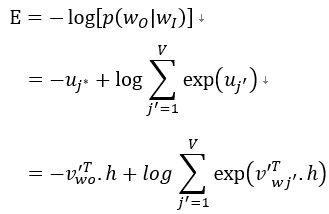
其中 j* 表示目标词在词表 V 中的索引。
接下来对损失函数求导,得到输出权重矩阵 W’的更新规则:
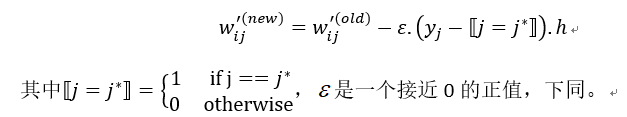
类似地可以得到权重矩阵 W 的更新规则:
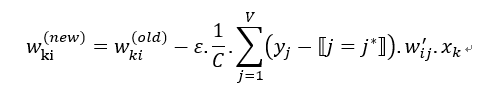
2.3.3 获取词嵌入
在第 2.3.2 节中经过足够次数的迭代,损失函数足够小时,我们可以得到权重矩阵 W,其中矩阵 W 的第 k 行就是词表 V 中编号为 k 的词所对应的词嵌入。...
|-转 无依赖安装sentence-transformers
可以使用pipdeptree 查看依赖
实测ok的
pip install --no-cache-dir torch==2.1.1+cpu -f https://download.pytorch.org/whl/torch_stable.html pip install transformers tqdm numpy scikit-learn scipy nltk sentencepiece huggingface-hub Pillow pip install --no-deps sentence-transformers
20240319 ...
|-转 Windos 环境下 Milvus 向量数据库的 Docker Compose 部署
本文选择 Milvus 版本2.3.8。
先决条件
下载 Milvus 配置文件
- GPU 启动下载文件milvus-standalone-docker-compose-gpu.yml
- CPU 启动下载文件milvus-standalone-docker-compose.yml
启动 Milvus 服务
下载之后可以将文件重命名为docker-compose.yml然后在对应文件夹下用Power Shell终端执行命令:
1 | docker compose up -d |
如果没有重命名,则执行命令:
1 | docker compose -f filename.yml up -d |
如果成功则返回:
12345 | [+] Running 3/4 - Network milvus Created 1.6s ✔ Container milvus-etcd Started 0.7s ✔ Container milvus-minio Started 1.0s ✔ Container milvus-standalone Started 1.1s |
验证安装
现在可以检查运行是否成功。
1 | docker compose ps |
看到返回如下(我这里是 GPU 启动的):...
|-转 NLP入门——从0到实现文本分类
https://zhuanlan.zhihu.com/p/77726136
读了后有些启发,原作者为了比赛看了不少资料,特别是还找到了谷歌的免费GPU资源,来解决训练模型算力不够的问题。他自己写的利用GPU的文章已经不见了。我自己网上找了个:https://blog.csdn.net/edmond999/article/details/122577420 Google Colab和Kaggle搭配使用
暑假酷暑难耐,需要寻找一种方式让自己时刻感到凉爽,正巧,科大讯飞推出大数据应用分类标注挑战赛,我就报名参加了。本人以前没接触过NLP,所以做比赛时前期分数很难上去,心拔凉拔凉的。
先大致说下比赛是干什么的吧,本次比赛要求参赛者根据app的应用描述信息给出app的分类,说白了就是文本分类问题。官方给的训练集样例如下。

OK,交代了比赛的背景,下面我先大致说下为什么我要写下这篇文章,通过这篇文章你能获得什么,然后就是本文的重头戏——从0到实现文本分类(真的不需要你有NLP基础哦)。
1. 我为什么要写下这篇文章
这个比赛是我做的第一个完整的比赛,从7月3号到现在一直都在做,现在初赛结束了,目前排名第4。
用心付出的事物总是值得回味,所以我写下了这篇文章,记录比赛经历和一些心得体会,希望对后来者有所帮助,也激励自己前进。
我将大致分享如下东西:
- 比赛过程中代码和数据如何整理。
- 缺少计算资源,如何使用免费的GPU计算资源。
- 文本分类算法。从传统机器学习到深度学习,到最近的NLP利器bert模型。
你从本文能获得什么:
- 大量的有用资料。我在比赛的过程中,不断的进行学习,期间阅读了许多优秀的文章(有算法原理、实战教程),我将会在文中分享给你。
- NLP知识和文本分类算法。
- 比赛过程中的注意事项。我踩过的炕你就不要再踩了。
我的整个分享将结合比赛以实现文本分类为主线,从机器学习到深度学习,再到bert。其中关于“比赛过程中代码和数据如何整理”、“缺少计算资源,如何使用免费的GPU计算资源”,“比赛过程中的注意事项”等话题将穿插其中。
好了,下面我们就正式开始吧。
2. 传统机器学习实现文本分类
首先我们要明白这个问题属于机器学习的哪一类问题,很显然,这属于有监督学习中的分类问题。传统机器学习分类器有SVM、决策树、逻辑回归等,都可以尝试下。
假设我们现在选择逻辑回归作为分类器模型,现在就应该把我们的训练数据喂给分类器,wait,原始训练数据都是中文,不可能直接喂给LR,因为我们的LR等分类器只认识数字。
好了,第一个问题来了,怎么把一行中文文本数字化?
如何将文本数字化是NLP领域的基础工作,也是多数任务的第一步。据我了解,将文本数字化的技术大致分为向量空间模型和文本的分布式表示。下面我将详细介绍这两种技术。
2.1 文本数字化——向量空间模型
向量空间模型要做的事情就是将一行文本转换为一个向量。其中典型的技术有词袋模型、TF-IDF(词频逆文档频率)模型。
为了简单易懂,我们拿“我是天才,我爱读书”、“你是帅哥,你爱美女”这两句话来说明模型如何向量化文本。
一段话是由多个词组成的,要想把一段话转换为一个向量,我们首先需要给词进行编码。给单词编码一般采用one-hot编码(独热编码),其思想就是给每个不同的单词一个唯一对应的数字。
比如,“我是天才,我爱读书”可以看成由“我”、“是”、“天才”、“我”、“爱”、“读书”这6个词组成的序列。
我”编码为1、“是”编码为2、“天才”编码为3、“爱”编码为4、“读书”编码为5。
同样的,“你是帅哥,你爱美女”可以看成由“你”、“是”、“帅哥”、“你”、“爱”、“美女”这6个词组成的序列。
“你”编码为6,“帅哥”编码为7,“美女”编码为8。
现在假设不同单词的个数为n,我们可以用1到n的自然数来编码这n个不同的单词,为了向量化文本,我们用一个n维的向量表示一段话,向量中的n个位置表示该编码的单词在文本中的权重。
“我是天才,我爱读书”、“你是帅哥,你爱美女”这两段话总共有8个不同的单词,我们看可以用8维的向量表示每一句话。
“我是天才,我爱读书”可以向量化为 [2, 1,1,1,1,0,0,0]。在“我是天才,我爱读书”这段话中,“我”出现了两次,并且“我”的编码为1,所有向量的第一个位置的值为2。...
