|-转 MySQL 8.0 索引特性1-函数索引
函数索引顾名思义就是加给字段加了函数的索引,这里的函数也可以是表达式。所以也叫表达式索引。MySQL 5.7 推出了虚拟列的功能,MySQL8.0的函数索引内部其实也是依据虚拟列来实现的。
我们考虑以下几种场景:
1.对比日期部分的过滤条件
SELECT ... FROM tb1 WHERE date(time_field1) = current_date;
2.两字段做计算
SELECT ... FROM tb1 WHERE field2 + field3 = 5;
3.求某个字段中间某子串
SELECT ... FROM tb1 WHERE substr(field4, 5, 9) = 'actionsky';
4.求某个字段末尾某子串
SELECT ... FROM tb1 WHERE RIGHT(field4, 9) = 'actionsky';
5.求JSON格式的VALUE
SELECT ... FROM tb1 WHERE CAST(field4 ->> '$.name' AS CHAR(30)) = 'actionsky';
以上五个场景如果不用函数索引,改写起来难易不同。不过都要做相关修改,不是过滤条件修正就是表结构变更添加冗余字段加额外索引。
比如第1个场景改写为,
SELECT ...
FROM tb1
WHERE time_field1 >= concat(current_date, ' 00:00:00')
AND time_field1 <= concat(current_date, '23:59:59');
再比如第4个场景的改写,由于是求最末尾的子串,只能添加一个新的冗余字段,并且做相关的计划任务来一定频率的异步更新或者添加触发器来实时更新此字段值
SELECT ... FROM tb1 WHERE field4_suffix = 'actionsky';
那我们看到,改写也可以实现,不过这样的SQL就没有标准化而言,后期不能平滑的迁移了。
MySQL 8.0 推出来了函数索引让这些变得相对容易许多。不过函数索引也有自己的缺陷,就是写法很固定,必须要严格按照定义的函数来写,不然优化器不知所措。
我们来把上面那些场景实例化。示例表结构,
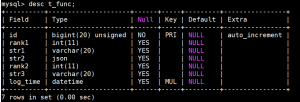
总记录数
mysql> SELECT COUNT(*) FROM t_func; +----------+ | count(*) | +----------+ | 16384 | +----------+ 1 row in set (0.01 sec)
我们把上面几个场景的索引全加上
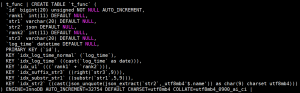
mysql > ALTER TABLE t_func ADD INDEX idx_log_time ( ( date( log_time ) ) ), ADD INDEX idx_u1 ( ( rank1 + rank2 ) ), ADD INDEX idx_suffix_str3 ( ( RIGHT ( str3, 9 ) ) ), ADD INDEX idx_substr_str1 ( ( substr( str1, 5, 9 ) ) ), ADD INDEX idx_str2 ( ( CAST( str2 ->> '$.name' AS CHAR ( 9 ) ) ) ); QUERY OK, 0 rows affected ( 1.13 sec ) Records : 0 Duplicates : 0 WARNINGS : 0
我们再看下表结构, 发现好几个已经被转换为系统自己的写法了
MySQL 8.0 还有一个特性,就是可以把系统隐藏的列显示出来。我们用show extened 列出函数索引创建的虚拟列,
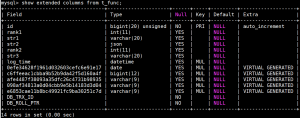
上面5个随机字符串列名为函数索引隐式创建的虚拟COLUMNS。
我们先来看看场景2,两个整形字段的相加,
mysql> SELECT COUNT(*) FROM t_func WHERE rank1 + rank2 = 121; +----------+ | count(*) | +----------+ | 878 | +----------+ 1 row in set (0.00 sec)
看下执行计划,用到了idx_u1函数索引,
mysql> explain SELECT COUNT(*)
FROM t_func
WHERE rank1 + rank2 = 121\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_func
partitions: NULL
type: ref
possible_keys: idx_u1
key: idx_u1
key_len: 9
ref: const
rows: 878
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
那如果我们稍微改下这个SQL的执行计划,发现此时不能用到函数索引,变为全表扫描了,所以要严格按照函数索引的定义来写SQL ...
|-转 MySQL字符串函数substring:字符串截取
substr() 等价于 substring() 函数,我这里主要是看下这个函数,并应用。
http://www.cnblogs.com/zdz8207/p/3765073.html
MySQL 字符串截取函数:left(), right(), substring(), substring_index()。还有 mid(), substr()。其中,mid(), substr() 等价于 substring() 函数,substring() 的功能非常强大和灵活。
1. 字符串截取:left(str, length)
mysql> select left('example.com', 3);
+-------------------------+
| left('example.com', 3) |
+-------------------------+
| exa |
+-------------------------+
2. 字符串截取:right(str, length)
mysql> select right('example.com', 3);
+--------------------------+
| right('example.com', 3) |
+--------------------------+
| com |
+--------------------------+
实例:
#查询某个字段后两位字符
select right(last3, 2) as last2 from historydata limit 10;
#从应该字段取后两位字符更新到另外一个字段
update `historydata` set `last2`=right(last3, 2);
3. 字符串截取:substring(str, pos); substring(str, pos, len)
3.1 从字符串的第 4 个字符位置开始取,直到结束。
mysql> select substring('example.com', 4);
+------------------------------+
| substring('example.com', 4) |
+------------------------------+
| mple.com |
+------------------------------+
3.2 从字符串的第 4 个字符位置开始取,只取 2 个字符。
mysql> select substring('example.com', 4, 2);
+---------------------------------+
| substring('example.com', 4, 2) |
+---------------------------------+
| mp |
+---------------------------------+
3.3 从字符串的第 4 个字符位置(倒数)开始取,直到结束。
mysql> select substring('example.com', -4);
+-------------------------------+
| substring('example.com', -4) |
+-------------------------------+
| .com |
+-------------------------------+
3.4 从字符串的第 4 个字符位置(倒数)开始取,只取 2 个字符。...
|-转 Mysql的临时变量取值3例
在实际使用时,我在mysql8下测试的是不用set声明,直接用
select @mysum:=COUNT(*) from mendpinfo where ipaddr = rvIpaddr;这个语句
因为有一个临时的结果,就是查找关键词的位置要存下,所以用到了临时变量,注意用的时候前面要加@
20200422
例子1:
DECLARE iSystemTypeId INT;
set iSystemTypeId = NULL;
select SystemTypeId into iSystemTypeId from B_SystemType where os = Aos;
常规用法
例子2:
DECLARE lockTime datetime;
set lockTime=(select lockTime from ccmUsers where name=myuser);
trigger中用的多
例子3:
set @mysum=0;
select @mysum:=COUNT(*) from mendpinfo where ipaddr = rvIpaddr;...
|-转 mysql查找字符串出现位置
我这里就是用下LOCATE(substr,str)查找字符串在字段中出现的位置。
MySQL中的LOCATE和POSITION函数使用方法
FIND_IN_SET(str,strlist)
假如字符串str 在由N 子链组成的字符串列表strlist 中,则返回值的范围在 1 到 N 之间。一个字符串列表就是一个由一些被‘,’符号分开的自链组成的字符串。如果第一个参数是一个常数字符串,而第二个是type SET列,则 FIND_IN_SET() 函数被优化,使用比特计算。如果str不在strlist 或strlist 为空字符串,则返回值为 0 。如任意一个参数为NULL,则返回值为 NULL。这个函数在第一个参数包含一个逗号(‘,’)时将无法正常运行。返回值为str在strlist中的位置,从1开始计数。
LOCATE(substr,str)
POSITION(substr IN str)
函数返回子串substr在字符串str中第一次出现的位置。如果子串substr在str中不存在,返回值为0。
str IN (strlist)
查找str在strlist中出现的位置。如果找不到,返回false。strlist为一个用逗号连接的字符串。
函数的区别为:第一个函数FIND_IN_SET中的strlist为一个用逗号连接起来的字符串,一般为数据库中的某个字段。当需要查找某个字段中是否有某个值的时候,使用这个函数。
第三个函数IN()刚好和函数FIND_IN_SET()相反,strlist为一个常量字符串序列,str为数据库中某个字段。此时查找数据库中的字段是否在某个序列中。...
|-转 mysql 更改AUTO_INCREMENT 失败的解决办法
SET FOREIGN_KEY_CHECKS = 0;
ALTER TABLE仓库`.addresses`
更改列`aID``aID` INT(10)UNSIGNED NOT NULL;
SET FOREIGN_KEY_CHECKS = 1;
首先,从ID列中删除 AUTO_INCREMENT 。如果有外键还有更改外键,我已经检查了外键,所以我必须运行:
SET FOREIGN_KEY_CHECKS = 0; ALTER TABLE仓库`.addresses` 更改列`aID``aID` INT(10)UNSIGNED NOT NULL; SET FOREIGN_KEY_CHECKS = 1;
最后,重新添加 AUTO_INCREMENT : ,或者更新AUTO_INCREMENT后再添加 ...
|-转 MYSQL 数据库导入导出命令
mysqldump -u root -p wokan > /data/wokan20211224.sql
在操作系统命令行 运行 mysqldump -u root -p test >d:\test.sql
在不同操作系统或MySQL版本情况下,直接拷贝文件的方法可能会有不兼容的情况发生。所以一般推荐用SQL脚本形式导入。下面分别介绍两种方法。
MySQL命令行导出数据库
1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录
如我输入的命令行:cd C:\Program Files\MySQL\MySQL Server 4.1\bin
(或者直接将windows的环境变量path中添加该目录)
2,导出数据库:mysqldump -u 用户名 -p 数据库名 > 导出的文件名
如我输入的命令行:mysqldump -u root -p news > news.sql(输入后会让你输入进入MySQL的密码)
(如果导出单张表的话在数据库名后面输入表名即可)
3、会看到文件news.sql自动生成到bin文件下
命令行导入数据库
1,将要导入的.sql文件移至bin文件下,这样的路径比较方便
2,同上面导出的第1步
3,进入MySQL:mysql -u 用户名 -p
如我输入的命令行:mysql -u root -p(输入同样后会让你输入MySQL的密码)
4,在MySQL-Front中新建你要建的数据库,这时是空数据库,如新建一个名为news的目标数据库
5,输入:mysql>use 目标数据库名
如我输入的命令行:mysql>use news;
6,导入文件:mysql>source 导入的文件名;
如我输入的命令行:mysql>source news.sql;
MySQL备份和还原,都是利用mysqldump、mysql和source命令来完成的。
备份数据库:
进入cmd
导出所有数据库:输入:mysqldump -u [数据库用户名] -p -A>[备份文件的保存路径]
导出数据和数据结构:输入:mysqldump -u [数据库用户名] -p [要备份的数据库名称]>[备份文件的保存路径]
例子:mysqldump -u root -p test>d:\test.sql
注意:此备份只备份数据和数据结构,没有备份存储过程和触发器
只导出数据不导出数据结构:输入:mysqldump -u [数据库用户名] -p -t [要备份的数据库名称]>[备份文件的保存路径]
导出数据库中的Events
输入:mysqldump -u [数据库用户名] -p -E [数据库用户名]>[备份文件的保存路径]
导出数据库中的存储过程和函数
mysqldump -u [数据库用户名] -p -R [数据库用户名]>[备份文件的保存路径]
导入数据库
mysql -u root -p<[备份文件的保存路径] 疑问
恢复备份文件:
进入MYSQL Command Line Client
先创建数据库:create database test 注:test是创建数据库的名称
再切换到当前数据库:use test
再输入:\. d:/test.sql 或 souce d:/test.sql
1. 概述
MySQL数据库的导入,有两种方法:
1) 先导出数据库SQL脚本,再导入;
2) 直接拷贝数据库目录和文件。
在不同操作系统或MySQL版本情况下,直接拷贝文件的方法可能会有不兼容的情况发生。
所以一般推荐用SQL脚本形式导入。下面分别介绍两种方法。
2. 方法一 SQL脚本形式
操作步骤如下:
2.1. 导出SQL脚本
在原数据库服务器上,可以用phpMyAdmin工具,或者mysqldump(mysqldump命令位于mysql/bin/目录中)命令行,导出SQL脚本。
2.1.1 用phpMyAdmin工具
导出选项中,选择导出“结构”和“数据”,不要添加“Drop DATABASE”和“Drop TABLE”选项。
选中“另存为文件”选项,如果数据比较多,可以选中“gzipped”选项。
将导出的SQL文件保存下来。
2.1.2 用mysqldump命令行
命令格式
mysqldump -u用户名 -p 数据库名 > 数据库名.sql
范例:
mysqldump -uroot -p abc > abc.sql
(导出数据库abc到abc.sql文件)
提示输入密码时,输入该数据库用户名的密码。
2.2. 创建空的数据库
通过主控界面/控制面板,创建一个数据库。假设数据库名为abc,数据库全权用户为abc_f。
2.3. 将SQL脚本导入执行
同样是两种方法,一种用phpMyAdmin(mysql数据库管理)工具,或者mysql命令行。
2.3.1 用phpMyAdmin工具
从控制面板,选择创建的空数据库,点“管理”,进入管理工具页面。
在"SQL"菜单中,浏览选择刚才导出的SQL文件,点击“执行”以上载并执行。
注意:phpMyAdmin对上载的文件大小有限制,php本身对上载文件大小也有限制,如果原始sql文件
比较大,可以先用gzip对它进行压缩,对于sql文件这样的文本文件,可获得1:5或更高的压缩率。
gzip使用方法:
# gzip xxxxx.sql
得到
xxxxx.sql.gz文件。
2.3.2 用mysql命令行
命令格式
mysql -u用户名 -p 数据库名 < 数据库名.sql
范例:
mysql -uabc_f -p abc < abc.sql
(导入数据库abc从abc.sql文件)
提示输入密码时,输入该数据库用户名的密码。
3 方法二 直接拷贝
如果数据库比较大,可以考虑用直接拷贝的方法,但不同版本和操作系统之间可能不兼容,要慎用。
3.1 准备原始文件
用tar打包为一个文件
3.2 创建空数据库
3.3 解压
在临时目录中解压,如:
cd /tmp
tar zxf mydb.tar.gz
3.4 拷贝
将解压后的数据库文件拷贝到相关目录
cd mydb/
cp * /var/lib/mysql/mydb/
对于FreeBSD:
cp * /var/db/mysql/mydb/
3.5 权限设置
将拷贝过去的文件的属主改为mysql:mysql,权限改为660
chown mysql:mysql /var/lib/mysql/mydb/*
...
|-转 mysql如何判断不包含某个字符串
mysql中可以使用locate()函数判断不包含某个字符串。
locate()函数判断字符串(string)中是否包含另一个字符串(subStr):
locate(subStr,string) :函数返回subStr在string中出现的位置
使用locate(字符,字段名)函数,如果包含,返回>0的数,否则返回0 。
// 如果字符串 string 包含 subStr locate(subStr,string) > 0 // 如果字符串 string 不包含 subStr locate(subStr,string) = 0
测试了发觉 locate(subStr,string) = 0 执行效率有点慢 20220414 ...
|-转 ORM 实例教程
作者:阮一峰
日期:2019年2月18日一、概述
面向对象编程和关系型数据库,都是目前最流行的技术,但是它们的模型是不一样的。
面向对象编程把所有实体看成对象(object),关系型数据库则是采用实体之间的关系(relation)连接数据。很早就有人提出,关系也可以用对象表达,这样的话,就能使用面向对象编程,来操作关系型数据库。
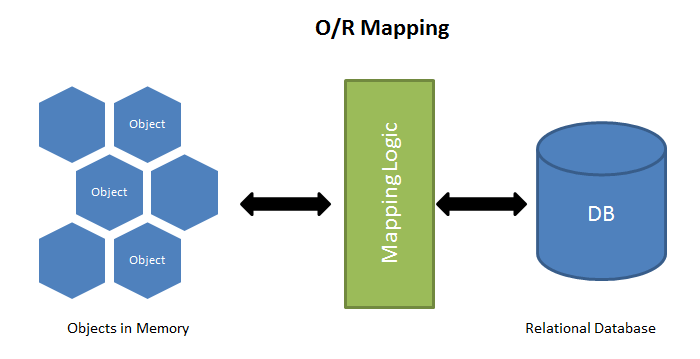
简单说,ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术,是"对象-关系映射"(Object/Relational Mapping) 的缩写。
ORM 把数据库映射成对象。
- 数据库的表(table) --> 类(class)
- 记录(record,行数据)--> 对象(object)
- 字段(field)--> 对象的属性(attribute)

举例来说,下面是一行 SQL 语句。
SELECT id, first_name, last_name, phone, birth_date, sex FROM persons WHERE id = 10
程序直接运行 SQL,操作数据库的写法如下。
res = db.execSql(sql); name = res[0]["FIRST_NAME"];
改成 ORM 的写法如下。
p = Person.get(10); name = p.first_name;
一比较就可以发现,ORM 使用对象,封装了数据库操作,因此可以不碰 SQL 语言。开发者只使用面向对象编程,与数据对象直接交互,不用关心底层数据库。
总结起来,ORM 有下面这些优点。
- 数据模型都在一个地方定义,更容易更新和维护,也利于重用代码。
- ORM 有现成的工具,很多功能都可以自动完成,比如数据消毒、预处理、事务等等。
- 它迫使你使用 MVC 架构,ORM 就是天然的 Model,最终使代码更清晰。
- 基于 ORM 的业务代码比较简单,代码量少,语义性好,容易理解。
- 你不必编写性能不佳的 SQL。
但是,ORM 也有很突出的缺点。
- ORM 库不是轻量级工具,需要花很多精力学习和设置。
- 对于复杂的查询,ORM 要么是无法表达,要么是性能不如原生的 SQL。
- ORM 抽象掉了数据库层,开发者无法了解底层的数据库操作,也无法定制一些特殊的 SQL。
二、命名规定
许多语言都有自己的 ORM 库,最典型、最规范的实现公认是 Ruby 语言的Active Record。Active Record 对于对象和数据库表的映射,有一些命名限制。
(1)一个类对应一张表。类名是单数,且首字母大写;表名是复数,且全部是小写。比如,表books对应类Book。
(2)如果名字是不规则复数,则类名依照英语习惯命名,比如,表mice对应类Mouse,表people对应类Person。
(3)如果名字包含多个单词,那么类名使用首字母全部大写的骆驼拼写法,而表名使用下划线分隔的小写单词。比如,表book_clubs对应类BookClub,表line_items对应类LineItem。
(4)每个表都必须有一个主键字段,通常是叫做id的整数字段。外键字段名约定为单数的表名 + 下划线 + id,比如item_id表示该字段对应items表的id字段。
三、示例库
下面使用OpenRecord这个库,演示如何使用 ORM。
OpenRecord 是仿 Active Record 的,将其移植到了 JavaScript,而且实现得很轻量级,学习成本较低。我写了一个示例库,请将它克隆到本地。
$ git clone https://github.com/ruanyf/openrecord-demos.git
然后,安装依赖。
$ cd openrecord-demos $ npm install
示例库里面的数据库,是从网上拷贝的 Sqlite 数据库。它的 Schema 图如下(PDF大图下载)。

四、连接数据库
使用 ORM 的第一步,就是你必须告诉它,怎么连接数据库(完整代码看这里)。...
|-转 Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结
Mysql中utf8_general_ci与utf8_unicode_ci有什么区别呢?在编程语言中,通常用unicode对中文字符做处理,防止出现乱码,那么在MySQL里,为什么大家都使用utf8_general_ci而不是utf8_unicode_ci呢?
用了这么长时间,发现自己竟然不知道utf_bin和utf_general_ci这两者到底有什么区别。。 ci是 case insensitive, 即 "大小写不敏感", a 和 A 会在字符判断中会被当做一样的; bin 是二进制, a 和 A 会别区别对待. 例如你运行: SELECT * FROM table WHERE txt = a 那么在utf8_bin中你就找不到 txt = A 的那一行, 而 utf8_general_ci 则可以. utf8_general_ci 不区分大小写,这个你在注册用户名和邮箱的时候就要使用。 utf8_general_cs 区分大小写,如果用户名和邮箱用这个 就会照成不良后果 utf8_bin:字符串每个字符串用二进制数据编译存储。 区分大小写,而且可以存二进制的内容
一、官方文档说明 下面摘录一下Mysql 5.1中文手册中关于utf8_unicode_ci与utf8_general_ci的说明:
- 当前,utf8_unicode_ci校对规则仅部分支持Unicode校对规则算法。一些字符还是不能支持。并且,不能完全支持组合的记号。这主要影响越南和俄罗斯的一些少数民族语言,如:Udmurt 、Tatar、Bashkir和Mari。
- utf8_unicode_ci的最主要的特色是支持扩展,即当把一个字母看作与其它字母组合相等时。例如,在德语和一些其它语言中‘ß等于‘ss。
- utf8_general_ci是一个遗留的 校对规则,不支持扩展。它仅能够在字符之间进行逐个比较。这意味着utf8_general_ci校对规则进行的比较速度很快,但是与使用utf8_unicode_ci的 校对规则相比,比较正确性较差)。
- 例如,使用utf8_general_ci和utf8_unicode_ci两种 校对规则下面的比较相等:
- Ä = A
- Ö = O
- Ü = U
- 两种校对规则之间的区别是,对于utf8_general_ci下面的等式成立:
- ß = s
- 但是,对于utf8_unicode_ci下面等式成立:
- ß = ss
- 对于一种语言仅当使用utf8_unicode_ci排序做的不好时,才执行与具体语言相关的utf8字符集 校对规则。例如,对于德语和法语,utf8_unicode_ci工作的很好,因此不再需要为这两种语言创建特殊的utf8校对规则。
- utf8_general_ci也适用与德语和法语,除了‘ß等于‘s,而不是‘ss之外。如果你的应用能够接受这些,那么应该使用utf8_general_ci,因为它速度快。否则,使用utf8_unicode_ci,因为它比较准确。
如果你想使用gb2312编码,那么建议你使用latin1作为数据表的默认字符集,这样就能直接用中文在命令行工具中插入数据,并且可以直接显示出来.而不要使用gb2312或者gbk等字符集,如果担心查询排序等问题,可以使用binary属性约束,例如:
create table my_table ( name varchar(20) binary not null default )type=myisam default charset latin1;
二、简短总结 utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。 utf8_general_ci校对速度快,但准确度稍差。 utf8_unicode_ci准确度高,但校对速度稍慢。
如果你的应用有德语、法语或者俄语,请一定使用utf8_unicode_ci。一般用utf8_general_ci就够了,到现在也没发现问题。。。 ...
|-转 MySQL 中 datetime 和 timestamp 的区别与选择
发布于2019-11-20 22:34:36
MySQL 中常用的两种时间储存类型分别是datetime和 timestamp。如何在它们之间选择是建表时必要的考虑。下面就谈谈他们的区别和怎么选择。
1 区别
1.1 占用空间
类型 | 占据字节 | 表示形式 |
|---|---|---|
datetime | 8 字节 | yyyy-mm-dd hh:mm:ss |
timestamp | 4 字节 | yyyy-mm-dd hh:mm:ss |
1.2 表示范围
类型 | 表示范围 |
|---|---|
datetime | '1000-01-01 00:00:00.000000' to '9999-12-31 23:59:59.999999' |
timestamp | '1970-01-01 00:00:01.000000' to '2038-01-19 03:14:07.999999' |
timestamp翻译为汉语即"时间戳",它是当前时间到 Unix元年(1970 年 1 月 1 日 0 时 0 分 0 秒)的秒数。对于某些时间的计算,如果是以 datetime 的形式会比较困难,假如我是 1994-1-20 06:06:06 出生,现在的时间是 2016-10-1 20:04:50 ,那么要计算我活了多少秒钟用 datetime 还需要函数进行转换,但是 timestamp 直接相减就行。...
|-转 Invalid default value for ‘updated_at‘
NO_ZERO_IN_DATE,NO_ZERO_DATE
最近在Mysql的query语句中出现了这样的错误
Invalid default value for ‘updated_at’
解决方法如下:
执行SQL语句:show variables like 'sql_mode';
如何发现query结果中有如下两个modes:NO_ZERO_IN_DATE和NO_ZERO_DATE
在/etc/my.conf 中sql_mode去掉上面那个两个,重启mysql即可!...
|-转 设置MySQL的group_concat_max_len长度为最大值
group_concat_max_len=10240000
group_concat有长度限制!
所以在项目中,最好先将sql中的group_concat_max_len设置为最大值。
一、查看mysql的group_concat_max_len
打开sql,输入密码之后,输入下面代码
show variables like 'group_concat_max_len';
1
【默认是1024的】
二、永久修改(建议)
修改配置文件:my.ini
一般在MySQL文件下面的这个路径内。
在上述配置文件设置group_concat_max_len=4294967295
打开【my.ini】,然后找到【mysqld】,在下面添加一行代码
group_concat_max_len=4294967295
1
重启MySQL之后可以按照(一)种的方式进行检查
重启MySQL可以参照(四)
三、临时修改(不建议)
这种方式在MySQL重启之后会实效。(因为配置文件没有改啦)
SET GLOBAL group_concat_max_len = 102400;
SET SESSION group_concat_max_len = 102400;
1
2
将上面的代码粘贴在sql中,即可。使用(一)中介绍的方式查看一下是否修改完成。【在MySQL中没有ctrl+V,鼠标右击即为复制】...
|-转 MySQL中concat()、concat_ws()、group_concat()函数使用技巧与心得
作者:极客小俊一个专注于web技术的80后
我不用拼过聪明人,我只需要拼过那些懒人 我就一定会超越大部分人!
知乎@极客小俊,官方首发原创文章
Bilibili:极客小俊GeekerJun
前言
GROUP_CONCAT()函数在MySQL到底起什么作用呢 ?有些小伙伴还觉得它很神秘其实不然,今天就来讲讲这个函数的实际操作以及相关案例、我将从concat()函数 --- concat_ws()函数----到最后的group_concat()函数逐一讲解! 让小伙伴摸清楚其使用方法 !
首先我们来建立一个测试的表和数据,代码如下
CREATE TABLE `per` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`pname` varchar(50) DEFAULT NULL,
`page` int(11) DEFAULT NULL,
`psex` varchar(50) DEFAULT NULL,
`paddr` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4;
INSERT INTO `per` VALUES ('1', '王小华', '30', '男', '北京');
INSERT INTO `per` VALUES ('2', '张文军', '24', '男', '上海');
INSERT INTO `per` VALUES ('3', '罗敏', '19', '女', '重庆');
INSERT INTO `per` VALUES ('4', '张建新', '32', '男', '重庆');
INSERT INTO `per` VALUES ('5', '刘婷', '26', '女', '成都');
INSERT INTO `per` VALUES ('6', '刘小亚', '22', '女', '重庆');
INSERT INTO `per` VALUES ('7', '王建军', '22', '男', '贵州');
INSERT INTO `per` VALUES ('8', '谢涛', '28', '男', '海南');
INSERT INTO `per` VALUES ('9', '张良', '26', '男', '上海');
INSERT INTO `per` VALUES ('10', '黎记', '17', '男', '贵阳');
INSERT INTO `per` VALUES ('11', '赵小丽', '26', '女', '上海');
INSERT INTO `per` VALUES ('12', '张三', null, '女', '北京');concat()函数
首先我们先学一个函数叫concat()函数, 这个函数非常简单...
|-转 mysql的left join和inner join的效率对比,以及如何优化
关于left join的概念,大家是都知道的(返回左边全部记录,右表不满足匹配条件的记录对应行返回null),那么单纯的对比逻辑运算量的话,inner join 是只需要返回两个表的交集部分,left join多返回了一部分左表没有返回的数据。
mysql的left join和inner join的效率对比,以及如何优化_内连接和左连接效率-CSDN博客
一、前言
最近在写代码的时候,遇到了需要多表连接的一个问题,初始sql类似于:
select * from a left join b on a.x = b.x left join c on c.y = b.y left join d on d.z=c.z
- 1
这样的多个left join组合,一方面是心里有点不舒服,总觉得这种写法是有问题的,一方面有有点好奇,直接用inner join会怎样呢?差别在哪里?后续使用inner join发现速度要比left join快一些,所以这边就研究一下这个问题。
二、left join为什么会比 inner join 慢
1、关于逻辑运算量
关于left join的概念,大家是都知道的(返回左边全部记录,右表不满足匹配条件的记录对应行返回null),那么单纯的对比逻辑运算量的话,inner join 是只需要返回两个表的交集部分,left join多返回了一部分左表没有返回的数据。
2、关于mysql连接的算法 Nest Loop Join(嵌套联接循环)
这个算法是mysql默认的连接算法,类似于我们php程序的三个嵌套循环:
(foreach a as v){
(foreach b as v1){
(foreach c as v2){
}
}
}
从算法上来看,根据mysql文档,inner join在连接的时候,mysql会自动选择较小的表来作为驱动表,从而达到减少循环次数的目的。我们在使用left join表的时候,默认是使用左表作为驱动表,那么此时左表的大小是我们来控制的,如果控制不当,左表比较大,那么自然循环次数也会变多,效率会下降。
根据这两方面的对比,left join明显被秒成渣,但是我们的实际业务却经常需要使用left join,一切还是要以实际业务为主,所以大家还是仁者见仁智者见智的选择吧。博主这里因为业务并不是很需要left join,所以果断选择使用inner join来连接表。...
|-转 mysql 索引优化十例
字符串不加单引号索引失效
另外mysql 的EXPLAIN太好用了
在 MySQL 中可以通过 explain 关键字模拟优化器执行 SQL语句,从而知道 MySQL 是如何处理 SQL 语句的。

字符串不加单引号索引失效
实际用的时候学到了
参考自:MySQL优化之explain详解_explain type all-CSDN博客...
|-转 MySQL数据表中有自增长主键时如何插入数据
MySQL数据库表中有自增主键ID,当用SQL插入语句中插入语句带有ID列值记录的时候;
如果指定了该列的值,则新插入的值不能和已有的值重复,而且必须大于其中最大的一个值;
也可以不指定该列的值,只将其他列的值插入,让ID还是按照MySQL自增自己填;
具体:
1.创建数据库
create table if not exists userInfo (
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(50) NOT NULL,
password varchar(50) NOT NULL
);
2.插入数据记录
insert into userInfo values(1,'aaa','1212');
当数据表中有自增长主键时,当用SQL插入语句中插入语句带有ID列值记录的时候;
如果指定了该列的值,则新插入的值不能和已有的值重复,而且必须大于其中最大的一个值;
也可以不指定该列的值,只将其他列的值插入,让ID还是按照MySQL自增自己填;...
|-转 mysqldump按条件导出mysql数据库数据
mysqldump -u user -h host -p --where="corp_code='5069991470' \
and deal_time<='2021-09-27 23:59:59' and deal_time>='2021-09-27 00:00:00' " \
--databases db --tables box_bill --skip-extended-insert > bill_20210927.sql
mysqldump -uroot -p123456 --where="trade_time>=1721318400" --databases shares --tables s_d_shanghai --skip-extended-insert --skip-add-drop-table > /mydata/s_d_shanghai_20240728.sql
导出指定的表种指定条件的数据
mysqldump -u user -h host -p --where="corp_code='5069991470' \
and deal_time<='2021-09-27 23:59:59' and deal_time>='2021-09-27 00:00:00' " \
--databases db --tables box_bill --skip-extended-insert > bill_20210927.sql
\字符做换行处理,不支持的情况下,需要删除。
说明:
-u, mysql用户名
-h,mysql主机名或ip地址
-p,需要输入密码
-t或者--no-create-info:只导数据,不导创建表语句
--where:条件
--replace:使用REPLACE INTO 取代INSERT INTO
参数大全:
--all-databases , -A
导出全部数据库。
mysqldump -uroot -p --all-databases
--add-drop-database
每个数据库创建之前添加drop数据库语句。
mysqldump -uroot -p --all-databases --add-drop-database
--add-drop-table
每个数据表创建之前添加drop数据表语句。(默认为打开状态,使用--skip-add-drop-table取消选项)
mysqldump -uroot -p --all-databases (默认添加drop语句)
mysqldump -uroot -p --all-databases –skip-add-drop-table (取消drop语句)
--add-locks
在每个表导出之前增加LOCK TABLES并且之后UNLOCK TABLE。(默认为打开状态,使用--skip-add-locks取消选项)
mysqldump -uroot -p --all-databases (默认添加LOCK语句)
mysqldump -uroot -p --all-databases –skip-add-locks (取消LOCK语句)
--allow-keywords
允许创建是关键词的列名字。这由表名前缀于每个列名做到。
mysqldump -uroot -p --all-databases --allow-keywords
--compatible
导出的数据将和其它数据库或旧版本的MySQL 相兼容。值可以为ansi、mysql323、mysql40、postgresql、 oracle、mssql、db2、maxdb、no_key_options、no_tables_options、no_field_options 等,
要使用几个值,用逗号将它们隔开。它并不保证能完全兼容,而是尽量兼容。
mysqldump -uroot -p --all-databases --compatible=ansi
--complete-insert, -c
使用完整的insert语句(包含列名称)。这么做能提高插入效率,但是可能会受到max_allowed_packet参数的影响而导致插入失败。
mysqldump -uroot -p --all-databases --complete-insert
--databases, -B
导出几个数据库。参数后面所有名字参量都被看作数据库名。
mysqldump -uroot -p --databases test mysql
--debug
输出debug信息,用于调试。默认值为:d:t:o,/tmp/mysqldump.trace
mysqldump -uroot -p --all-databases --debug
mysqldump -uroot -p --all-databases --debug=” d:t:o,/tmp/debug.trace”
--debug-info
输出调试信息并退出
mysqldump -uroot -p --all-databases --debug-info
--default-character-set
设置默认字符集,默认值为utf8
mysqldump -uroot -p --all-databases --default-character-set=latin1
--disable-keys
对于每个表,用/*!40000 ALTER TABLE tbl_name DISABLE KEYS */;和 /*!40000 ALTER TABLE tbl_name ENABLE KEYS */;语句引用INSERT语句。这样可以更快地导入dump出 来的文件,因为它是在插入所有行后创建索引的。该选项只适合MyISAM表,默认为打开状态。
mysqldump -uroot -p --all-databases
--extended-insert, -e
使用具有多个VALUES列的INSERT语法。这样使导出文件更小,并加速导入时的速度。默认为打开状态,使用--skip-extended-insert取消选项。
mysqldump -uroot -p --all-databases
mysqldump -uroot -p --all-databases--skip-extended-insert (取消选项)
--fields-terminated-by
导出文件中忽略给定字段。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p test test --tab=”/home/mysql” --fields-terminated-by=”#”
--fields-enclosed-by
输出文件中的各个字段用给定字符包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p test test --tab=”/home/mysql” --fields-enclosed-by=”#”
--fields-optionally-enclosed-by
输出文件中的各个字段用给定字符选择性包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p test test --tab=”/home/mysql” --fields-enclosed-by=”#” --fields-optionally-enclosed-by =”#”
--fields-escaped-by
输出文件中的各个字段忽略给定字符。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p mysql user --tab=”/home/mysql” --fields-escaped-by=”#”
--flush-logs
开始导出之前刷新日志。
请注意:假如一次导出多个数据库(使用选项--databases或者--all-databases),将会逐个数据库刷新日志。除使用 --lock-all-tables或者--master-data外。在这种情况下,日志将会被刷新一次,相应的所以表同时被锁定。因此,如果打算同时 导出和刷新日志应该使用--lock-all-tables 或者--master-data 和--flush-logs。...
